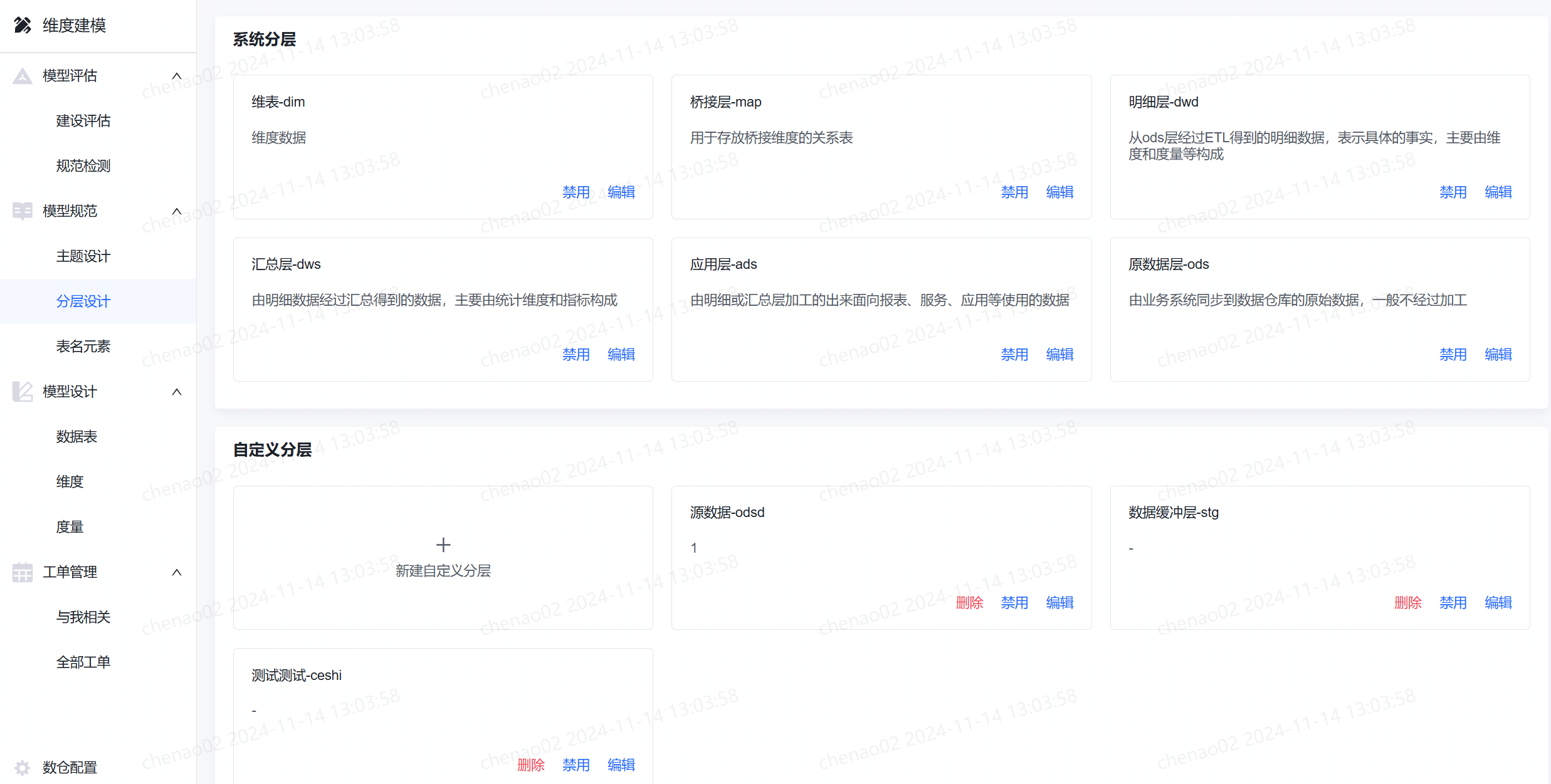
分层设计
分层是对数仓团队的表进行组织管理的另一个维度。对于数仓建设而言,从数据源中接入源头数据后,需要按照一定规则,划分不同的层次来组织承载不同功能和定位的数据表。
目前分层配置共分为两部分:系统预置分层和自定义分层。系统预置了6个分层,分别是ods-原数据层、dwd-明细层、dim-维表、map-桥接层、dws-汇总层以及ads-应用层。
功能介绍
新建自定义分层
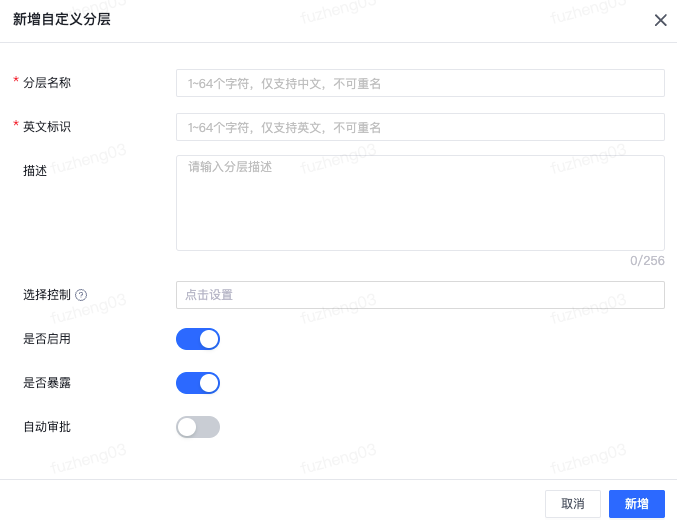
在分层设计页面,点击“新建自定义分层”可进行分层创建的配置。
| 配置项 | 描述 |
|---|---|
| 分层名称 | 1-64个字符,仅支持中文,不可重名。 |
| 英文标识 | 1-64个字符,仅支持英文,不可重名。 |
| 描述 | 分层描述。 |
| 选择控制 | 通过选择设置当前项目组中项目下的角色,能实现在创建建表工单中,只有这些角色中的人员才能选择该分层。该配置一般用于将不同的分层分配给不同的团队或部门维护。如果不设置,则所有人都可以选择。 |
