更新历史
版本:v3.30.0
新增功能
【离线】FTP数据源类型适配spark3.3.4版本;
【离线】离线传输任务,Spark引擎下,数据去向新增RabbitMQ数据源类型;
- 功能介绍:
- Spark引擎下,离线传输任务,数据去向新增RabbitMQ数据源类型,支持数据写入;
- 【配置管理】快速创建表配置功能增强,支持下载物理字段和JDBC类映射规则,支持配置不同数据源的字段映射;
- 功能介绍:
- 配置管理,针对离线同步任务,快速创建表配置中,新增物理字段和JDBC类映射规则文件下载功能;
- 新增对于特殊字段类型映射规则自定义的功能,可选择诸如MySQL、SQLServer等数据源来源,配置快速建表的去向字段类型;
- 文案优化,细化物理字段和JDBC字段类型的内容显示。
- 【离线】spark引擎下,当数据来源/去向为登记的Hive类型且登记版本为3.1.x-CDP7.1.x时,支持针对大表传输场景进行优化。
- 功能介绍:
- 来源/去向为3.1.x-CDP7.1.x的hive类型时,支持分区过滤功能;
- 在源端为Hive大表传输场景下建议填写,可用于筛选Hive表分区显著提升数据读写性能,支持标准的where查询语句,仅需要填写涉及分区字段的条件表达式即可。
【离线】当数据去向为登记的Hive且版本为EasyData 2.1.x-Hadoop2.9.2版本时,分区表情况下支持动态写入功能;
【离线】Spark或DataX引擎下,支持向导/SQL模式下创建任务的openapi功能;
功能优化
1.【离线】修复hive2redis场景下,日志无报错但redis只写入少量数据的问题;
2.部署提效,支持对接控制台的统一域名来实现快速修改域名;
3.问题修复,登记PostgreSQL时,当版本为13.2时支持使用高版本驱动。
版本:v3.29.0
新增功能
- 【离线】Spark任务引擎下,当数据去向为Elasticsearch数据源类型时,支持选择或手动输入静态索引,支持配置preDSL和postDSL内容;
- 功能介绍:
- 当Elasticsearch数据源作为数据去向,静态索引下,支持选择已存在的索引或手动输入不存在的索引;
- 在静态或动态索引模式下,均支持配置preDSL或postDSL内容,比如可以配置mappings或分片数量等属性;
版本:v3.28.0
新增功能
- 【离线】DataX任务引擎下,数据来源和去向支持FTP数据源类型;
- 功能介绍:
- 创建离线同步任务时,若任务引擎为DataX,数据来源和去向均支持FTP数据源类型;
- 【离线】DataX任务引擎下,数据来源和去向支持Kafka数据源类型;
- 功能介绍:
- 创建离线同步任务时,若任务引擎为DataX,数据来源和去向均支持Kafka数据源类型;
【离线】创建离线同步任务,向导和SQL模式下,数据来源和去向适配Doris新版本(2.1),且若去向为Doris时快速建表功能也适配支持Doris新版本(2.1);
【实时】创建实时同步任务,数据去向适配Doris新版本(2.1);
【离线】离线传输任务的脏数据管理功能适配spark3.3.1版本;
【离线】Spark任务引擎下,若来源为MongoDB,去向为Hive时支持快速建表操作;
【离线】线上任务支持存储目录的功能,按照开发环境任务最新一次提交时的目录作为线上任务的目录,且在发布中心对线上任务进行发布时,将按照线上任务的存储目录,发布至接收方对应的目录下,若目录不存在,将新建同名目录;
【实时】对于Oracle数据源增加开关配置,默认展示Oracle数据源,但仅默认展示其ogg的增量读取方式;
功能优化
1.【离线】FTP作为数据来源时数据目录引用参数组功能优化,支持文件筛选"部分"时直接选择或表达式选择情况下均支持参数组功能;
2.【离线】Spark任务引擎下,FTP作为数据来源时,配置字段信息功能增加开关,默认为关,若开启之后,针对text、csv、excel文件格式,联动新增文件包含标题、标题所在行数以及字段信息内容,且增加提示,文件包含标题仅用于字段信息解析;
