数据识别
数据识别功能用于识别敏感字段,可通过库表的设置筛选识别范围。项目负责人、管理员具有使用该功能的权限。
新增识别任务
在数据识别页面中,点击新增识别任务可进行识别任务的配置。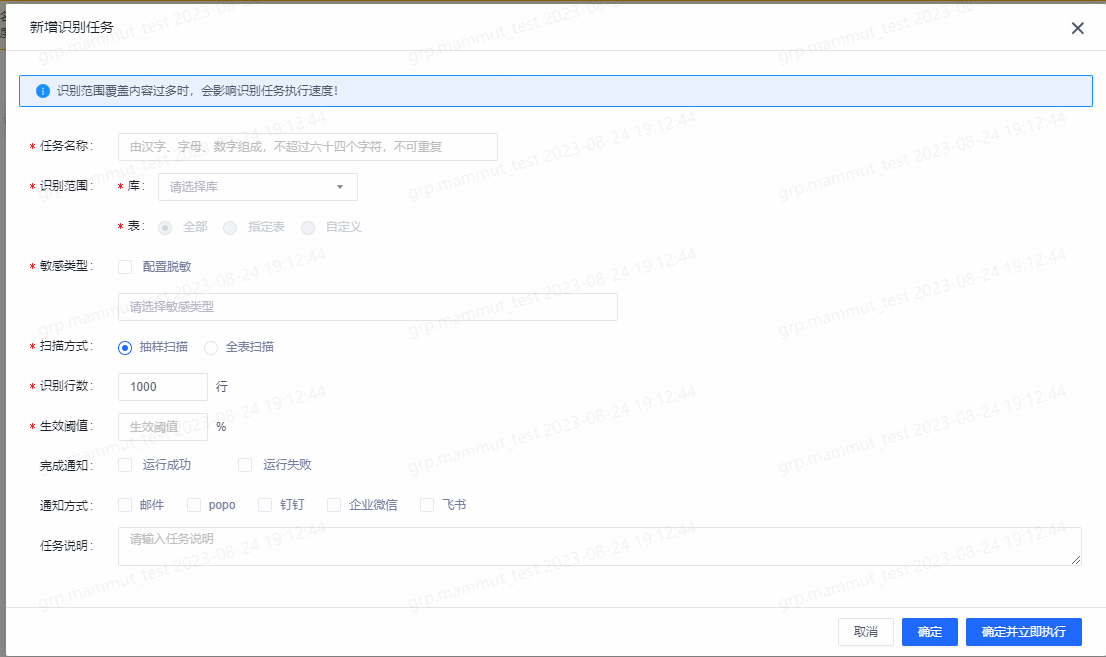
- 任务名称:任务名称由用户自定义,可由汉字、字母、数字组成。
识别范围:识别范围支持当前项目内库的筛选;表的筛选支持全部、枚举及自定义。
- 选择枚举时,可添加表并设置分区字段和分区值(当前分区值不支持azkaban参数,只支持具体的日期格式)。

- 选择自定义时,可通过正则表达式匹配表的内容。

- 选择枚举时,可添加表并设置分区字段和分区值(当前分区值不支持azkaban参数,只支持具体的日期格式)。
敏感类型:此处选项根据敏感类型功能中的创建的类型而定,默认为银行卡号、手机号、身份证号以及邮箱,支持复选。如果对于选择的敏感类型需要进行脱敏,可勾选配置脱敏按钮,勾选后需要配置相应的脱敏规则。