| 是否启用 | 支持启用/禁用设置,禁用后分层呈灰色。 |
| 是否暴露 | 当设置为暴露时,可在数据资产地图-数仓表导引页面查看该分层下的表。 |
| 自动审批 | 项目组负责人、数据团队管理者可设置各层是否自动审批。例如,对dwd层开启自动审批功能,则在创建dwd层表的时候,工单将自动完成审批操作。 |
分层详情
点击分层可进入分层详情页面,在该页面中支持表名规则、表抓取规则、物理化配置的设置。
表名规则
在表名规则设置中,支持按照规则来约束某个分层的命名,支持在规则中添加固定字符串、主题域缩写、二级主题缩写、字典集以及正则表达式作为表名称的前后缀。单击设置或编辑可对表名规则进行设置。
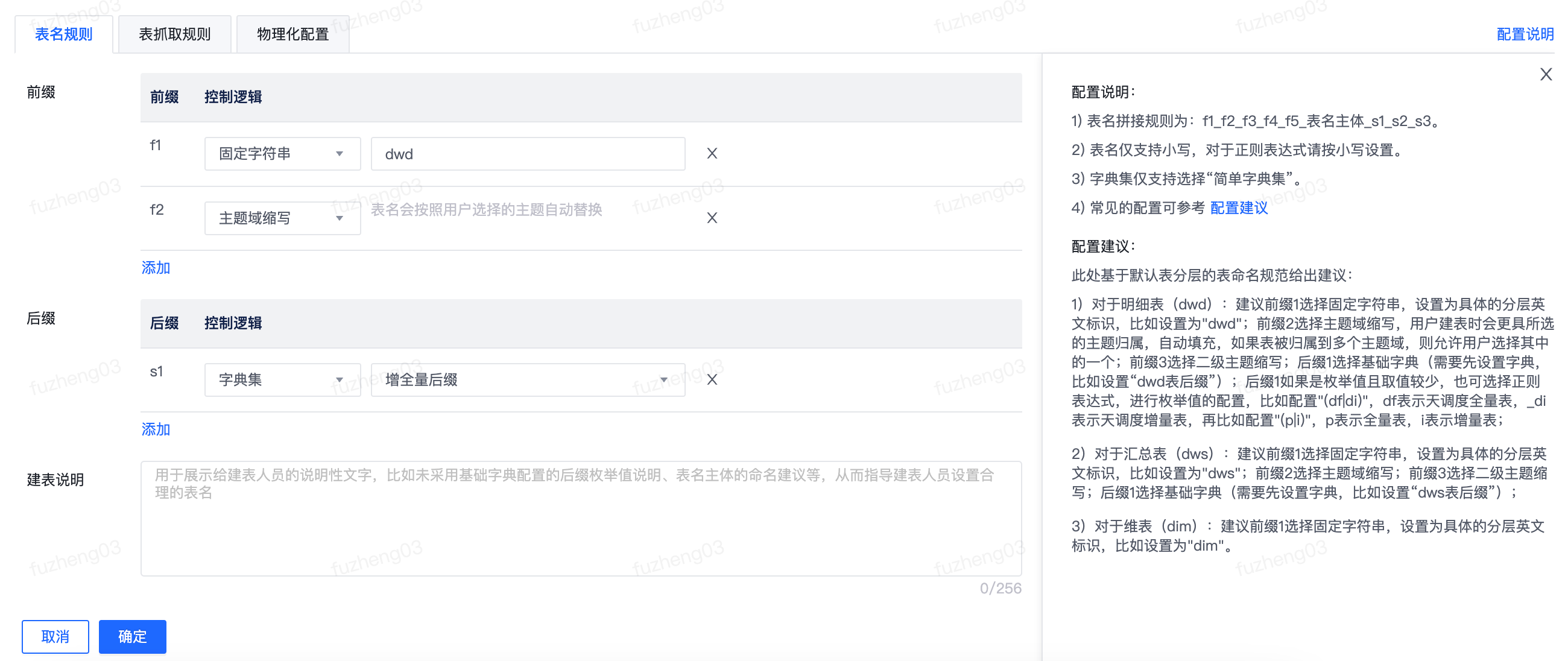
点击配置说明按钮可查看表名配置规则,在配置建议中可了解基于默认表分层的表命名规范建议。
表抓取规则
所有分层都支持表抓取规则的设置。设置后系统会定时把符合规则的表进行抓取并显示在模型设计-数据表的未分组(系统)中。在未分组中,将显示所有被抓取且未设置主题域的表。表抓取规则分为命中规则和剔除规则,规则内容可通过正则表达式进行表示。