3.【实时】报警功能优化,新增延迟metric自动恢复的逻辑;
4.【离线】修复线上任务和开发环境任务重名的问题。
5.【离线】spark任务引擎下,若数据去向为kafka类型,生产者配置中默认去掉消费者的参数配置。
版本:v3.27.0
新增功能
- 【离线】数据来源为FTP,数据去向为Doris时,支持快速创建Doris表,FTP支持定义schem内容;
- 功能介绍:
- 数据来源为FTP时,支持自定义schema内容,当文件格式选择text、csv、excel时,支持选择文件是否包含标题以及标题所在的行数,可填写字段信息;当文件格式选择xml时,无需定义字段信息;
2.【离线】数据去向为Doris时,快速创建Doris表弹框优化,支持选择表类型。
- 功能介绍:
- 当选择表类型为明细表时,需要选择Key列,支持多选;
- 当选择表类型为主键表时,同样需要选择Key列,支持多选;
- 当选择表类型为聚合表时,需要选择Key列和Value列,且Value列需要选择对应的聚合类型,需要注意的是,Value列和Key列字段不可重复,value列支持选择多个字段,配置不同的聚合类型。
3.【离线】当任务引擎为Datax时,向导模式下数据来源和去向新增达梦数据源类型;
4.【离线】当任务引擎为DataX时,向导和SQL模式下,数据来源和去向适配MySQL8版本;
5.【离线】页面形式批量创建离线任务,任务引擎为DataX时,数据来源支持达梦类型,并适配MySQL8版本。
6.【离线】当任务引擎为DataX时,向导模式下,数据来源新增MongoDB类型;
7.【离线】当任务引擎为DataX时,向导模式下,数据来源新增本地文件类型(DataXLocal);
8.【离线】当任务引擎为DataX时,自定义参数中支持对channel数、脏数据、batchsize、jvm等参数进行配置;
9.【离线】离线同步任务列表,新增来源数据源和去向数据源信息展示,且支持对来源数据源和去向数据源进行筛选操作;
10.【实时】实时同步任务列表,支持批量删除操作;
11.【离线】数据去向为SQLServer时,写入规则支持merge into,且联动显示更新键字段,支持选择SQLServer表中的字段,支持多选。
12.【离线】以页面形式批量创建离线同步任务时,第三步支持对创建失败的任务执行重试操作;
13.【离线】【实时】数据去向支持快速建表的类型,表名统一长度为1~128个字符,包括离线(数据去向为Doris、StarRocks、iceberg、clickhouse、greenplum、内置hive)和实时(数据去向为内置hive、iceberg、starrocks)场景。
14.【离线】spark引擎下,向导模式,数据来源和去向新增influxDB数据源类型;
15.【离线】当任务引擎为DataX时,且数据来源为HDFS,字段映射支持删除操作,支持选择字段不导入功能,且支持自定义索引字段类型的功能,支持对字段映射列表进行调整。
16.【实时】自定义参数内容优化,支持对字段类型是否转换等进行配置;
17.【离线】spark引擎下,支持选择cdp版本的Hive数据,新增hive类型适配;
18.【实时】实时传输数据去向写入分区功能增强,支持对不同表结构的写入分区进行配置;
19.【离线】审批策略功能增强,支持使用范围授权,可将当前项目下创建的策略分享给其他项目复用;
功能优化
1.rocketmq版本问题修复,版本号和元数据中心对齐;
2.数据同步任务融合离线开发任务功能优化,支持对无编辑权限的用户进行置灰操作,无编辑权限的用户在离线开发侧不支持引用离线同步任务;
3.starrocks大小写敏感问题修复;
4.【离线】spark引擎下,当数据去向为vertica时,写入规则支持选择copy的限制条件进行调整:若数据来源类型为FTP-text,仅当特殊字符替换开关关闭时,写入规则才支持选择copy,其他情况下不限制copy的选择。
5.【离线】spark引擎下,向导或sql模式,当数据去向为Doris或starrocks时,且导入方式选择stream load,导入间隔默认值从0调整为1000ms,新增batchsize必填字段,默认为5w;
