SQLServer
离线同步任务支持SQLServer,支持该数据源的抽取(Reader)和导入(Writer)。
使用前提
在使用之前需要在“项目配置-项目中心(新)-数据源管理”完成该类型数据源的登记并测试通过(可在控制台的用户手册中查看具体登记详情信息),以及获取该数据源类型或数据的读权限(配置入口在安全中心-项目下的具体成员或角色)。
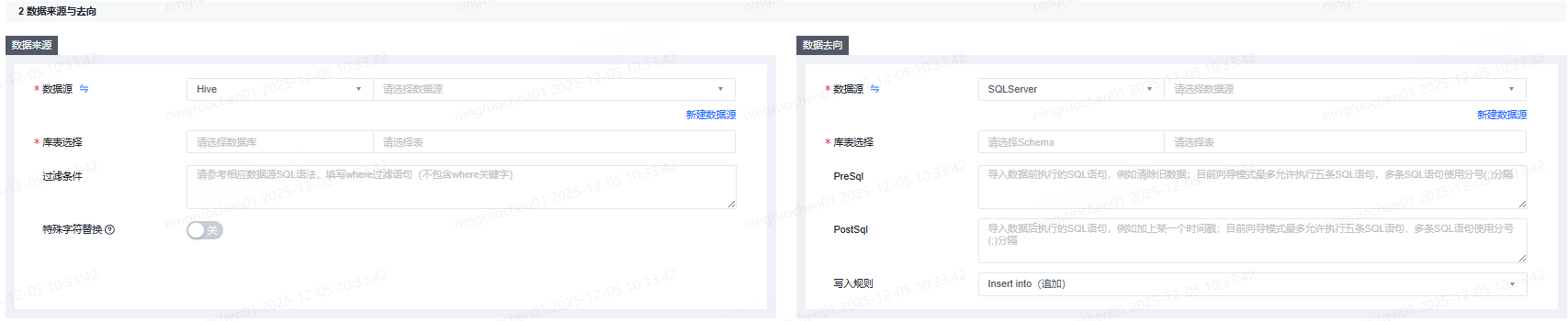
SQLServer作为数据来源
以SQLServer to Hive为例,在数据来源端选择SQLServer数据源类型及数据源名称,选择需要进行读取的schema和表。
SQLServer数据源支持库表选择和正则匹配。
- 库表选择:支持搜索或直接选择数据库表。支持跨库表配置,跨库表必须是相同数据源类型。
- 正则匹配:支持通过正则表达式来匹配数据表。
SQLServer数据源支持全量初始化:
- 全量初始化开关开启时,任务提交上线后首次调度时会忽略数据过滤条件,进行全量同步。
- 全量初始化开关开启时,如果任务重新提交上线,则重新提交上线后的首次调度仍会进行全量同步。
- 如果多个数据同步节点引用同一离线同步任务,则每个节点提交上线后的首次调度执行全量初始化操作。
数据过滤支持条件、流水型及自定义。
- 条件型:按列设置过滤规则,可添加一或多组条件,条件默认为AND关系。
- 流水型:从选择字段的起始值开始读取数据,读取到最新记录位置,下次从上次的最新记录读取至当前的最新记录。流水型数据过滤方式生效满足以下条件:1. 选取的字段是单调递增的;2. 离线开发任务提交到线上调度执行。
- 自定义:填写where过滤语句(不含where关键字),通常用作增量同步,支持系统参数和参数组参数。
特殊字符替换、并发读取根据实际情况进行填写。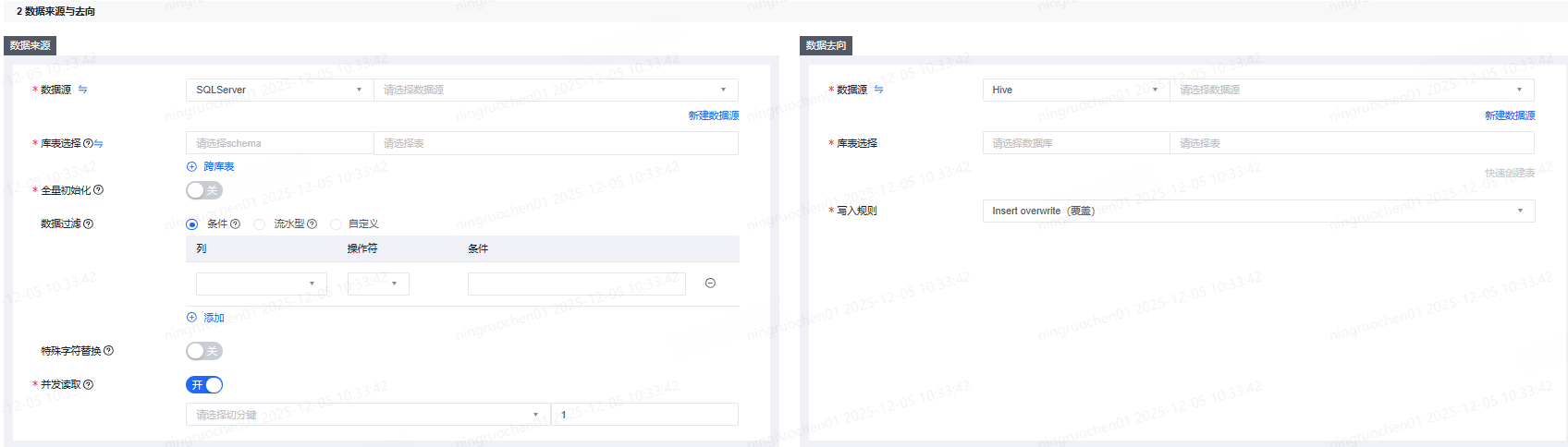
