INFO-丢数据排查示例
更新时间: 2025-05-20 15:49:44
INFO-丢数据排查示例
适用模块
离线开发任务运维具体说明
不同场景丢数据得排查情况,持续补充中使用示例
场景一、多个任务操作同一个表1、调度任务
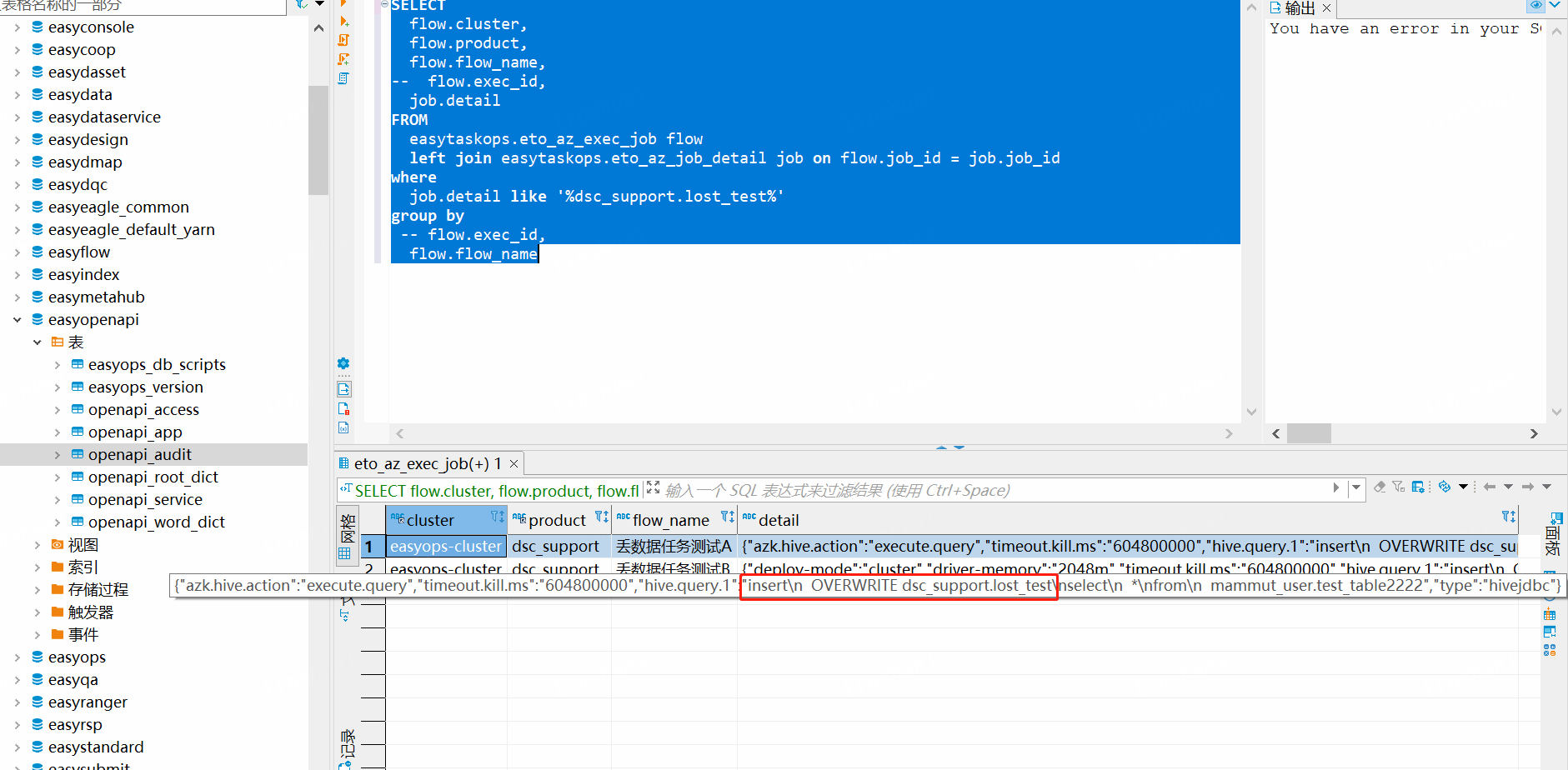
SELECT
flow.cluster,
flow.product,
flow.flow_name,
-- flow.exec_id, 调度的实例id job.detail
FROM
easytaskops.eto_az_exec_job flow
left join easytaskops.eto_az_job_detail job on flow.job_id = job.job_id