6.【离线】从发布中心跳转到离线同步任务详情页面的url内容更新;
7.【离线】datax引擎下的数据血缘上传逻辑优化;
8.【实时】flink cdc oracle connector功能优化,自动增加心跳配置。
版本:v3.26.0
新增功能
1.【离线】数据来源和去向适配达梦8.1.3版本。
2.【离线】数据去向为StarRocks数据源时,导入方式为stream load支持FENode地址高可用。
3.【离线】数据导出功能适配数据源类型为HDFS的离线传输任务。
4.【实时】来源为Oracle表时,若表名超过30个字符,无法采集任务不支持选择,进行功能适配;
5.【离线】DataX任务引擎功能增强,
- 功能介绍:
- 数据去向为HDFS时,去向字段类型支持Decimal、Binary;
- 数据去向为HDFS时,同名文件处理策略新增overwrite,且原本的truncate中文名称由"覆盖"变更为"截断",新增的overwrite中文名称为"覆盖";
- 对接发布中心功能适配DataX任务引擎;
- DataX任务引擎下支持参数组引用;
- 数据来源为HDFS时,来源表字段类型支持自定义表达式。
6.【离线】离线任务的来源和去向的数据源类型支持Hudi。
7.【实时】数据去向的数据源类型支持选择Hudi。
功能优化
1.对接发布中心的功能优化,包括命中接收方的传输任务审批策略逻辑优化等。
版本:v3.25.0
新增功能
1.【实时】实时传输任务,数据来源新增MongoDB。
- 功能介绍:
- 创建实时同步任务,任务类型为多表同步时,数据来源支持选择MongoDB。
- 注意事项:只有当MongoDB版本>=3.6时才支持创建实时同步任务,增量读取方式为change streams。
功能优化
1.针对传输分区使用az参数报错的问题进行优化,传输侧升级了az修复后的sdk包。
版本:v3.24.0
新增功能
1.【离线】数据去向为FTP时,文件格式支持dbf。
- 功能介绍:
- 创建离线传输任务,若数据去向为FTP时,支持文件格式选择dbf。
2.【离线】批量创建任务,支持选择任务引擎DataX,支持MySQL、Oracle、SQLServer、GaussDB数据源在DataX任务引擎下批量创建任务。
- 功能介绍:
- DataX非标品功能,需额外部署;
3.【离线】支持GoldenDB数据源类型创建离线传输任务。
- 功能介绍:
- 单个创建离线传输任务时,向导模式下,来源和去向支持选择GoldenDB数据源类型;
- 批量创建离线传输任务时,支持选择数据来源为GoldenDB类型;
- 任务包导入导出功能支持GoldenDB数据源类型。
4.【离线】当数据去向为FTP时,列分隔符支持填写多个字符,且最多不超过64个字符;
5.重点功能增加埋点统计功能,包括新建离线同步任务、新建实时同步任务、批量操作等相关功能;
功能优化
1.【离线】离线传输任务融入离线开发的功能优化,包括支持在离线开发侧删除引用的传输任务、支持复制传输任务时选择是否同步复制离线传输任务等;
2.【离线】非结构化功能适配spark3.3版本。
- 功能介绍:
- 当数据来源为FTP时,读取方式为非结构化,适配spark3.3版本;
- 当数据来源为HDFS时,读取方式为非结构化,适配spark3.3版本;
3.【实时】实时传输任务Doris适配2.0版本;
4.【实时】实时传输的数据来源类型支持配置化展示;
5.【离线】创建离线传输任务,快速创建表增加文案提示,建表语句为系统根据默认的字段类型映射关系自动生成,不保证建表语句完全符合需求,请调整确认后再执行建表;
6.【离线】问题修复:包括页面支持库.表名方式搜索、线上任务和开发模式任务对比功能优化等。
7.对接发布中心的功能优化,支持在发布中心侧,点击数据传输任务名称可跳转至任务详情页,包括资源列表、发布记录、发布实例包等相关页面;
8.【离线】当数据去向为SFTP数据源类型时,若sftp采用ssh key的认证方式,且私钥格式为openssh时,离线数据传输对私钥格式进行适配;
