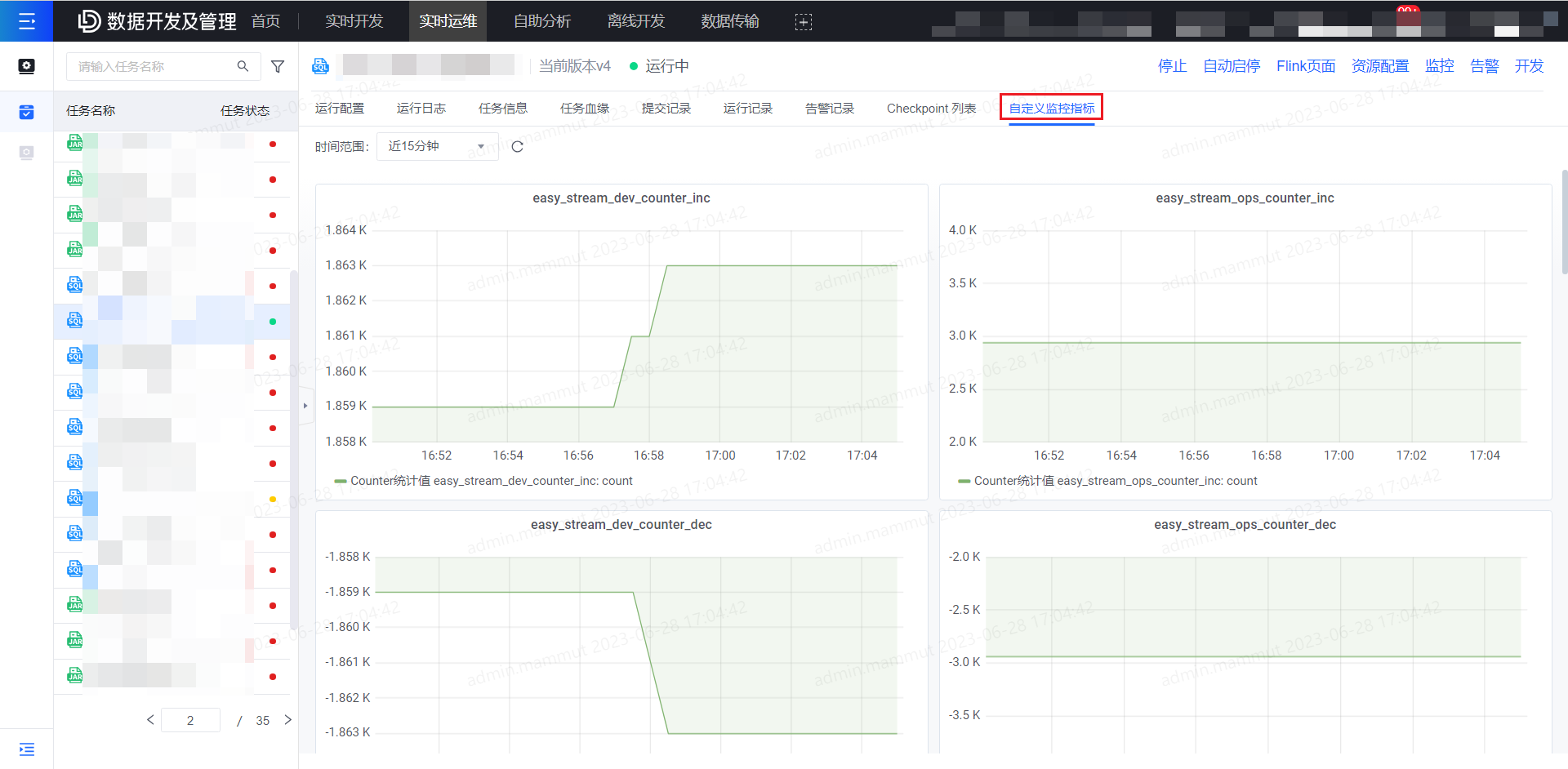
自定义监控指标
本文为您介绍 EasyStream 平台中添加和查看任务自定义监控指标的限制说明和操作步骤。
在目前的实时开发场景中,管道式开发情况较常见,源端数据通过一个实时任务加工后直接写入ADS层或DWD层提供下游业务使用。在此场景中,用户仅能监控任务运行情况,并通过目标端结果监控业务指标,但无法监控数据加工过程中的指标变化情况,且若过程中出现异常数据无法感知和排查。任务自定义监控指标功能可以解决用户在这个场景中的痛点,由用户自行指定任意任务中涉及的指标的监控,在运维页面内即可轻松查看指标变化曲线。后续平台还将提供自定义监控指标告警功能。
使用限制:
- 单个任务最多支持上报20个自定义监控指标。
- 支持 Counter、Gauge、Meter、Histogram 四类指标上报。
配置方式:
指标说明:
Counter:可理解为计数器,提供inc(Long value)、dec(Long value)方法。如 Failover次数、checkpoint失败次数等。
Gauge:仅记录一个数值,提供setValue(Long value)、setValue(Double value)方法。
Meter:Flink对meter类指标,比如QPS、TPS等实现了平缓计算速率的机制。
通过UDF调用Meter的markEvent()和markEvent(Long n)方法,实际是让Meter内置的Counter执行inc()逻辑。
设过去60s counter的新增值为∆count,则Flink上报的rate值为: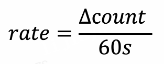
Histogram: Histogram可以理解为以一组long[]为原始数据,对其求最值、均值、百分位值(p50、p75、p95、p99等等),并输出。 此处使用了官方推荐的实现方法 Metrics | Apache Flink#histogram ,用户只需调用Histogram的update(Long value)向数组内添加新值即可,数组采用滑动窗口,默认size为500。
SQL任务配置:
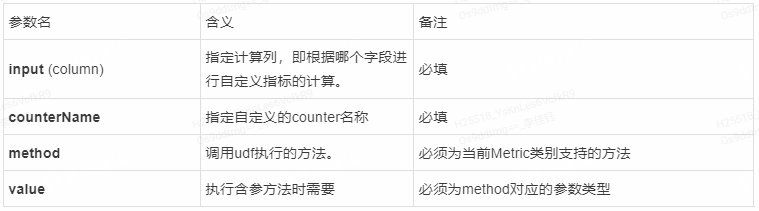
平台已将支持上报的四类指标所需函数作为平台公共函数置入 UDF Studio 的系统函数中。当用户需要在 SQL 任务中上报自定义监控指标时,根据对应函数的使用方式在 SQL 代码中引用函数上报需要监控的指标。系统函数的入参如下:

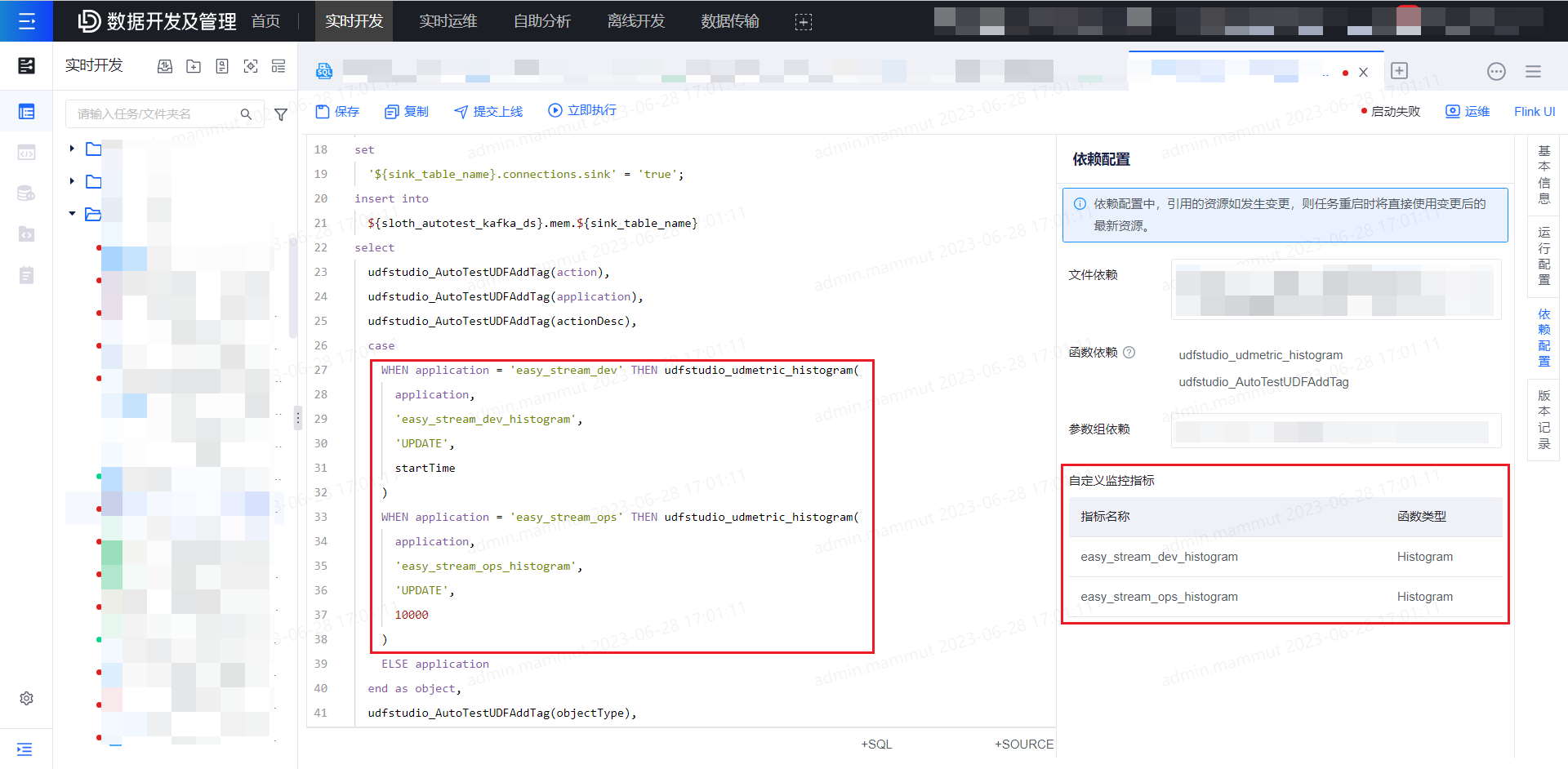
用户保存 SQL 代码后,平台将自动解析和获取任务中使用的自定义监控指标名称和函数类型,展示在任务的依赖配置中,用户可进行确认。确认无误后将任务提交上线并运行,指标将开始采集。
SQL任务示例:
一、 Counter类自定义监控指标示例
以下是一个基于商品零售场景的Kafka和MySQL的Flink SQL示例,该示例表示从Kafka 中读取零售数据,对数据进行简单的处理,然后将处理后的数据写入到 MySQL中,假设kafka中有一个名为sales的Topic,其包含以下JSON格式的消息:
{
"order_id": 123,
"order_time": "2022-01-01 10:00:00",
"product_id": "p001",
"product_name": "product A",
"product_price": 10.0,
"quantity": 2
}SQL语句示例如下:
-- 创建 Kafka 数据源表
CREATE TABLE kafka_sales (
order_id INT,
order_time TIMESTAMP(3),
product_id STRING,
product_name STRING,
product_price DECIMAL(10, 2),
quantity INT
) WITH (
'connector' = 'kafka',
'topic' = 'sales',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'flink-sql-sales',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
-- 创建 MySQL 目标表
CREATE TABLE mysql_sales_summary (
product_id STRING PRIMARY KEY,
product_name STRING,
benefit DECIMAL(10, 2)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/sales',
'table-name' = 'sales_summary',
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'root',
'password' = 'password'
);
-- 原SQL语句,将处理后的结果写入到 MySQL 目标表中
INSERT INTO mysql_sales_summary
SELECT
product_id,
product_name,
(product_price * quantity) AS benefit
FROM
kafka_sales;
-- 现在希望对苹果、香蕉的销量进行监控,则可以使用counter类自定义监控指标改造原SQL语句
-- 使用CASE WHEN语句进行改造,并推荐使用AS关键字来为CASE表达式指定别名
INSERT INTO mysql_sales_summary
SELECT
product_id,
CASE
-- 使用系统函数udfstudio_udmetric_counter,创建名为'apple_count'的Flink Counter类自定义监控指标,当product_name='apple'时,该指标数值加1。该函数的输出结果与输入结果,即product_name保持一致,输出格式为String/VARCHAR。
WHEN product_name = 'apple' THEN udfstudio_udmetric_counter(product_name, 'apple_count', 'INC', 1)