需要注意的是支持数据来源为SQLServer时,数据过滤-流水型支持选用timestamp字段作为增量标识字段。SQLServer的timestamp是二进制类型,起始值填写该二进制对应的十进制数即可,可通过CONVERT(BIGINT, ${timestamp_column_name})获取该整数,如下: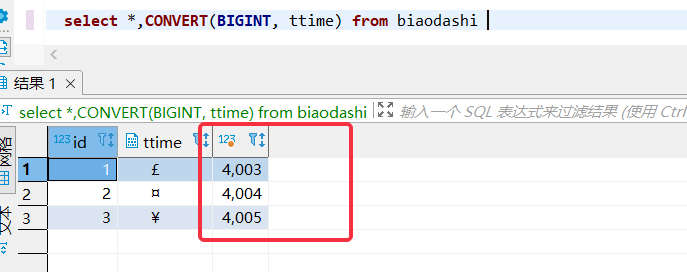
SQLServer作为逻辑数据源
SQLServer支持按照逻辑数据源模式匹配库表,用于同构异ip数据源批量抽取。配置步骤如下:
第一步,在数据来源中将数据源切换成逻辑数据源。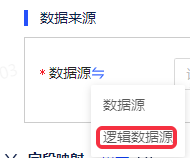
第二步,选择数据源类型及逻辑数据源,在库名和表名中分别填写通配符进行匹配。
第三步,点击解析,查看匹配结果。完成数据来源为逻辑数据源的配置步骤。
关于通配符:
- 通配符"_":表示任意单个字符
- 通配符"%":能匹配0个或更多字符的任意长度的字符串
- 通配符"[]":[]用于指定一定范围内的任何单个字符,包括两端数据,比如指定范围([a-f])
- 通配符"[^]":用来查询不属于指定范围,[^abc]表示不包含字符a,b,c
SQLServer作为数据去向
以Hive to SQLServer为例,当SQLServer作为数据去向时,除了需要填写数据源类型、数据源等基础信息之外,还可以填写PreSql和PostSql。
- PreSql:执行数据同步任务之前率先执行的SQL语句;目前向导模式仅允许执行一条SQL语句,例如清除旧数据。
- PostSql:执行数据同步任务之后执行的SQL语句;目前向导模式仅允许执行一条SQL语句,例如加上某一个时间戳。
SQLServer当前支持INSERT INTO(追加)、Merge into(遇更新键冲突,更新原记录)写入规则。