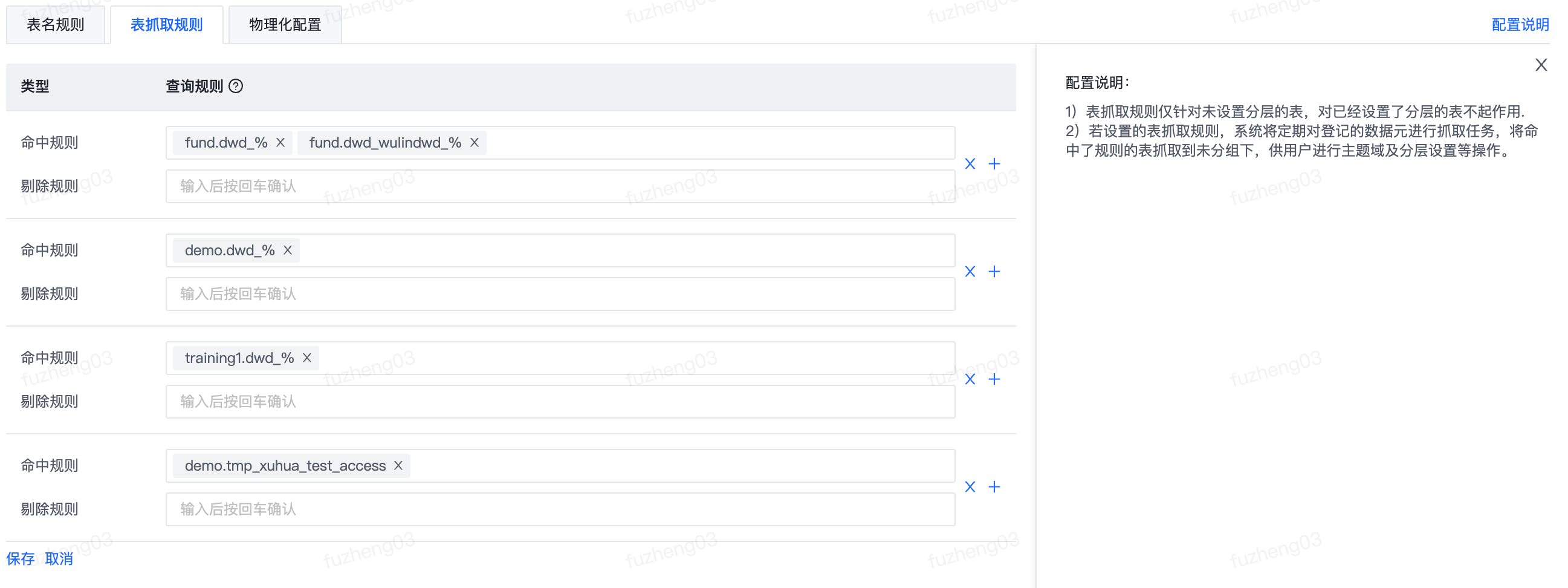
配置说明:
- 表抓取规则仅针对未设置分层的表,对已经设置了分层的表不起作用;
- 如果设置了表抓取规则,系统定期对登记的数据元进行抓取,将命中了规则的表抓取到未分组下,供用户进行主题域及分层设置等操作。
物理化配置
允许建表的库
此功能用来配置当前分层可以在哪些数据库中进行建表(在有库建表的权限前提下)。比如设置明细层(dwd)只能在dwd这个数据库下创建表,则用户在创建建表工单中,表分层选择dwd-明细层时,如果用户有dwd库的建表权限,则可以选择dwd库;如果没有,则无法继续建表。这种限制可以保证有权限的用户在数仓规定的数据库内创建对应的分层的表。此处填写对应的数据库名称,支持填写多个。
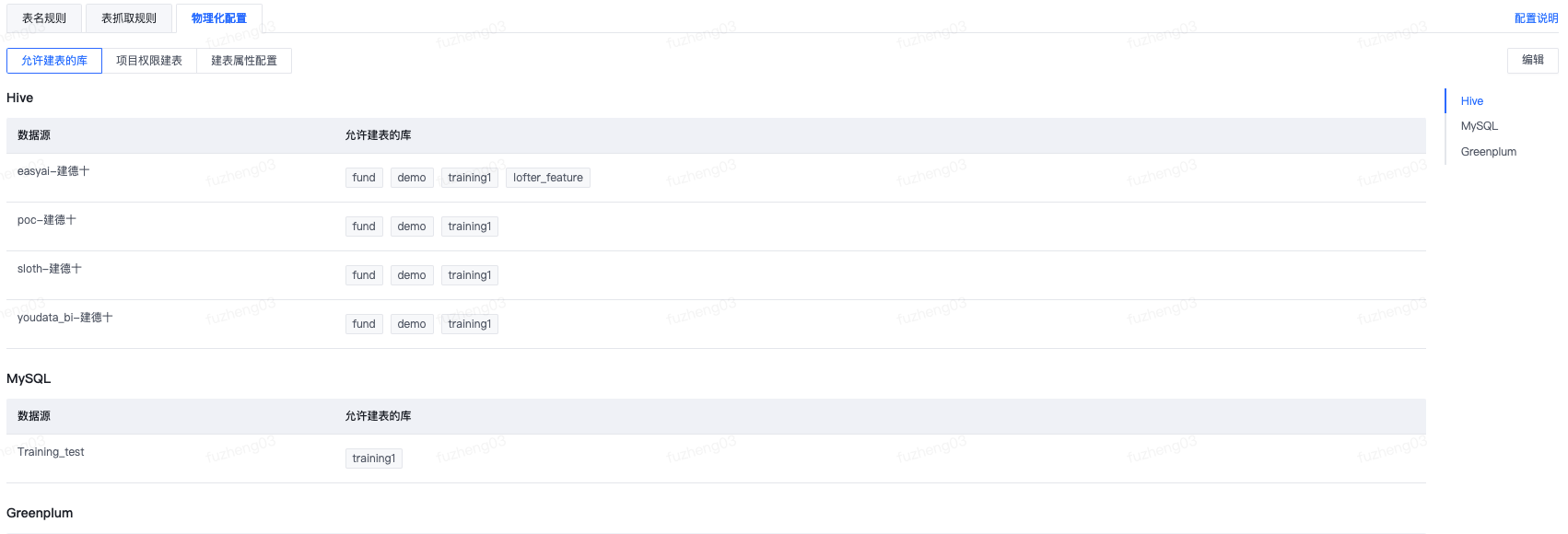
配置说明:
- 用于设置当前分层允许在哪些库下创建表;
- 若未设置允许建表的库,则默认所有的库都可以选择。
项目权限建表
项目权限建表功能,针对需要约束开发人员的建表权限,防止开发人员在自助分析页面中建表,而不是通过维度建模(原模型设计中心)走建表工单的问题。