-- 创建名为'banana_count'的Flink Counter类自定义监控指标,当product_name='banana'时,该指标数值加5。
WHEN product_name = 'banana' THEN udfstudio_udmetric_counter(product_name, 'banana_count', 'INC', 5)
ELSE product_name
END
AS product_name,
(product_price * quantity) AS benefit
FROM
kafka_sales;二、四种自定义监控指标使用示例
以下是四种自定义监控指标的Flink SQL示例,略去Table创建语句:
INSERT INTO
mysql_sales_summary
SELECT
product_id,
CASE
-- 创建名为'apple_count'的Flink Counter类自定义监控指标,当product_name='apple'时,该指标数值加1。
WHEN product_name = 'apple' THEN udfstudio_udmetric_counter(product_name, 'apple_count', 'INC', 1)
-- 创建名为'apple_meter'的Flink Meter类自定义监控指标,当product_name='apple'时,内置计数器加1,其监控展示结果为最近60s内置计数器增加的速率。
WHEN product_name = 'apple' THEN udfstudio_udmetric_meter(product_name, 'apple_meter', 'MARK_EVENT', 1)
-- 创建名为'milk_gauge'的Flink Gauge类自定义监控指标,当product_name='milk'时,记录本次订单时间。注意,每次进入此方法时,该Gauge数值都会被更新,监控展示结果为Gauge数值每10s上报的点线图
WHEN product_name = 'milk' THEN udfstudio_udmetric_gauge(product_name, 'milk_gauge', 'SET', order_time)
ELSE product_name
END AS product_name,
CASE
-- 创建名为'banana_histogram'的Flink Histogram类自定义监控指标,当product_name='banana'时,将本笔订单的销售数量quntity追加到到Histogram内置的values[]中,values[]默认size为500,Flink定期计算values[]中所有数值的均值、最大值、最小值、方差、百分位值(p50、p95、p99)等并进行上报。
-- 监控展示结果为当前values[]中数据的各项统计值。此外,使用了CAST语法将输出结果进行格式转换。
WHEN product_name = 'banana'