where
job.detail like '%dsc_support.lost_test%'
group by
flow.flow_name
 2、离线任务
2、离线任务SELECT
flow.cluster,
flow.product,
flow.flow,
job.job_alias_name
FROM
mammut.pf_az_flow flow
join (
SELECT
f.flowaliasname,
def.job_alias_name
FROM
mammut.pf_az_job_flow_name f
JOIN mammut.pf_azjob_def def ON f.azconfigid = def.azconfigid
WHERE
def.data LIKE '%access_test2%'
) job on flow.flow = job.flowaliasname;

场景二、多表使用相同location,导致数据重复
select
DBS.NAME as db_name,
t.TBL_NAME as table_name from
metastore.TBLS t
left join metastore.SDS s on t.SD_ID = s.SD_ID
left join metastore.DBS dbs on t.DB_ID = dbs.DB_ID
where
location = 'hdfs://easyops-cluster/user/dsc_support/hive_db/dsc_support.db/lost_test' \G;

场景三、人为删除数据
1、hdfs审计日志确认操作人
bdms_xxx为个人账号,排查自助分析与离线开发,项目账号为调度执行

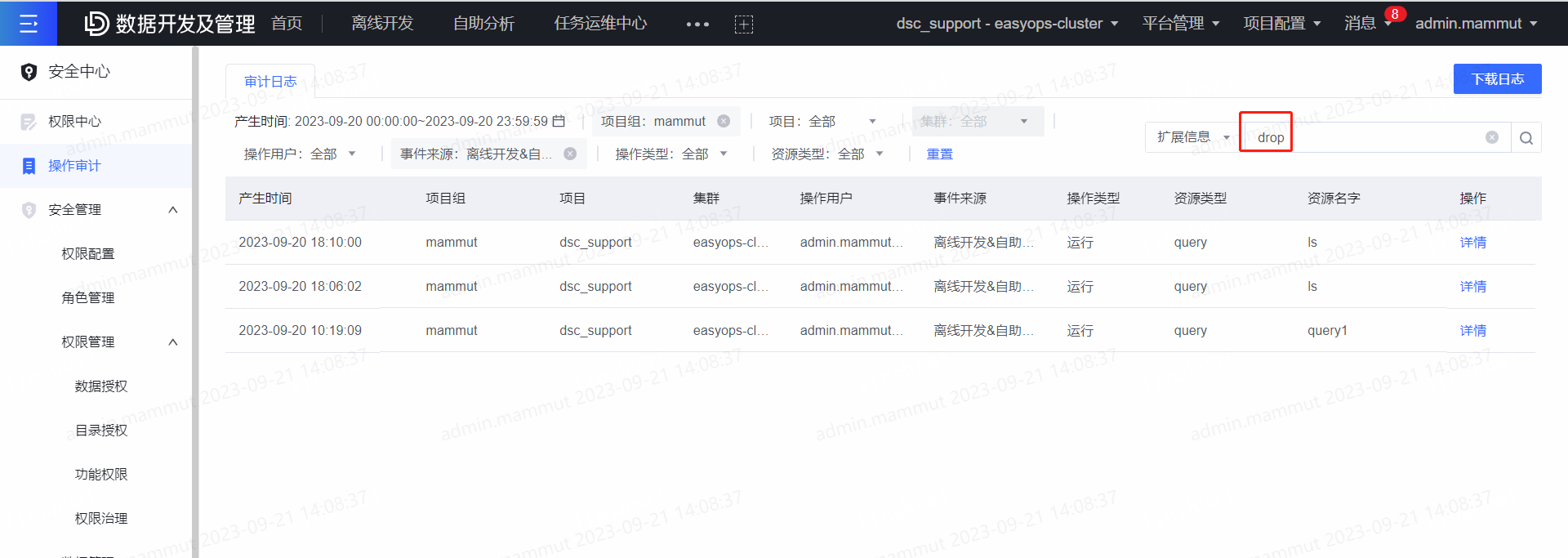
2、自助分析删除
2.1、已知操作项目
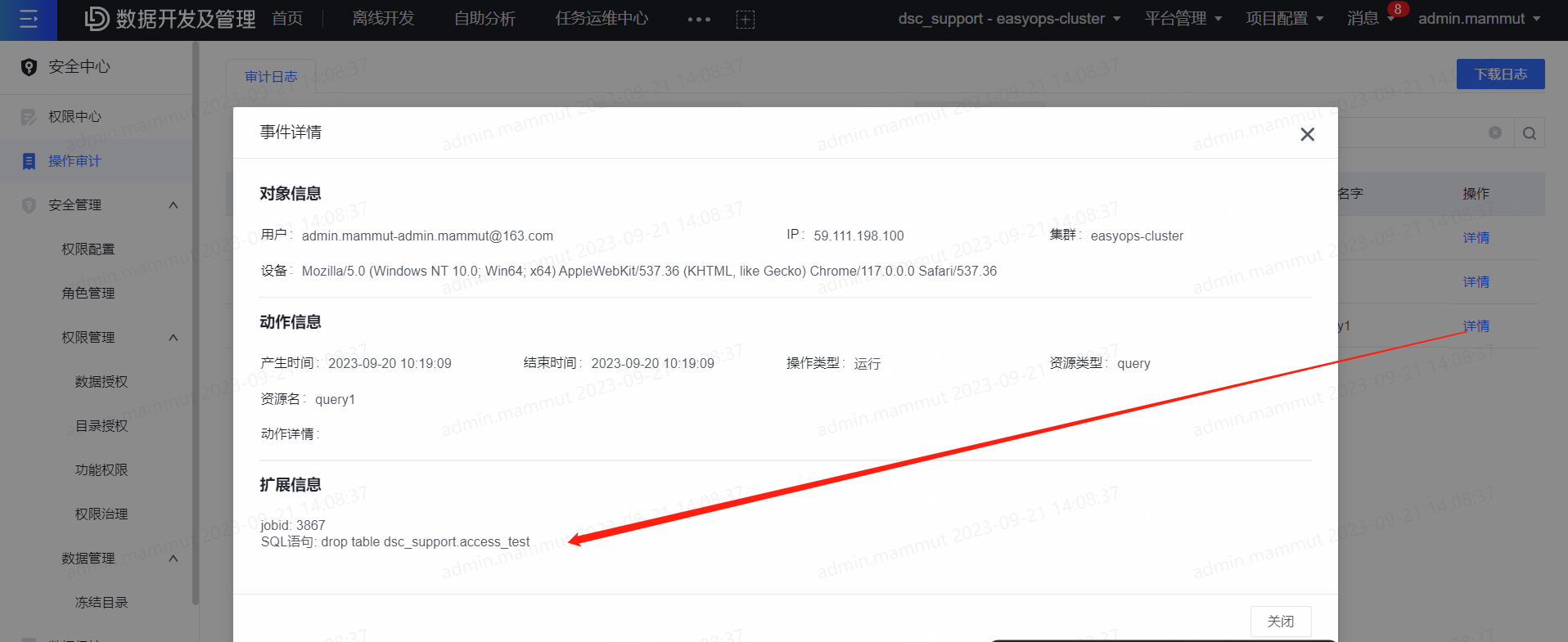
2.2、全平台检索
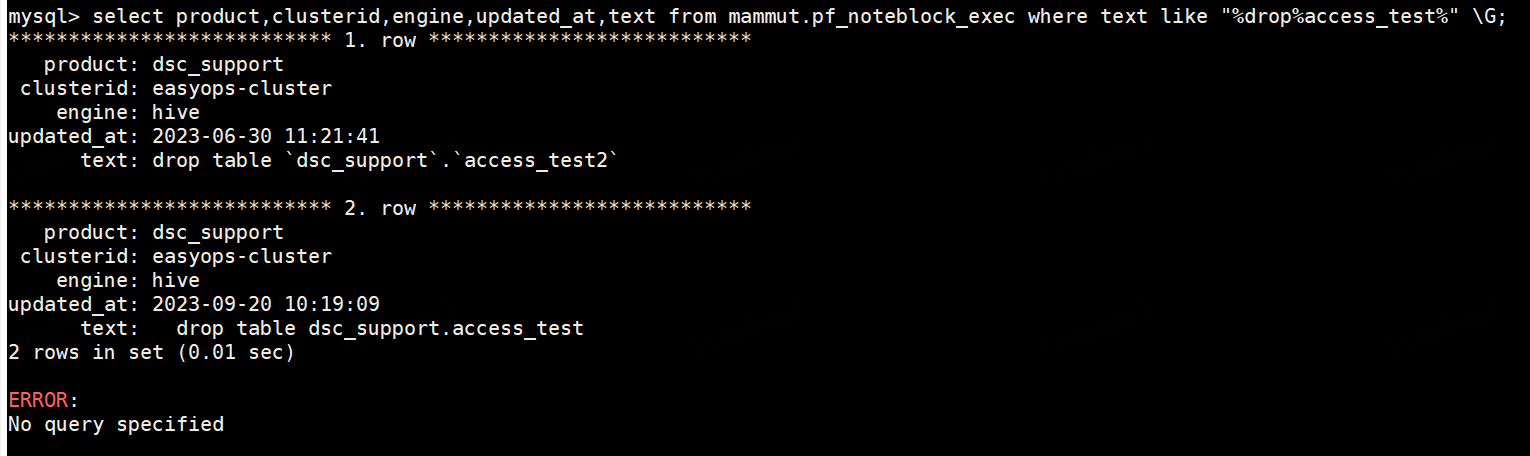
select product,clusterid,engine,updated_at,text from mammut.pf_noteblock_exec where text like "%drop%access_test%" \G;