比如数仓管理者设置了dwd-明细层仅能在dwd库下建表,用户user1无dwd库的建表权限,则用户如果需要在dwd库下创建明细表,那么在自助分析下建表就会失败,但是可以通过维度建模(原模型设计中心)创建工单,由审批人员来审批通过后实现。
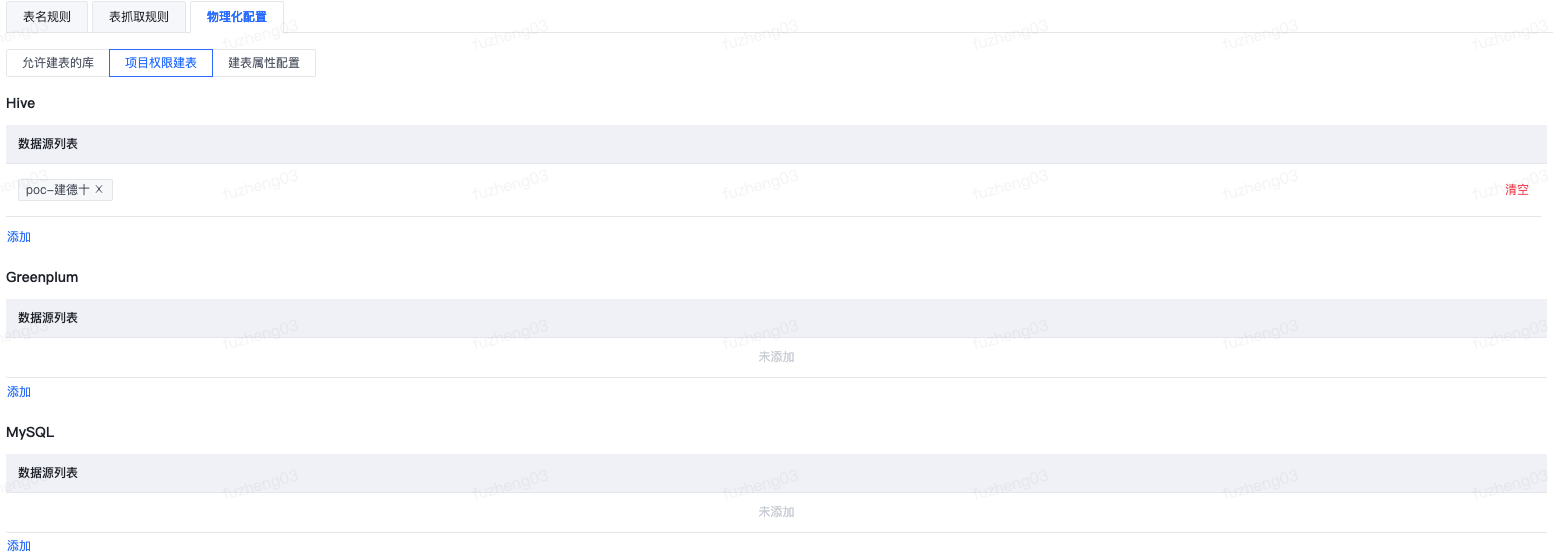
配置说明:
- 用于设置哪些数据源支持使用项目权限进行建表;
- 对于Hive数据源,直接使用项目账号进行建表;对于非Hive数据源则使用项目账号所绑定的源系统账号进行建表;
- 项目权限建表仅当该分层未设置自动审批时才可使用,开启后,工单审批者在工单详情页也会查看到“项目权限建表”的提醒;
- 若设置了允许建表的库,那么仅在允许建表的库范围内开启是否进行项目权限建表。
建表属性配置
建表属性配置完成后,在该层新建表时会对表预置这些已经配置好的参数。
当前建表属性配置支持对Hive、MySQL、Vertica、Greenplum、Oracle五种数据源类型的表进行设置。
Hive
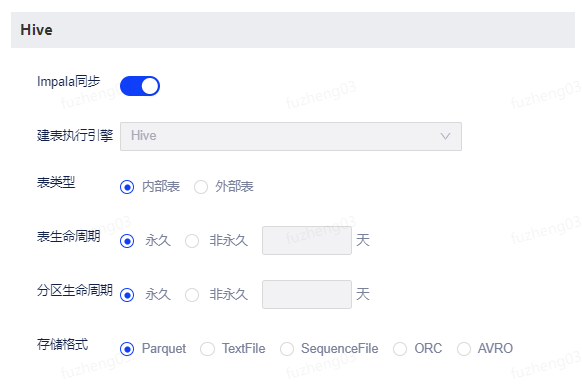