THEN cast(udfstudio_udmetric_histogram((product_price * quantity),'banana_histogram','UPDATE',quantity) as DECIMAL(10, 2))
ELSE (product_price * quantity)
END AS benefit
FROM
kafka_sales;三、字段类型转换示例
如前文所述,系统函数的输出结果与输入字段的数值保持一致,但输出格式为String/VARCHAR,因此对于其他格式,需要使用CAST语法将系统函数的结果进行格式转换,使用方法为CAST(系统函数(字段名,xx,xx,xx) AS 字段类型) AS 字段名 示例如下:
CREATE TABLE source_table (
id INT,
str_col VARCHAR,
str1_col VARCHAR(20),
str2_col STRING,
bool_col BOOLEAN,
tiny_int_col TINYINT,
small_int_col SMALLINT,
int_col INT,
big_int_col BIGINT,
float_col FLOAT,
double_col DOUBLE,
decimal_col DECIMAL(10,2),
date_col DATE,
time_col TIME(0),
timestamp_col TIMESTAMP(3)
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10'
);
create table print_table WITH ('connector' = 'blackhole')
LIKE source_table (EXCLUDING ALL);
insert into print_table
select
cast(udfstudio_udmetric_counter(id, 'id_counter', 'INC', 1) AS INT),
udfstudio_udmetric_counter(str_col, 'str_col_counter', 'INC', 1),
cast(udfstudio_udmetric_counter(str1_col, 'str1_col_counter', 'INC', 1) as VARCHAR(20)),
udfstudio_udmetric_counter(str2_col, 'str2_col_counter', 'INC', 1),
cast(udfstudio_udmetric_counter(bool_col, 'bool_col_counter', 'INC', 1) as BOOLEAN),
cast(udfstudio_udmetric_counter(tiny_int_col, 'tiny_int_col_counter', 'INC', 1) as TINYINT),
cast(udfstudio_udmetric_counter(small_int_col, 'small_int_col_counter', 'INC', 1) as SMALLINT),