扫描方式:支持抽样扫描和全表扫描两种扫描方式。选择抽样扫描后可设置识别行数,无数量上限。
生效阈值:生效阈值=命中行数/识别行数,结合识别行数,判断此次识别结果。
- 完成通知:支持运行成功和运行失败两种结果通知。
- 通知方式:当前支持邮件、短信、电话等。
- 任务说明:对识别任务进行补充说明,帮助其他用户了解任务。
配置完成后,点击确定关闭窗口。新建的任务处于等待状态。
点击立即识别,可在对话框中选择Spark版本、执行队列等运行参数,配置完成后点击确定,任务状态变为识别中开始正式执行。当所有对象都已成功完成识别,则状态会置为成功;如果状态变为失败,则表示执行识别任务失败,未完成识别工作。
查看实例及结果
点击实例列表按钮,可跳转至执行实例页面。可查看每一次执行实例的结果,数据识别任务若有多个执行实例,则仅最新结果可确认,历史实例的结果仅作为展示。
任务识别结果页面,页面展示当前被识别数据的库名、表名、字段名、数据采样、敏感类型以及安全等级,如下图所示:
将鼠标放置在采样的数据上,会显示部分采样结果: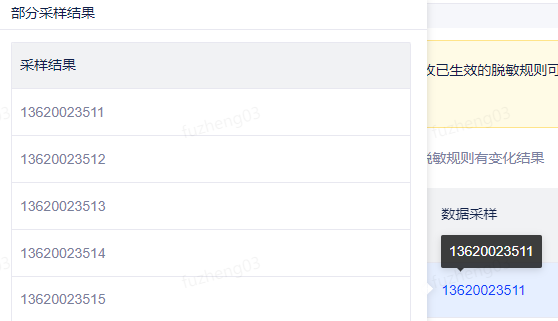
点击编辑按钮,可对敏感类型进行查看,被识别出来的敏感类型会在类型旁出现 ,当用户不认可识别结果也可以对敏感类型重新选择,更新后的敏感类型会同步到数据地图进行展示。
,当用户不认可识别结果也可以对敏感类型重新选择,更新后的敏感类型会同步到数据地图进行展示。
对识别结果可进行编辑操作,此时如果更改敏感类型,相应的安全等级也会根据事先的配置进行更改。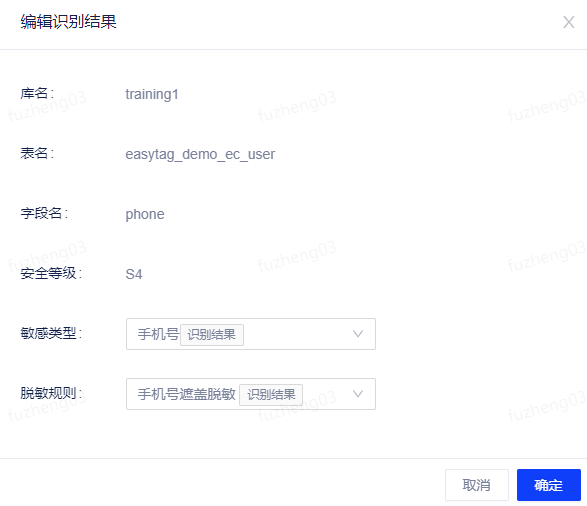
选中需要进行脱敏的数据,点击批量确认脱敏规则按钮,进行脱敏规则生效。
生效后,在已生效规则中显示当前脱敏规则,并在数据脱敏-动态脱敏列表中进行展示。
