MySQL
更新时间: 2025-12-12 19:08:32
离线同步任务支持MySQL,支持该数据源的抽取(Reader)和导入(Writer)。
使用前提
在使用之前需要在“项目配置-项目中心(新)-数据源管理”完成该类型数据源的登记并测试通过(可在控制台的用户手册中查看具体登记详情信息),以及获取该数据源类型或数据的读权限(配置入口在安全中心-项目下的具体成员或角色)。
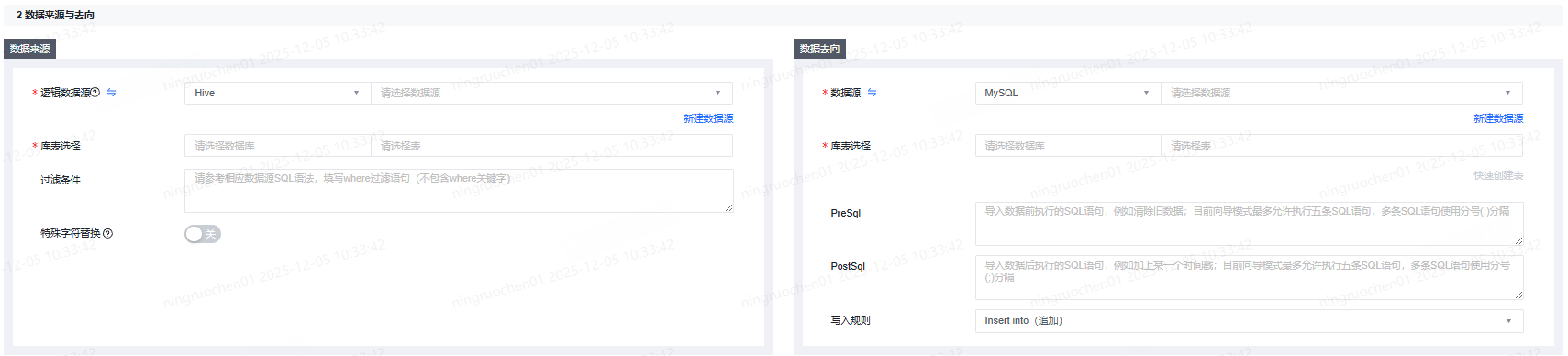
MySQL作为数据来源
以MySQL to Hive为例,在数据来源端选择MySQL数据源类型及数据源名称,选择需要进行读取的schema和表。
MySQL数据源支持库表选择和正则匹配。
- 库表选择:支持搜索或直接选择数据库表。支持跨库表配置,跨库表必须是相同数据源类型。
- 正则匹配:支持通过正则表达式来匹配数据表。
MySQL数据源支持全量初始化:
- 全量初始化开关开启时,任务提交上线后首次调度时会忽略数据过滤条件,进行全量同步。
- 全量初始化开关开启时,如果任务重新提交上线,则重新提交上线后的首次调度仍会进行全量同步。
- 如果多个数据同步节点引用同一离线同步任务,则每个节点提交上线后的首次调度执行全量初始化操作。
数据过滤支持条件、流水型及自定义。
- 条件型:按列设置过滤规则,可添加一或多组条件,条件默认为AND关系。
- 流水型:从选择字段的起始值开始读取数据,读取到最新记录位置,下次从上次的最新记录读取至当前的最新记录。流水型数据过滤方式生效满足以下条件:1. 选取的字段是单调递增的;2. 离线开发任务提交到线上调度执行。
- 自定义:填写where过滤语句(不含where关键字),通常用作增量同步,支持系统参数和参数组参数。
特殊字符替换、并发读取根据实际情况进行填写。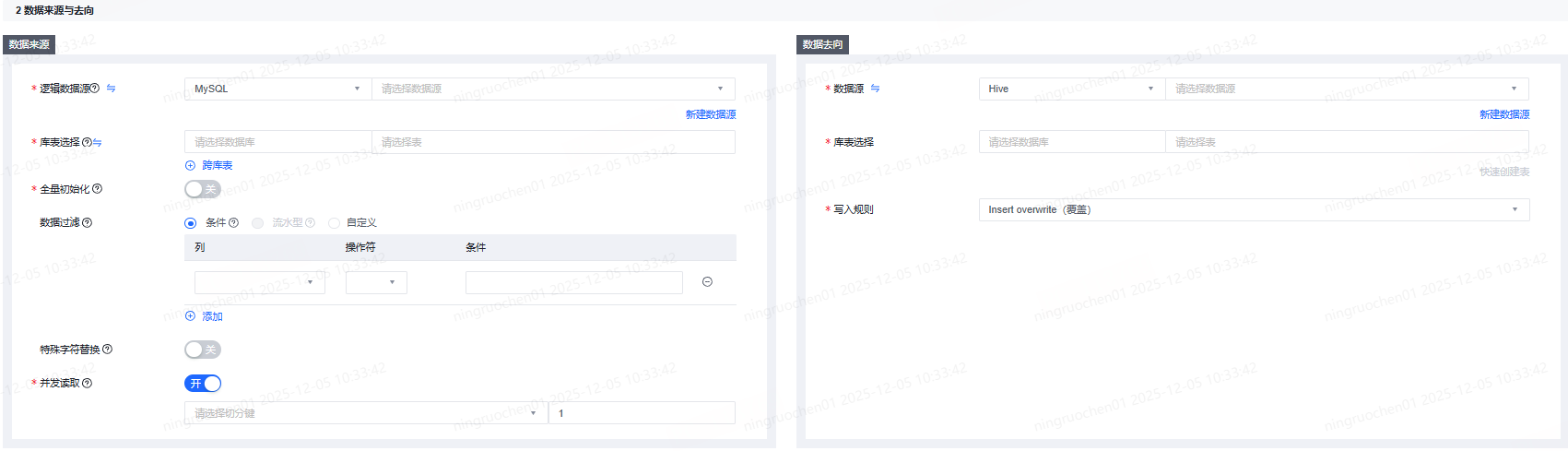
MySQL作为逻辑数据源
MySQL支持按照逻辑数据源模式匹配库表,用于同构异ip数据源批量抽取。配置步骤如下:
第一步,在数据来源中将数据源切换成逻辑数据源。
第二步,选择数据源类型及逻辑数据源,在库名和表名中分别填写正则表达式进行匹配。
第三步,点击解析,查看匹配结果。完成数据来源为逻辑数据源的配置步骤。
MySQL作为数据去向
以Hive to MySQL为例,当MySQL作为数据去向时,除了需要填写数据源类型、数据源等基础信息之外,还可以填写PreSql和PostSql。
- PreSql:执行数据同步任务之前率先执行的SQL语句;目前向导模式仅允许执行一条SQL语句,例如清除旧数据。
- PostSql:执行数据同步任务之后执行的SQL语句;目前向导模式仅允许执行一条SQL语句,例如加上某一个时间戳。
MySQL支持INSERT INTO、ON DUPLICATE KEY UPDATE、REPLACE INTO、INSERT IGNORE写入规则:
- INSERT INTO:插入数据。
- ON DUPLICATE KEY UPDATE:当主键、唯一索引冲突时,更新原记录,未映射字段值不变。
- REPLACE INTO:当主键、唯一索引冲突时,删除原记录,插入新纪录。
- INSERT IGNORE:如果目标表中已经存在相同的记录,则忽略当前的新数据。
流量控制可根据实际情况进行填写。