9.【离线】数据去向为StarRocks时,导入方式功能优化,仅支持append的方式;
10.【离线】脱敏功能优化,当清空脱敏字段时,一并清空脱敏识别中的扫描规则,支持离线任务保存。
版本:v3.23.0
新增功能
1.【离线】离线同步任务,数据库名称支持大小写模糊搜索。
- 功能介绍:
- 包括创建单个离线同步任务的数据来源和去向、批量创建任务选择的数据来源、数据导入时选择数据去向时,均支持根据数据库名称大小写模糊搜索的功能。
2.【离线】kafka适配支持spark3.3版本。
3.【离线】批量创建任务时新建表支持批量添加字段,包括页面形式和Excel上传两种方式批量创建表时添加字段。
- 功能介绍:
- 仅支持数据去向为Hive时,批量创建表添加字段;
- 页面形式批量创建任务时,若数据去向为Hive时,支持批量创建表时添加字段,可填写自定义表达式,用于标识譬如同步时间、同步人等参数。
- 通过Excel方式批量创建任务时,Excel表格更新,支持针对新建hive表批量添加字段。
4.【离线】数据来源和去向适配api Token鉴权方式的ES8版本。
5.【离线】创建单个离线传输任务时,在脚本模式下,数据来源为Hive时,支持Hive表名和字段名大小写不敏感功能。
6.【离线】DataX引擎,数据去向为HDFS支持选择字段类型。
- 功能介绍:
- DataX任务引擎下,当数据去向为HDFS时,支持数据去向字段选择字段类型,选择范围包括Int、Float、Double、Date、TimeStamp等。
7.提供SPI支持发布中心基于血缘的发布功能。
- 功能介绍:
- 配合发布中心,提供数据传输相关的SPI支持基于血缘的发布功能。
8.【离线】DataX引擎,适配SQL模式。
- 功能介绍:
- 本版本支持在DataX任务引擎下,在SQL模式下可选择ClickHouse、MySQL、Oracle、PostgreSQL和SQLServer数据源创建离线同步任务。
功能优化
1.【离线】复制离线同步任务后,新复制的任务保存位置优化为与原任务一致;
2.【实时】实时同步任务,数据去向为Doris或StarRocks数据源类型时,增加表类型符合判断。
- 功能介绍:
- 创建实时任务时,若数据去向为Doris或StarRocks数据源时,只有当表满足特定要求才支持点击下一步,否则会造成任务失败。
- 仅支持Doris去向表为Unique Key模型;
- 仅支持StarRocks去向表为主键表。
3.【离线】离线传输任务,当数据来源为MongoDB时,字段类型定义方式优化,默认为自定义字段类型。
4.【离线】试运行的离线传输任务的日志,当任务运行成功后,日志信息前置,优化日志信息展示内容,支持快速查看传输开始时间、传输结束时间、传输耗时等参数。
5.【离线】创建单个传输任务时,若库名和表名名称太长,支持Hover展示全部内容。
6.【离线】创建单个传输任务时,优化获取最新表结构时的弹窗交互,增加滚动条适配。
7.【离线】优化在选择数据来源和去向表时,由于库表异常导致返回空列表的报错展示。
8.优化对接发布中心的资源负责人逻辑,支持判断资源负责人为"资源实际导入人"时是否支持发布的功能。
9.【实时】对于正在运行中的实时传输任务,优化日志展示样式,解决长时间loading导致无法查看其他tab下日志的问题。
10.问题修复,包括去向表自动新增字段未生效、导入至ftp数据源时json格式报错、HiveKafka传多个key值数据异常等问题。
11.【实时】创建实时传输任务时,优化多张表结构不同却选择了同一个Topic导致任务失败的问题。
12.交互优化,包括弹窗按钮、线上任务引用详情弹窗表格适配等。
13.【实时】优化将来源表全部移除但仍支持点击下一步的逻辑问题。
版本:v3.22.0
新增功能
1.【离线】来源和去向新增支持Paimon数据源类型
- 功能介绍:
- 创建离线传输任务,支持在spark引擎/向导模式下,数据来源和去向选择Paimon数据源类型;
- Paimon数据源不支持快速创建表功能。