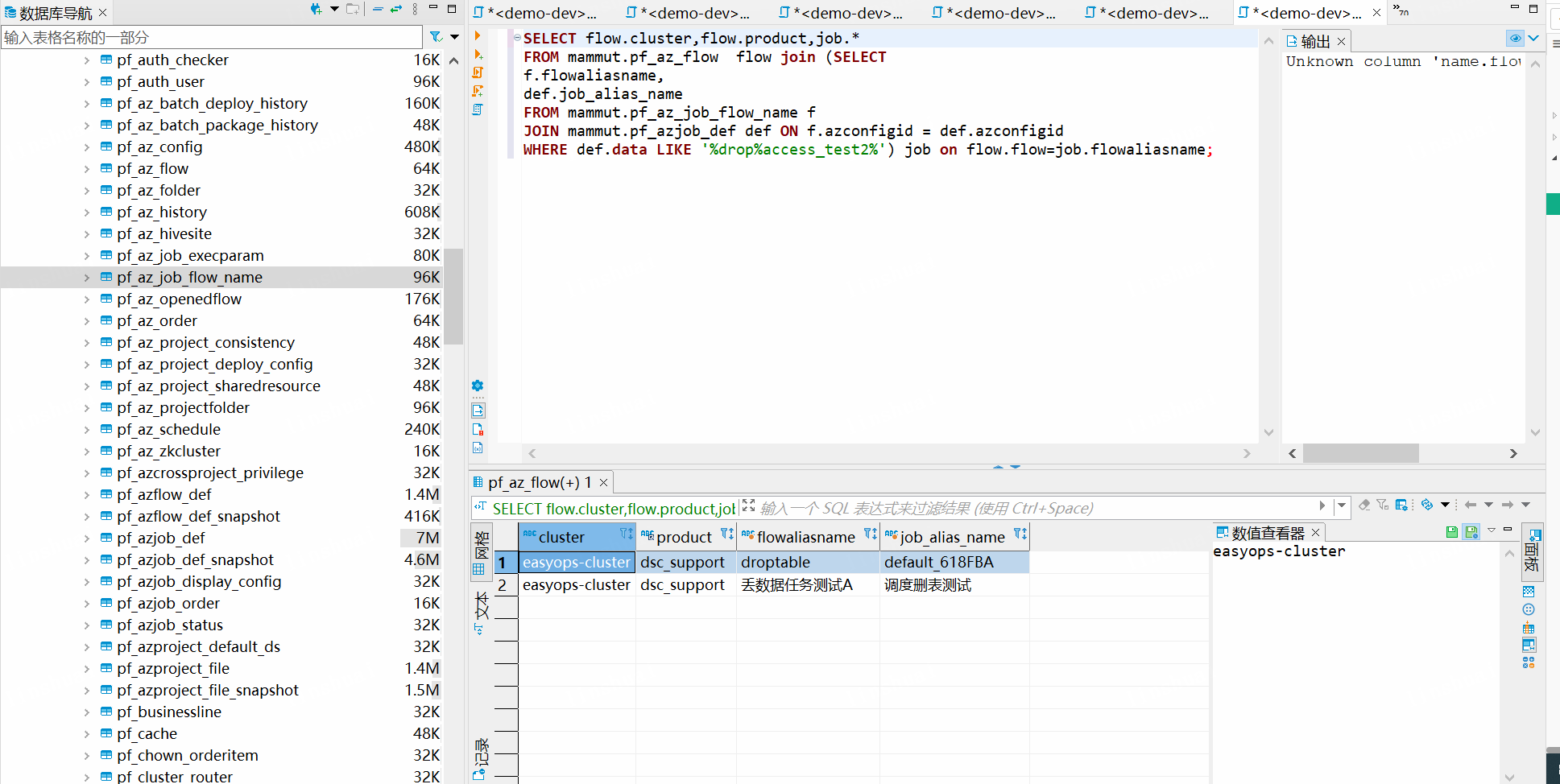
3、离线开发删除
SELECT
flow.cluster,
flow.product,
flow.flow,
job.job_alias_name
FROM
mammut.pf_az_flow flow
join (
SELECT
f.flowaliasname,
def.job_alias_name
FROM
mammut.pf_az_job_flow_name f
JOIN mammut.pf_azjob_def def ON f.azconfigid = def.azconfigid
WHERE
def.data LIKE '%drop%access_test2%'
) job on flow.flow = job.flowaliasname;