支持设置项 描述 Impala同步 是否开启Impala同步,取决于当前项目-集群下有无Impala集群。开启Impala同步之后,在表设计工单管理中,创建建表工单中会支持Impala开启配置,开启后创建的表,元数据会自动同步到Impala元数据中,在自助分析中即可用Impala执行查询。 建表执行引擎 默认Hive。 表类型 支持设置内部表和外部表,默认为内部表。设置外部表时需要填写HDFS路径。 表生命周期 支持设置表生命周期,默认为永久。设置为非永久时,需填写时长。 分区生命周期 支持设置分区生命周期,默认为永久。设置为非永久时,需填写天数 存储格式 支持Parquet、TextFile、SequenceFile、ORC、AVRO,默认为Parquet。 压缩方式 具体如下:
Parquet:支持UNCOMPRESSED、SNAPPY、LZO、GZIP、LZ4;
TextFile:支持不压缩、LZO;
SequenceFile:不支持;
ORC:支持ZLIB、NONE、SNAPPY;
AVRO:不支持MySQL
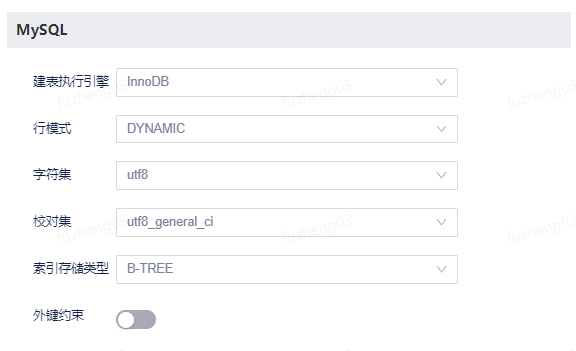