版本:v3.21.0
新增功能
1.【离线】来源和去向新增支持S3数据源类型
- 功能介绍:
- 来源为S3时,支持结构化方式读取S3的txt、csv、excel、parquet文件;去向为S3时,支持向S3结构化写入text、csv、excel、json、parquet文件。 2.【实时】数据去向支持Paimon
- 功能介绍:
- 数据去向支持Paimon,支持选择内置集群下归属于当前项目的Paimon表和公开给当前项目的Paimon表。此外,权限控制上,仅支持选择当前用户有写权限的Paimon表。
- 写入规则上,如Paimon表有主键则写入规则为Change-log,如Paimon表无主键则写入规则为Append-only。
功能优化
1.【离线】来源为PostgreSQL时支持SQL模式
版本:v3.20.1
新增功能
1.【离线传输】DataX引擎新增支持HDFS作为来源和去向。
- 注意事项:DataX为非标品功能,需额外部署。详情请查阅数据传输 v3.18.0 更新公告。
2.【离线传输】DataX引擎新增支持GaussDB作为来源和去向。
- 注意事项:DataX为非标品功能,需额外部署。详情请查阅数据传输 v3.18.0 更新公告。
版本:v3.20.0
新增功能
1.【离线】在离线开发支持新建、编辑、提交、删除离线同步任务
功能介绍:
- 此前,离线同步任务的使用流程为在数据传输-离线同步任务新建、编辑和提交任务,并在离线开发-离线同步节点中选择节点引用的离线同步任务。离线开发任务线上模式引用传输线上模式的任务配置,离线开发任务开发模式引用传输开发模式的任务配置。此模式带来的问题是:1、操作链路长:离线同步节点需要在传输侧新建和提交,操作繁琐;2、容易出事故:新建任务时,如漏提交离线同步任务,离线开发任务线上调度时会报错;3、无法复用离线开发的提交上线卡点:修改传输任务后,传输侧提交即可针对下一次调度生效,无需前往离线开发提交离线开发任务,不受提交上线卡点管控。由此,此版本进行了整体使用流程的优化。
- 支持在离线同步节点新建和编辑离线同步任务,保存离线开发任务时触发保存离线同步任务。同时,仍保留数据传输侧的新建、批量新建、编辑任务的入口。
- 离线同步任务提交的入口由数据传输侧移至离线开发,不再需要在数据传输提交上线任务。离线开发任务提交上线任务包时,会同步将引用的离线同步任务也提交上线。
- 删除离线开发任务时,支持选择是否一并删除引用的离线同步任务。同时,仍保留数据传输侧的删除任务的入口。
功能使用注意事项:
- 如果同一离线同步任务被多个离线开发任务,保存任务:任一离线开发任务保存,引用的离线同步任务即会保存。
- 如果同一离线同步任务被多个离线开发任务,提交任务:任一离线开发任务提交上线,引用的离线同步任务即会提交上线。同时,会给其余离线开发任务负责人发送通知,提醒任务线上模式发生变更。
- 如果同一离线同步任务被多个离线开发任务,删除任务:删除离线开发任务时,不支持删除引用的离线同步任务。仅当离线同步任务未被离线开发任务引用时,方可删除离线同步任务。
2.【离线】数据来源新增数据源类型:WebService
- 功能介绍:
- 数据来源新增数据源类型:WebService
3.【离线】数据来源为Hive和StarRocks时,支持根据安全中心数据识别结果自动推荐来源表字段和脱敏规则
- 功能介绍:
- 数据来源为Hive和StarRocks时,点击“自动推荐”按钮,会在数据脱敏配置中自动添加安全中心数据识别结果中识别的来源表敏感字段和脱敏规则。
- 如数据识别结果中仅包含敏感字段、敏感类型,未确认脱敏规则,则会从安全中心脱敏规则列表中自动推荐该敏感类型对应的脱敏规则,如同一敏感类型存在多个脱敏规则则取引用数最多的脱敏规则。
- 如数据识别结果中仅包含敏感字段,未确认敏感类型和脱敏规则,则仅在脱敏配置中自动添加敏感字段,脱敏规则由用户手动选择。
- 页面形式批量新建任务-数据脱敏中,支持基于单个来源表自动推荐,支持批量自动推荐。
功能优化
1.【离线】数据去向为PostgreSQL时,新增写入规则:On conflict key update