支持查看本次识别结果与上次结果是否有变化已经变化详情 。首次查看变化详情时先点击右上角检测按钮,检测完毕之后点击查看进入对比详情页,可查看本次结果与上次结果、本次结果与已生效结果的差异项。
可查看本次结果新增字段(本次识别出但上次未识别出的敏感字段)、本次结果更新字段(本次与上次识别的敏感类型结果不同)、本次结果减少字段(上次识别出但本次未识别出的敏感字段)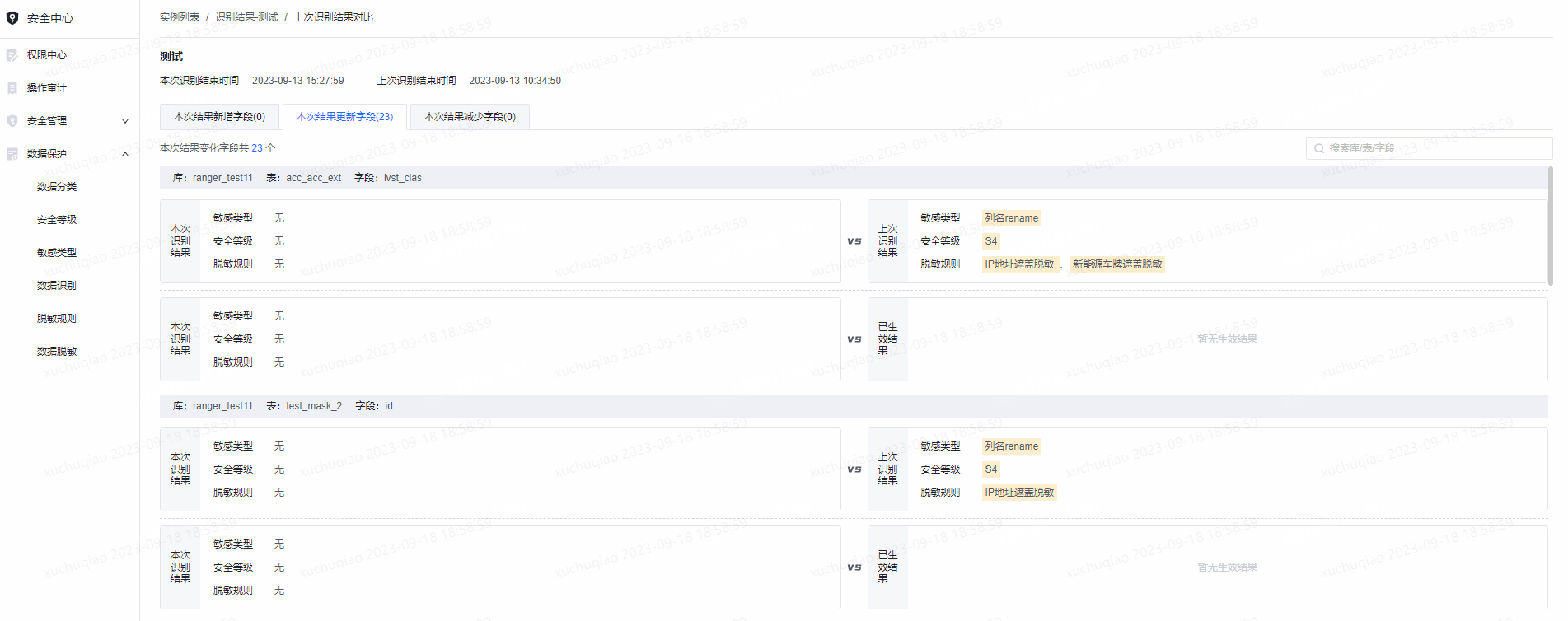
编辑任务
对处于未识别中的任务支持编辑操作,点击编辑按钮进行编辑,编辑过程中不支持识别范围的修改,即不支持库、表的更改。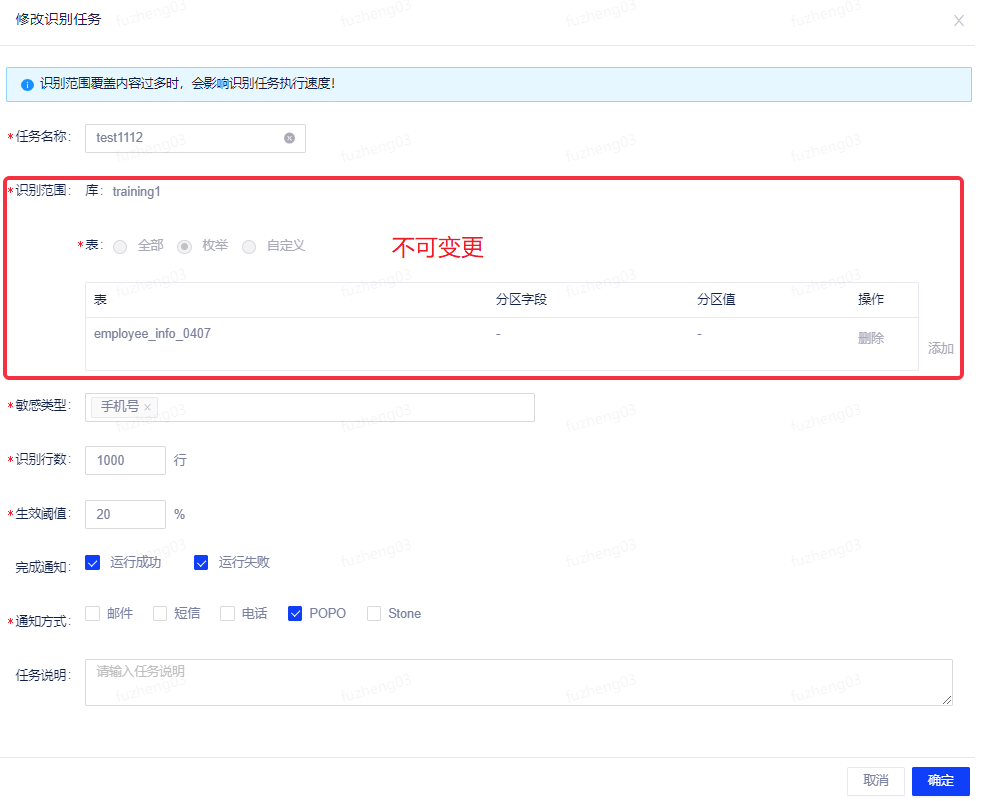
复制任务
对于已创建的任务支持复制操作,点击复制按钮后进入任务编辑页面,编辑完成后点击确定即创建新的识别任务,任务名称默认为原任务名+“_copy”。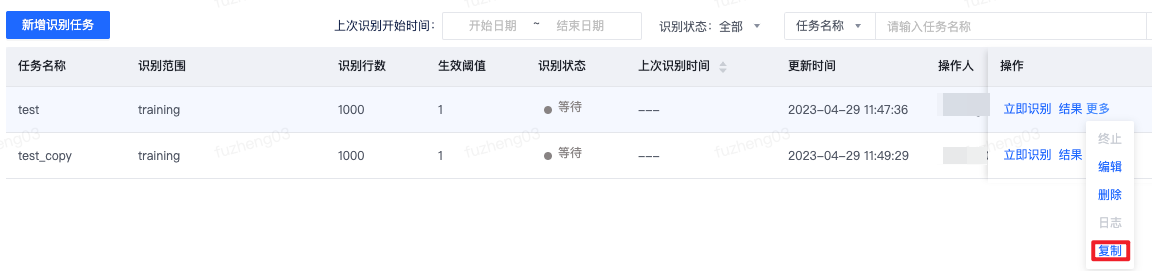