支持设置项 描述 建表执行引擎 支持InnoDB和MyISAM,默认为InnoDB。 行模式 支持COMPACT、REDUNDANT、DYNAMIC、COMPRESSED。 字符集 默认为utf8,其它支持详情查看产品页面。 校对集 在字符集内用于比较字符的一套规则的集合。支持utf8_general_ci等,其它详情可查看产品页面。 分区生命周期 支持设置分区生命周期,默认为永久。设置为非永久时,需填写天数。 索引存储类型 支持B-TREE。 外键约束 支持外键约束的设置,默认关闭。 Vertica
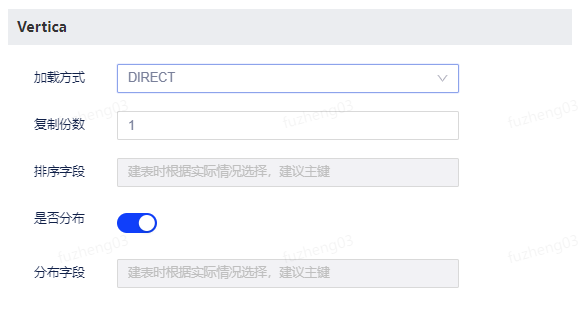
支持设置项 描述 加载方式 支持DIRECT、AUTO、TRICKLE。
1. DIRECT:该模式下直接将数据加载到ROS容器中,适用于大容量(>100mb)的批量加载。Vertica的测试表明,直接负载在最广泛的场景下都能提供最佳性能。
2. AUTO:初始加载数据到WOS中,适合于小批量加载。
3. TRICKLE:仅将数据加载到WOS中,适合频繁的增量加载。复制份数 默认为1。 排序字段 用来设置进行排序的字段,根据实际情况进行选择,建议主键。 是否分布 开启后可进行分布字段设置。 分布字段 对于外部表无效时,需要设定字段作为表自动投影分发数据的依据。 Greenplum