- 功能介绍:
- On conflict key update的写入规则,指遇更新键冲突,更新原记录,未映射字段值不变。
- 更新键支持多选,建议选择主键或区分度较大的字段作为更新键。
- 仅当版本>9.5时,该写入规则可用。
2.【离线】PostgreSQL作为来源和去向新增支持版本:12.8
3.【离线】Greenplum作为来源和去向新增支持版本:6.16
4.【离线】去向为Doris和StarRocks时,写入规则新增支持:Merge、Delete
- 功能介绍:
- 导入方式为stream load时:如写入规则为Merge,会删除满足删除条件的原记录,追加不满足删除条件的记录;如写入规则为Delete,会删除与导入数据 key 列值相同的原记录。
- 导入方式为borker load时:如写入规则为Merge,会删除表中满足删除条件的原记录,追加写入其余记录;如写入规则为Delete,本次导入的所有数据皆为删除数据。注意:仅当表类型为Unique Key 模型表,可以选择Merge和Delete。
5.【离线】来源和去向为clickhouse时,适配认证方式为SSL认证的Clickhouse数据源
6.【离线】来源为API时,字段解析功能不过滤空字段
7.【离线】页面形式批量新建任务,数据来源新增支持Clickhouse数据源
8.【离线】来源为clickhouse时,适配SQL模式
9.【离线】发布中心“参数组引用”和“Hive表检测“的检测逻辑优化
- 功能介绍:
- 如任务引用的参数组在接收方不存在时,会再检测发布包内是否存在该参数组,如发布包中也不存在则强规则检测不通过。
- 如任务引用的Hive表在接收方查询时,发现接收方存在同名库、不存在同名表、需要新建,会再检测发布方的发布包内是否存在同名Hive库表,如发布包中也不存在则则弱规则检测不通过。
版本:v3.19.0
新增功能
1.【离线】数据去向为Doris和StarRocks时,支持快速新建表
- 功能介绍:
- 数据去向为Doris和StarRocks时,支持快速新建表
- 功能使用注意事项
- 在配置管理-快速创建表配置中,支持针对Doris和StarRocks设置是否启用模型设计中心的ODS层表名规则和字段类型映射规则。
2.【离线】来源为关系型数据库、去向为StarRocks时,来源表结构变更策略针对新增字段支持:去向表自动新增该字段,建立映射并同步数据
- 功能使用注意事项
- 仅当数据源登记的账号有StarRocks表新建字段的权限时,方可自动新增字段,否则任务运行会报错。
3.【实时】数据去向新增支持数据源类型:Doris
- 功能介绍:
- 数据去向新增支持数据源类型:Doris,适配版本为:1.1、1.2、2.0
4.【实时】数据去向为Iceberg和StarRocks时,支持快速新建表
- 功能介绍:
- 数据去向为Iceberg和StarRocks时,支持快速新建表和批量新建去向表。
功能优化
1.【离线】数据去向为clickzetta时,支持配置重试参数
2.【离线】HBase作为来源和去向新增支持2.2版本
3.【离线】数据来源为API且请求方式为post时,增加Params配置项
- 功能介绍:
- 数据来源为API且请求方式为post时,增加Params配置项,支持将参数拼接到url上
4.【离线】数据来源和去向为Doris时,适配2.1版本
5.【离线】数据来源和去向为Doris时,支持读写名称含中文的字段
6.【离线】数据来源和去向为Greenplum时,适配7.1版本
Bug修复
1、修复实时同步任务-设置报警-报警组下拉列表获取失败的问题
版本:v3.18.0
新增功能
1.【离线】针对非Hadoop环境,离线同步任务的任务引擎支持DataX引擎
- 功能介绍:
- Hadoop环境下,离线同步任务引擎支持Spark引擎;非Hadoop环境下,离线同步任务引擎支持DataX引擎。
- 任务引擎为DataX引擎时,支持的数据源类型包含:Doris、MySQL、Oracle、PostgreSQL、SQLServer、StarRocks、TeleDB。