识别任务调度
数据识别任务作为特殊节点支持在离线开发任务中引用并配置调度,支持在安全中心识别任务的查看历史执行实例和识别结果。在离线开发任务中配置数据识别任务节点,并提交上线设置调度。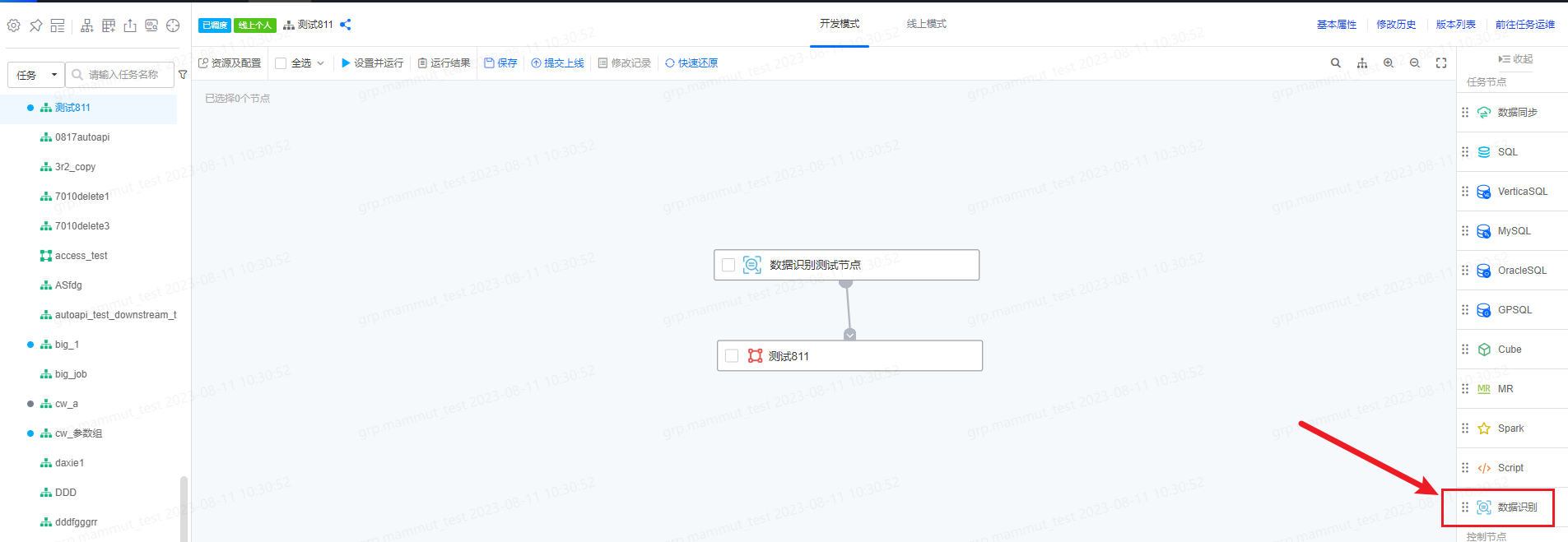
点击具体识别任务的实例列表,查看某次执行实例的具体识别结果。点击引用详情,可查看识别任务在离线开发任务中的引用情况。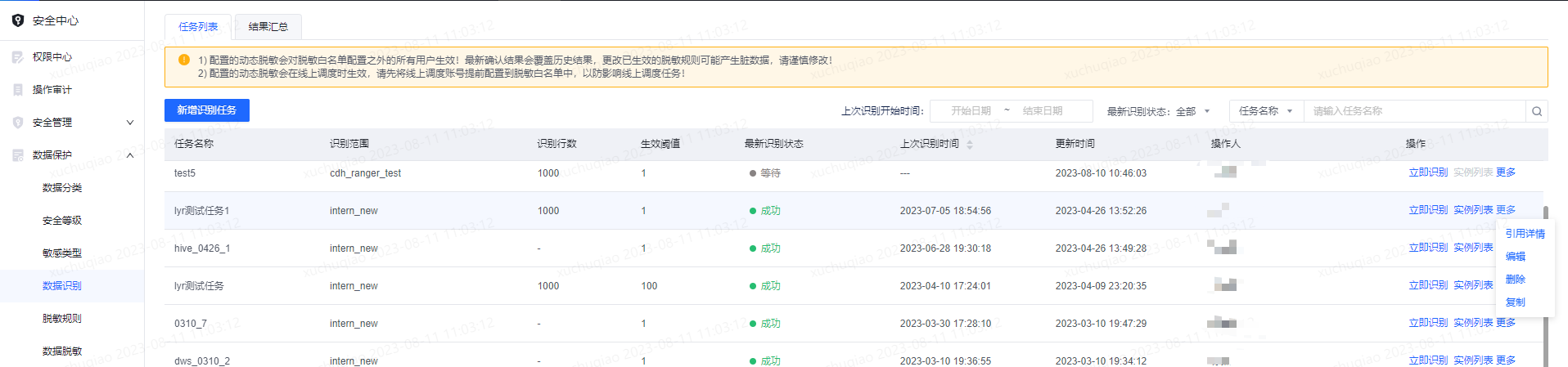

识别任务支持多数据源
识别任务支持多数据源选择,本期新增StarRocks数据源支持,可以在新建识别任务中数据源下拉列表中选择。
识别任务支持对整库配置分区规则
新增识别任务,在分区策略规则中配置分区匹配规则,该规则会被用到所选范围下的所有表。