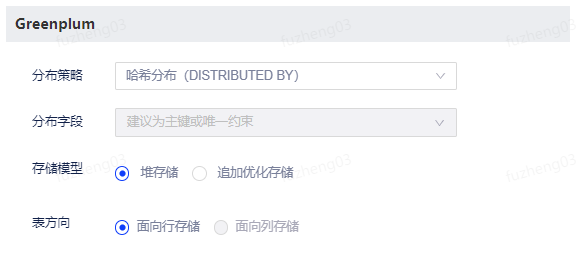
支持设置项 描述 分布策略 支持哈希分布和循环分布。 分布字段 建议为主键或唯一约束。 存储模型 支持堆存储和追加优化存储。当选择追加优化存储时,可选择面向列存储,同时支持是否压缩设置。 表方向 支持面向行存储和面向列存储。
当存储模型为堆存储时,只支持面向行存储。
当存储模型为追加优化存储时,支持面向行存储或面向列存储。Oracle
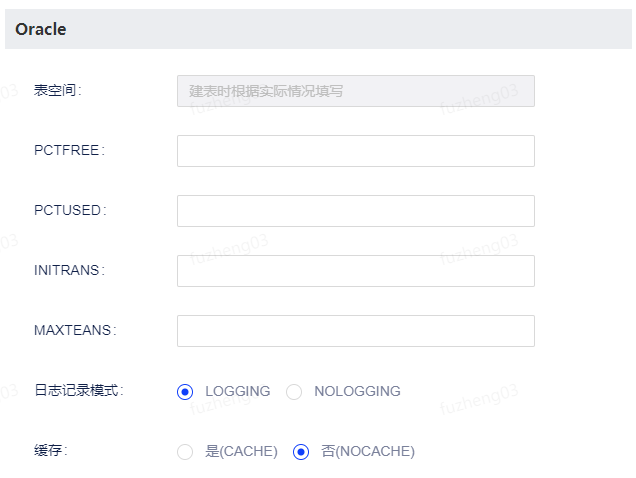
支持设置项 描述 表空间 建表时根据实际情况填写。 PCTFREE 用来表示一个数据块的空间百分比,当数据占用的空间达到此上限时,新的数据将不能再插入到此块中。 PCTUSED 用来表示当数据块里的数据低于多少百分比时,可以重新被插入数据。 INITRANS 用来控制初始并发事务数。 MAXTRANS 用来控制最大的并发事务数。 日志记录模式 包括LOGGING和NOLOGGING。 缓存 包括CACHE和NOCACHE。