- 功能使用注意事项
- 客户环境部署时,会根据客户环境部署相应环境的任务引擎。
2.【实时】数据去向支持StarRocks
- 功能介绍:
- 数据去向支持StarRocks,支持的版本为:1.19、2.4、3.2,支持的认证方式为:用户名密码认证
- 功能使用具体步骤
- 功能入口:
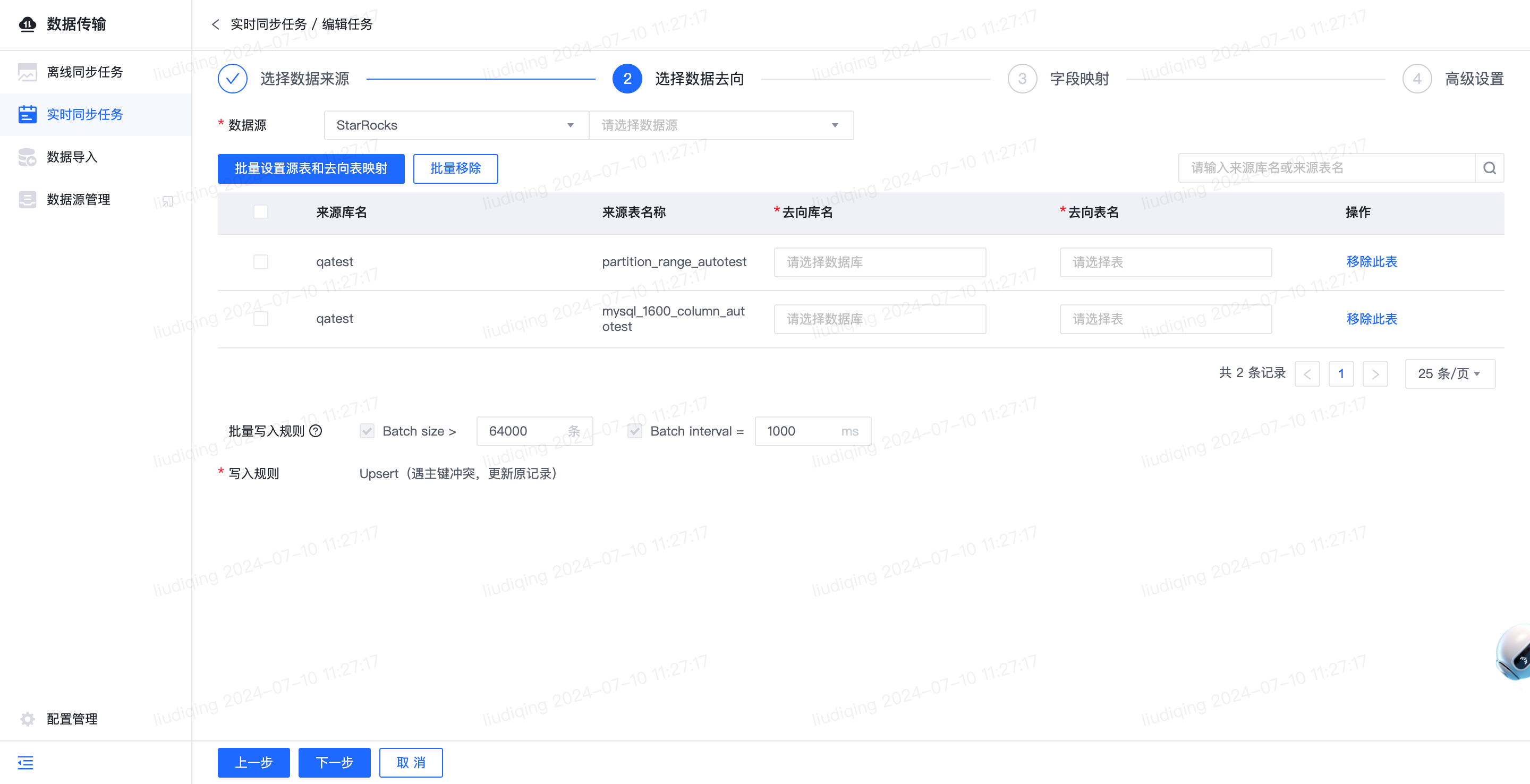
- 功能入口:
3.【离线】数据来源为FTP、协议为SFTP、文件格式为text、csv、excel、xml、json、dbf时,支持设置并发读取和并发数
- 功能介绍:
- 此前的版本中,数据来源为FTP、协议为SFTP时,为提升传输性能,结构化读取时默认会开启并发读取,每个文件会分别使用一个线程进行数据抽取。此版本进行了功能优化,文件格式为text、csv、excel、xml、json、dbf时,支持由用户设置是否开启并发读取,以及开启并发读取时的并发数。
- 如读取多个FTP文件,开启并发读取开关后会使用多线程进行数据抽取,线程并发数由“并发数”配置指定;如读取单个FTP文件,只能使用单线程进行数据抽取,并发读取开关不生效。
- 并发数的设置:如选择“文件数”,指每个文件会分别使用一个线程进行数据抽取;如选择“自定义”,实际线程并发数=min(文件数,填写的并发数)。
- 此功能不影响历史任务,历史任务仍保持原设置:开启并发读取、并发数为文件数。
- 如需针对平台内所有SFTP任务关闭并发读取,可联系技术支持在EasyOps进行全局配置:ndi.spark.spark-conf.spark.transmit.reader.ftp.sftpConnectionMultiplexing=true。
功能优化
1.【离线】数据去向为PostgreSQL时,写入规则支持copy
- 功能介绍:
- 数据去向为PostgreSQL时,写入规则支持copy(拷贝数据),大数据量时推荐使用。
2.【离线】数据来源为Clickzetta时,支持并发读取
- 功能介绍:
- 数据来源为Clickzetta时,支持并发读取。
3.【实时】数据去向为Kafka时,新建Topic功能放宽topic名称限制
- 功能介绍:
- 创建Topic时,原来会限制仅允许输入小写字母、数字、下划线、参数组参数,topic名称长度限制最多64个字符,导致部分情况下影响使用。此版本改为:允许输入大小写字母、数字、“_”、“-”、“.”、参数组参数。
版本:v3.17.0
新增功能
1.【离线】去向为Iceberg时支持快速创建表
- 功能介绍:
- 离线同步任务数据去向为Iceberg时,支持快速新建Iceberg表。
- 去向表的字段名称默认与来源表字段名称保持一致,去向表的字段类型默认映射来源表的字段类型,字段类型映射规则可在数据传输-配置管理-快速创建表配置-字段类型映射规则进行自定义配置。
- 功能使用注意事项
- 仅来源为关系型数据库和Maxcompute时去向支持快速新建Iceberg表。
- 功能使用具体步骤
- 功能入口:
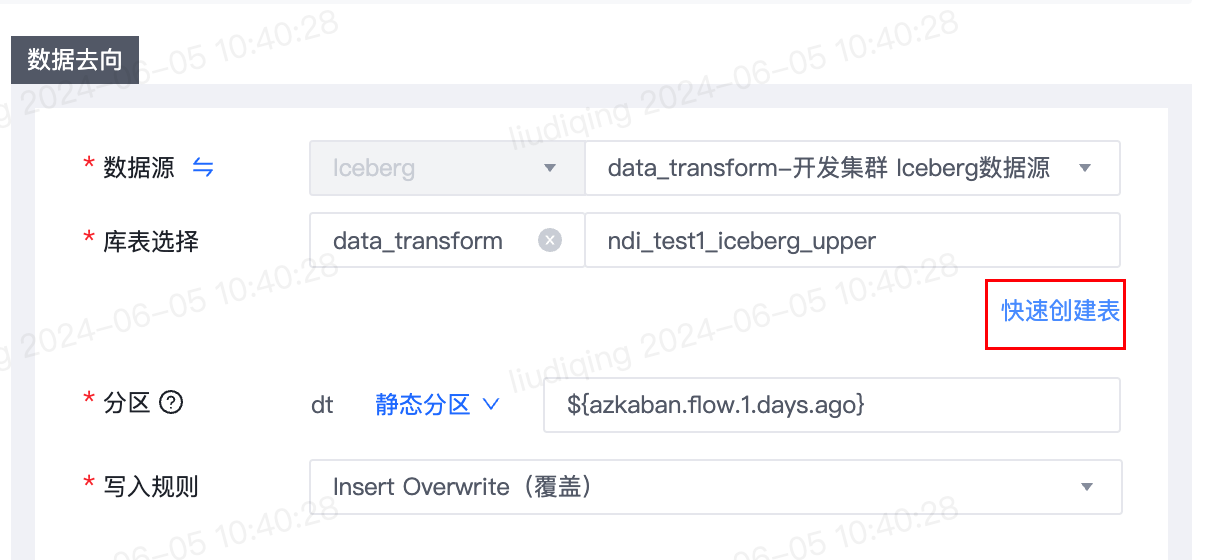
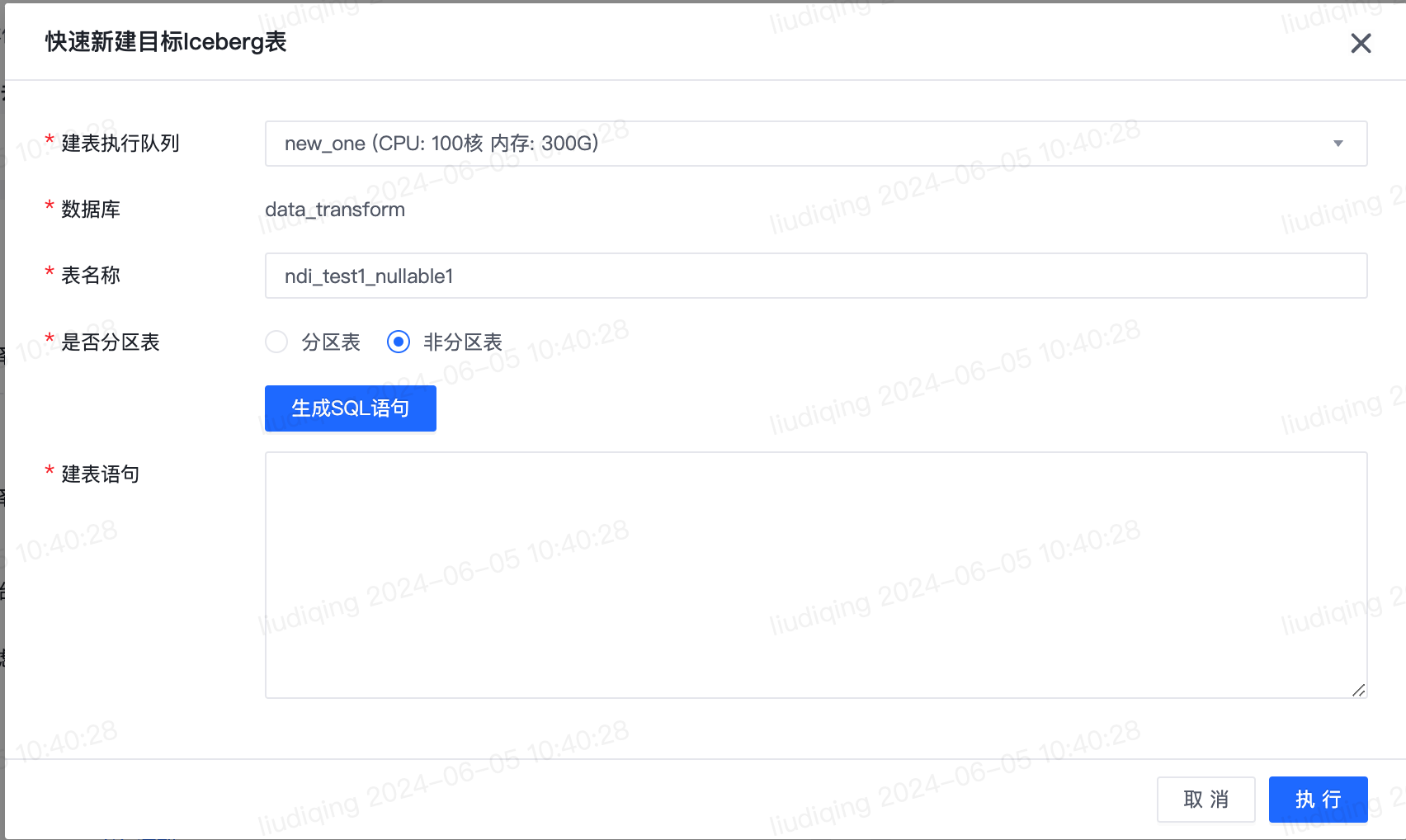
- 功能入口:
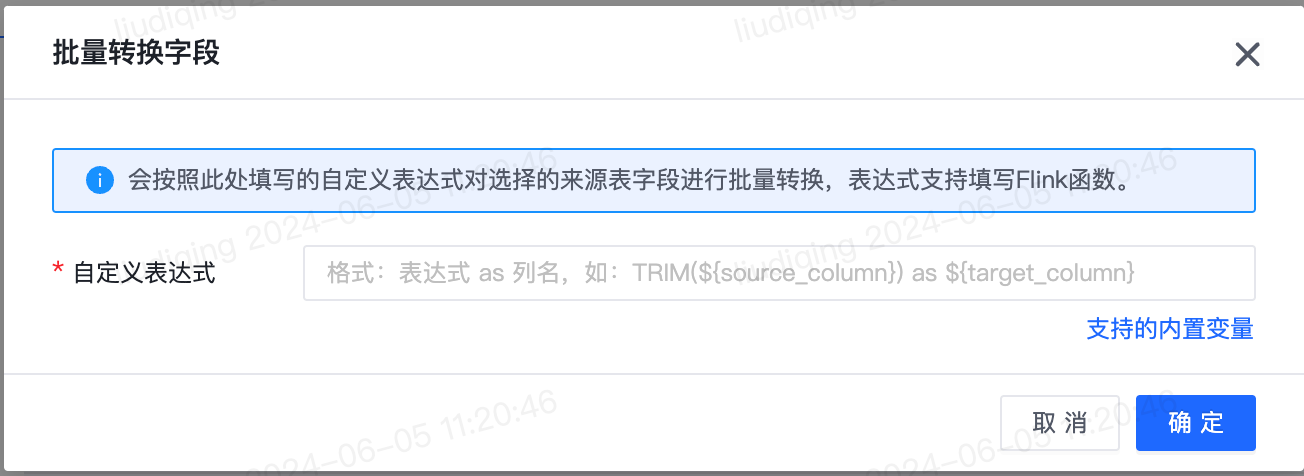
2.【实时】来源为关系型数据库、去向为除Kafka外的数据源时,支持批量转换来源表字段
- 功能介绍:
- 来源为关系型数据库、去向为除Kafka外的数据源时,支持批量转换字段。使用方式是批量勾选来源表字段(可跨页勾选),并填写自定义表达式,会根据填写的自定义表达式对选择的来源表字段批量转换为自定义表达式。
- 自定义表达式支持填写Flink函数。支持的内置变量为${source_column}和${target_column},分别表示来源表字段名称和去向表字段名称。
- 功能使用注意事项
- 系统预置了去除前后空格、字段类型转换、空值替换等常用的自定义表达式,也支持自定义输入自定义表达式。