cast(udfstudio_udmetric_counter(int_col, 'int_col_counter', 'INC', 1) as INT),
cast(udfstudio_udmetric_counter(big_int_col, 'big_int_col_counter', 'INC', 1) as BIGINT),
cast(udfstudio_udmetric_counter(float_col, 'float_col_counter', 'INC', 1) as FLOAT),
cast(udfstudio_udmetric_counter(double_col, 'double_col_counter', 'INC', 1) as DOUBLE),
cast(udfstudio_udmetric_counter(decimal_col, 'decimal_col_counter', 'INC', 1) as DECIMAL(10,2)),
cast(udfstudio_udmetric_counter(date_col, 'date_col_counter', 'INC', 1) as DATE),
cast(udfstudio_udmetric_counter(time_col, 'time_col_counter', 'INC', 1) as TIME(0)),
cast(udfstudio_udmetric_counter(timestamp_col, 'timestamp_col_counter', 'INC', 1) as TIMESTAMP(3))
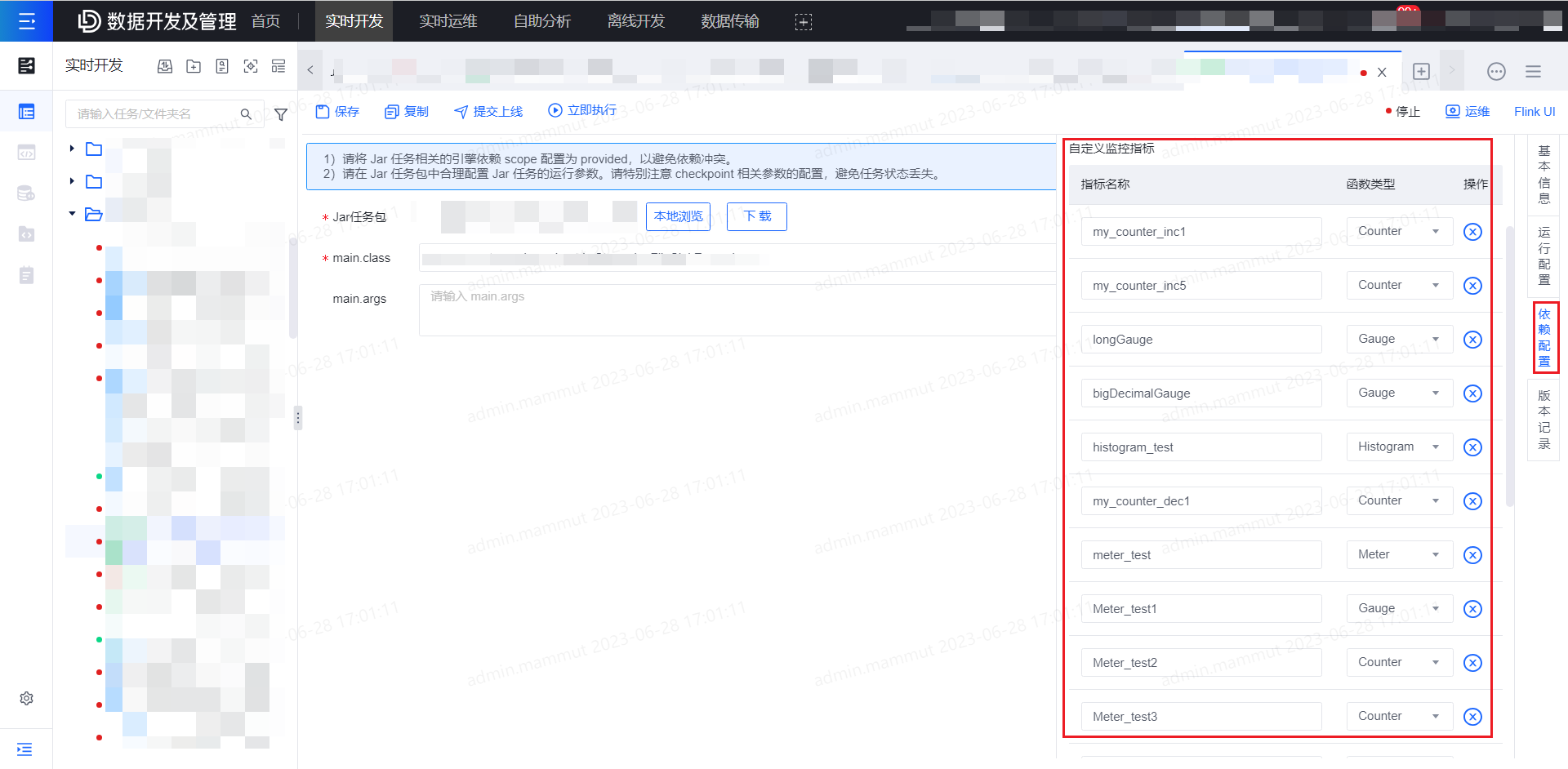
from source_table;Jar任务配置:
- 用户自行在 Jar 任务代码中按平台示例上报自定义指标监控。
- 创建 Jar 任务后,需监控的指标由用户自行在依赖配置-自定义指标监控列表中配置需要上报的自定义监控指标。
JAR任务开发示例:
Flink提供了4种类型的Metrics, Counter, Gauge, Histogram, Meter,详细信息可参阅Flink官网:https://nightlies.apache.org/flink/flink-docs-master/docs/ops/metrics ,在JAR任务中使用自定义监控指标包含以下3个过程:
在静态域中创建Metric对象
// 用户可以自行选择Counter、Gauge等Metric的实现方法,或自定义Metric的实现类 private static Counter count = new SimpleCounter(); private static Gauge gauge = new CustomGauge();在一个RichFunction中的open()函数中注册Metric(注册Metric需要调用getRuntimeContext方法,该方法需要在RichFunction的open()方法中才能获得),并在map方法中实现Metric的业务逻辑。
