StarRocks
更新时间: 2025-12-12 21:49:25
离线同步任务支持StarRocks数据源,支持该数据源的抽取(Reader)和导入(Writer)。
使用前提
在使用之前需要在“项目配置-项目中心(新)-数据源管理”完成该类型数据源的登记并测试通过(可在控制台的用户手册中查看具体登记详情信息),以及获取该数据源类型或数据的读权限(配置入口在安全中心-项目下的具体成员或角色)。
StarRocks作为数据来源
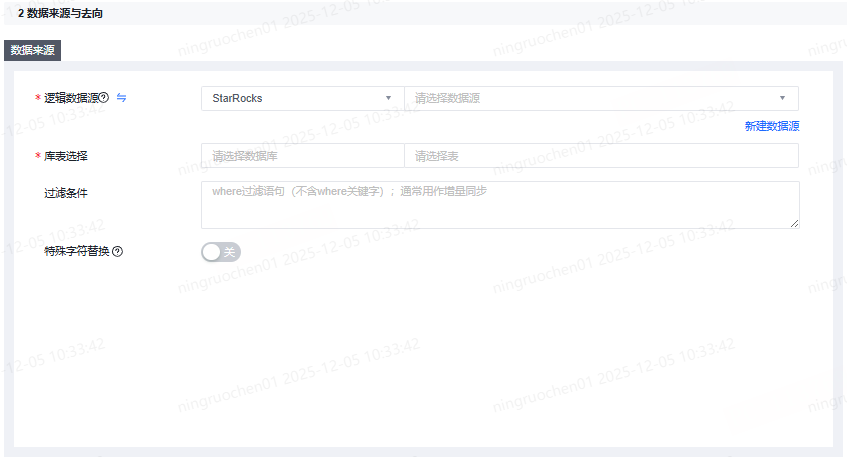
以StarRocks to Hive为例,在数据来源端选择StarRocks数据源类型及数据源名称,选择需要进行读取的schema和表。过滤条件支持填写where过滤语句(不含where关键字),通常用作增量同步,支持系统参数和参数组参数。特殊字符替换根据实际情况进行填写。
StarRocks作为数据去向
当StarRocks作为数据去向时,需要配置如下: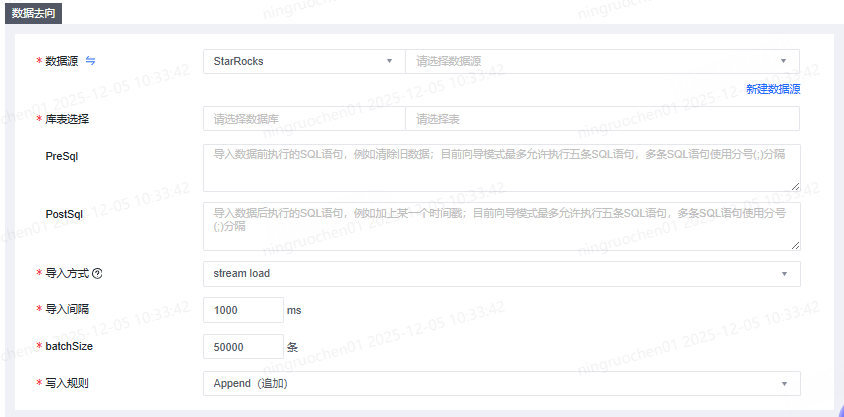
- 数据源:选择StarRocks和已经登记的StarRocks数据源
- 库表选择:选择需要导入的schema和表
- PreSql:导入数据前执行的SQL语句,例如清除旧数据;目前向导模式仅允许执行五条SQL语句,多条SQL语句通过“;”分隔,最大长度为2000个字符
- PostSql:导入数据后执行的SQL语句,例如加上某一个时间戳;目前向导模式仅允许执行五条SQL语句,多条SQL语句通过“;”分隔,最大长度为2000个字符
- 导入方式:当前只支持stream load
- 导入间隔:默认为0ms,根据实际情况填写
- batcchSize:默认为50000条,根据实际情况填写
- 写入规则:当前只支持Insert into(追加)
Hive to StarRocks场景支持复杂类型转换,当数据来源端字段类型为:map、array类型时,支持转为json写入去向端。

读取数据时,数据来源端字段类型为map、array时,默认转为json格式的字符串。写入数据时,stream load导入方式下支持使用csv或json的序列化格式写入数据,默认序列化格式为csv。如果需要用json格式,则需要在高级配置的任务参数中自定义参数target.loadFormat:json。