Oracle除了上述基本参数外,还支持存储参数(STORAGE)设置。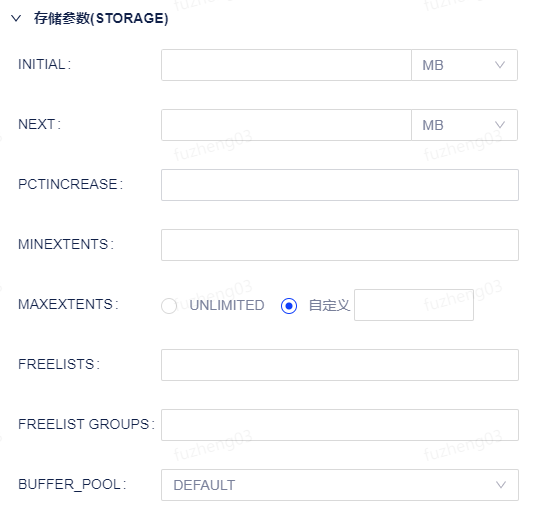
支持设置项 描述 INITAL 指定表第一个区的大小。 NEXT 指定初始扩展区大小。 PCTINCREASE 指定扩展区递增的百分比。 MINEXTENTS 数据库对象能够扩展的最小值。 MAXEXTENTS 数据库对象能够扩展的最大值。 FREELISTS 指定了所有可以用于insert操作的数据块的列表。 FREELISTS GROUPS 表示空闲链表数量。 BUFFER_POOL 指定表数据存储在哪个缓冲池中,支持KEEP、RECYCLE、DEFAULT。
此外,在“建表属性配置”中还支持对不同数据源进行强制分区设置。开启后,在创建建表工单的字段配置页面,分区字段为必填项,当删除所有分区字段后会提示强制分区表,必须至少设置一个分区字段。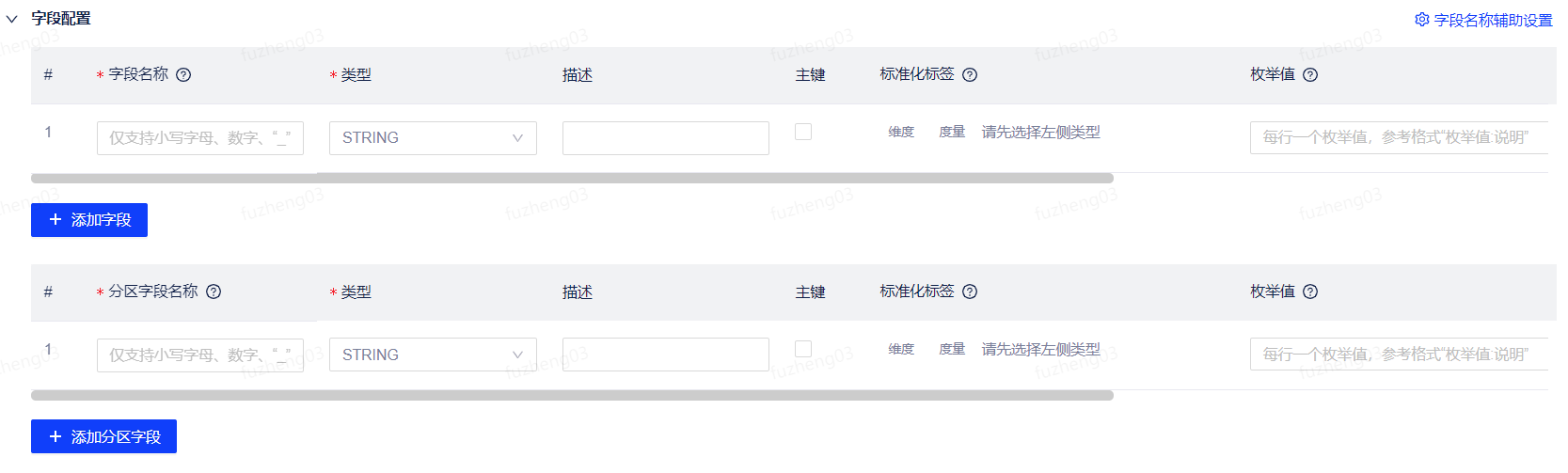
| 说明:当前支持强制分区表设置的数据源类型有Hive、Vertica、Greenplum、Oracle,MySQL不支持该功能。 |