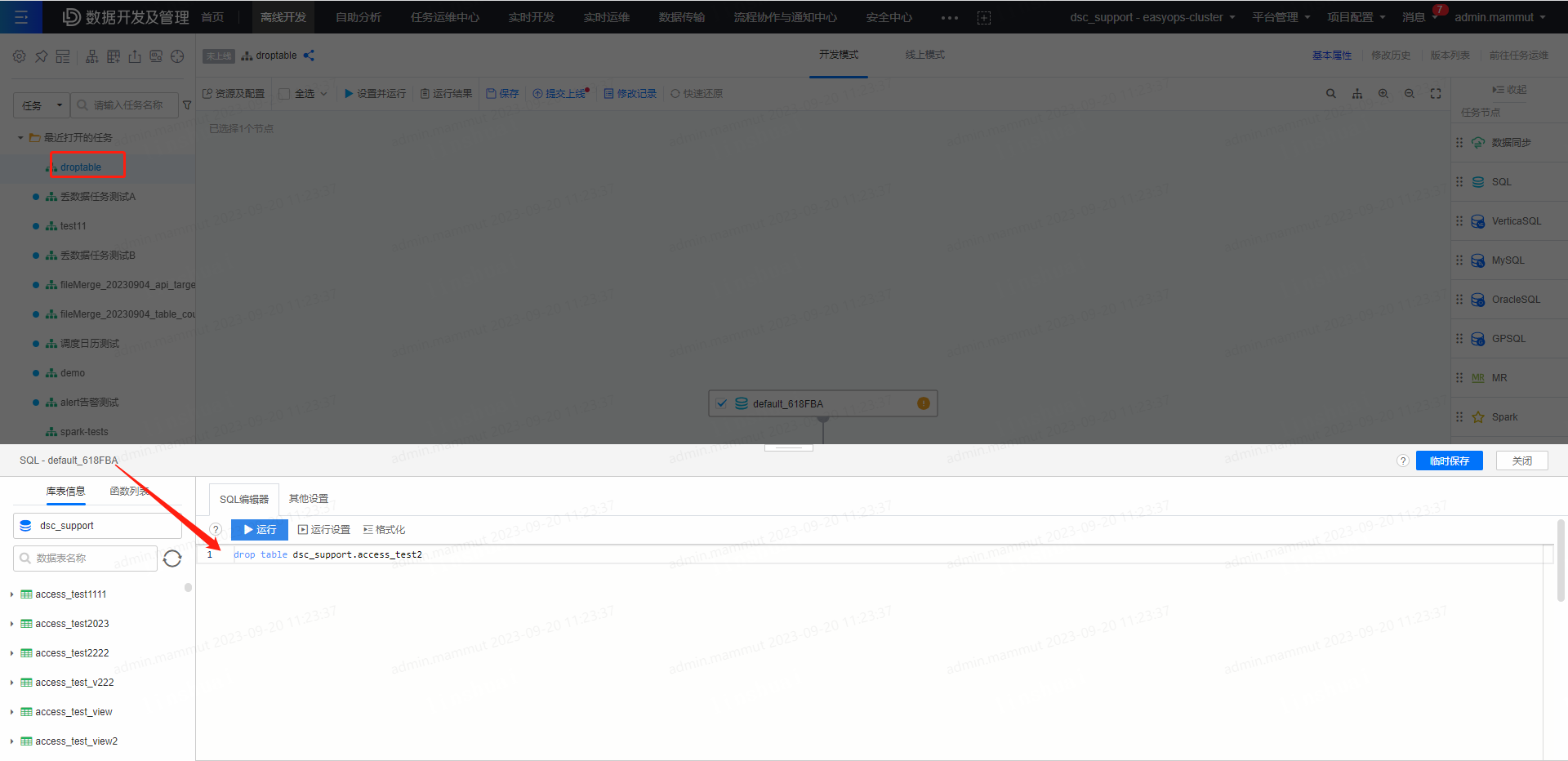
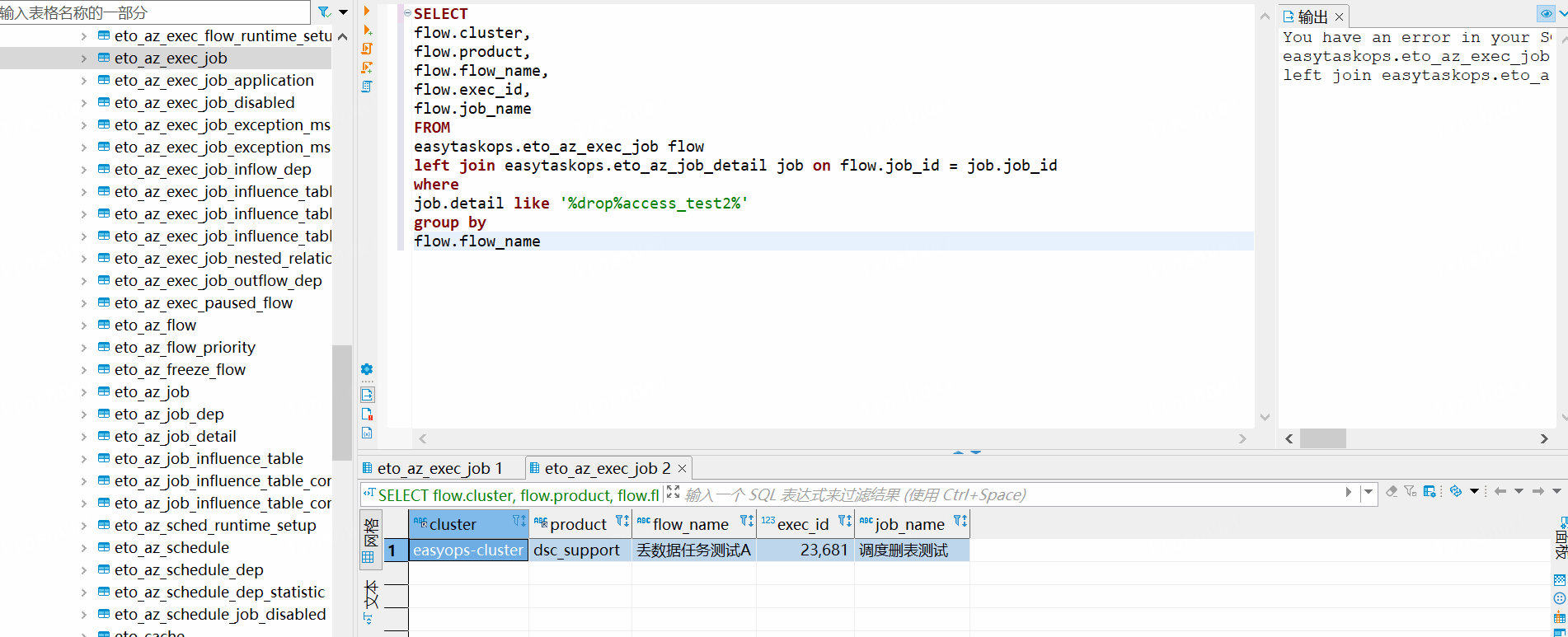
4、调度删除
SELECT
flow.cluster,
flow.product,
flow.flow_name,
flow.exec_id,
flow.job_name
FROM
easytaskops.eto_az_exec_job flow
left join easytaskops.eto_az_job_detail job on flow.job_id = job.job_id
where
job.detail like '%drop%access_test2%'
group by
flow.flow_name

作者:林帅