stream.map(new RichMapFunction<String, String>() { @Override public void open(Configuration parameters) throws Exception { //此处"MetricName"与"UDMetric"必须固定,否则指标监控系统无法过滤识别业务指标。建议在静态域中声明为常量。 getRuntimeContext().getMetricGroup().addGroup("MetricName", "my_count").counter("UDMetric_count", count); getRuntimeContext().getMetricGroup().addGroup("MetricName", "my_gauge").gauge("UDMetric_gauge", gauge); } @Override public String map(String s) throws Exception { gauge.setValue(1L); count.inc(1); return s; } });
这里需要注意的是,getRuntimeContext().getMetricGroup().addGroup("MetricName", "my_count").counter("UDMetric_count", count)中,其中MetricName是用于上报指标时监控系统进行过滤识别业务指标的,该字段不能改动。
而示例中的UDMetric_count和UDMetric_gauge是用于上报指标时标记Metrics类型的,比如使用Counter类指标时,就需要填写为:.counter("UDMetric_count", count),使用Gauge类指标时,就需要填写为:.gauge("UDMetric_gauge", gauge),因此建议在静态域中定义如下常量:
// 请注意大小写保持一致
public static final String UDMETRIC_COUNTER = "UDMetric_counter";
public static final String UDMETRIC_GAUGE = "UDMetric_gauge";
public static final String UDMETRIC_HISTOGRAM = "UDMetric_histogram";
public static final String UDMETRIC_METER = "UDMetric_meter";而my_count、my_gauge是用户定义的指标名称,后续需要在实时开发-任务依赖配置中登记,count是静态域中定义的Metric对象。
- 在实时开发平台创建Jar任务并上传Jar,在实时开发页面右侧依赖配置处,登记在Jar任务中创建的Metric类型及指标名,如示例所示应登记:指标名为
my_count的Counter类指标和指标名为my_gauge的Gauge类指标。
查看自定义监控指标:
当任务配置了自定义监控指标,并已提交上线运行后,在任务运维详情页-自定义监控指标tab页面可查看上报的指标的监控图表。未配置自定义监控指标的任务则不展示此tab。