- 格式:表达式 as 列名。如:TRIM(${source_column}) as ${target_column}
- 功能使用具体步骤
- 功能入口:
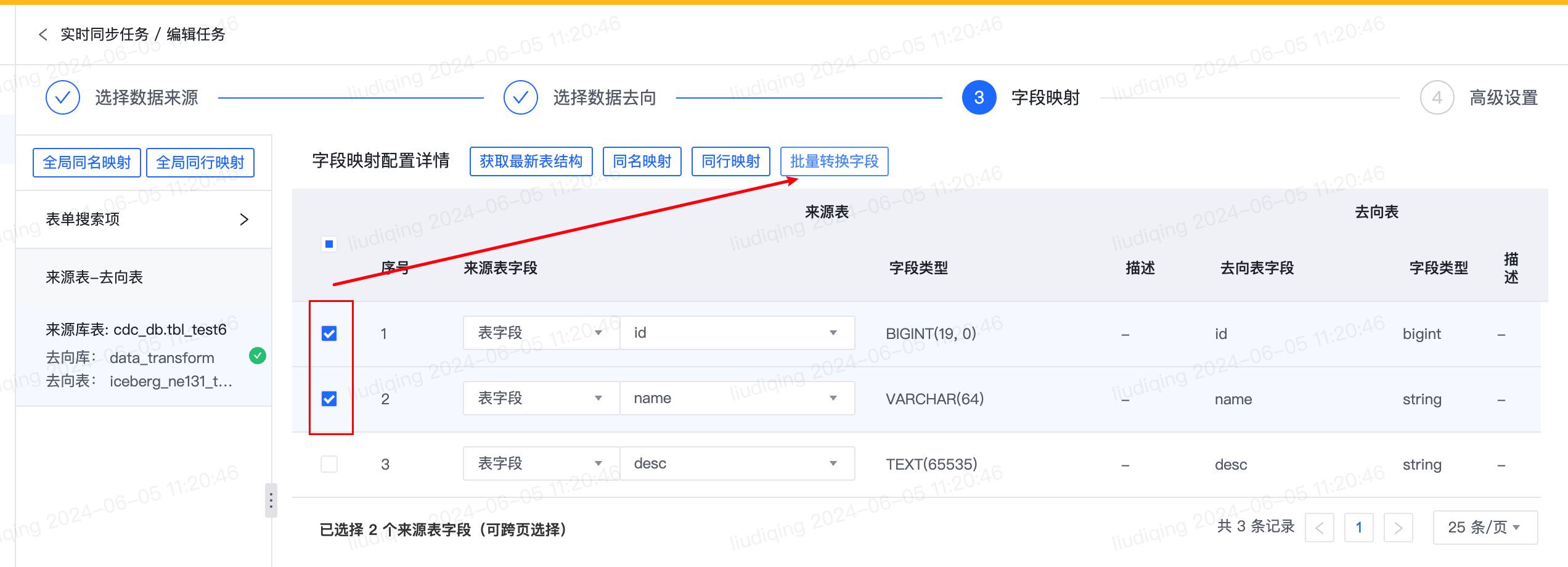
- 功能入口:
功能优化
1.【离线】StarRocks适配3.2版本
- 功能介绍:
- StarRocks适配3.2版本,“源系统账号映射”中账号认证方式支持账号密码认证和LDAP认证 2.【离线】Clickzetta驱动替换,兼容http协议
版本:v3.16.0
新增功能
1.【离线】任务目录新增支持自定义目录,并支持切换自定义目录和系统目录
- 功能介绍:
- 离线同步任务原已支持系统目录(按照数据来源分类),此版本新增支持自定义目录。 自定义目录功能包含:支持目录的新建、重命名和删除,支持将任务保存在指定目录下,支持按照目录结构展示任务。
- 功能使用注意事项
- 支持切换系统目录和自定义目录,并支持由项目负责人和项目管理员设置默认目录。默认目录的作用:当前项目-集群的所有用户进入任务列表页时,目录树会按默认目录的目录结构进行展示。
- 自定义目录最多支持新建三级目录。已创建的历史任务的保存位置默认为“/根目录”,在列表页会展示在“未分组”目录下。如需修改历史任务的保存位置,可通过“批量修改保存位置”来批量修改任务的保存位置。
- 自定义目录权限:仅支持由项目负责人、项目管理员新建目录、删除目录和重命名目录。如目录下存在子目录或任务,则目录不可删除。
- 离线同步任务导入时,会判断导入方是否存在导出方任务保存位置对应的目录,如导入方存在该目录的话任务的保存位置保持不变,会继续放在该目录下;如导入方不存在该目录,则自动在接收方先新建目录,再导入任务。
2.【离线】GaussDB、Oceanbase、API、Doris适配Spark3.3
3.【实时】任务目录新增支持系统目录,并支持切换自定义目录和系统目录
- 功能介绍:
- 实时同步任务原已支持自定义目录,此版本新增支持系统目录(按照数据来源分类)。
- 功能使用注意事项
- 支持切换系统目录和自定义目录,并支持由项目负责人和项目管理员设置默认目录。默认目录的作用:当前项目-集群的所有用户进入任务列表页时,目录树会按默认目录的目录结构进行展示。
- 系统目录(按照数据来源分类)一级目录为任务数据来源的数据源类型,二级目录为任务数据来源的数据源名称。
4.【实时】数据来源新增PostgreSQL
- 功能介绍:
- 任务类型为多表到多表同步时,数据来源新增PostgreSQL。
- 功能使用注意事项
- 仅插件版本为2.x时支持此功能。
5.【实时】数据去向新增SQLServer
- 功能使用注意事项
- 仅插件版本为2.x时支持此功能。
6.【实时】日志支持展示启动、TM、JM、停止日志
- 功能介绍:
- 实时同步任务原查看日志时仅支持查看启动日志。实时任务停止后无法再次查看该次运行的Flink UI界面和TM日志,对问题排查非常不利,需要提供任务停止后的相关任务信息特别是日志信息进行问题定位。故此版本对日志功能进行增强,支持展示启动、TM、JM、停止日志。
- 功能使用注意事项
- 底层会设置日志定期清理策略。如日志已过期,则查看日志时会提示日志过期。
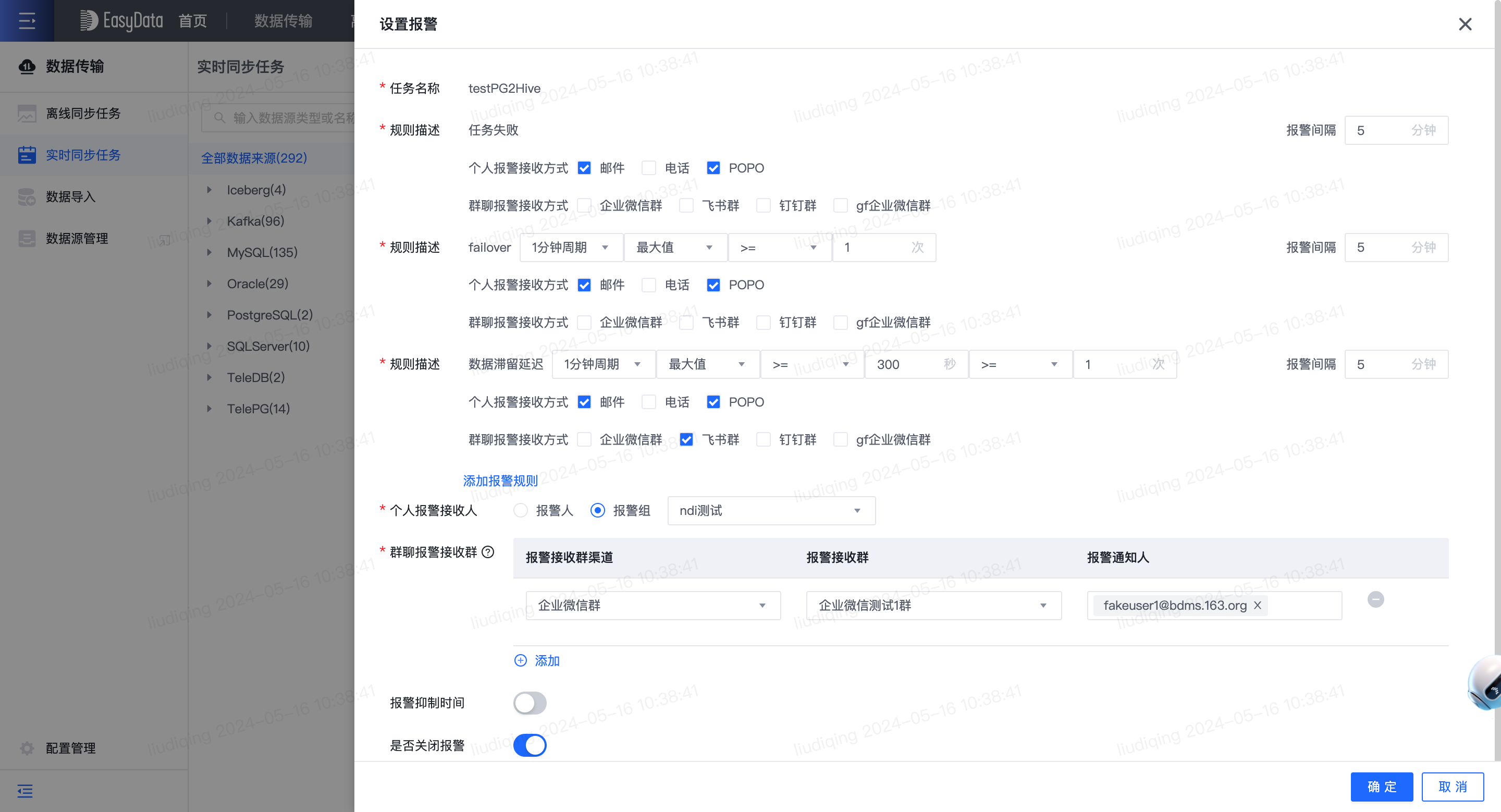
7.【实时】报警支持群聊报警
- 功能介绍:
- 当用户环境已配置群聊报警插件(如:企业微信群、钉钉群)时,实时同步任务设置报警时支持群聊报警。
- 针对各报警规则,可选择群聊报警接收方式,并选择报警接收群和报警通知人。群聊报警时,会向配置的群聊发送报警时并@报警接收人。
- 注意:请保证报警接收人在群内,否则仅会向群发送消息,不会@报警接收人。此外,@报警接收人需对应报警渠道支持该功能。
- 功能使用具体步骤
- 功能入口:
- 功能入口:
功能优化
1.【离线】HBase作为来源和去向时新增支持2.1版本、Kerberos认证
- 功能使用注意事项
- 需要打通平台内置集群和HBase所在集群的互信后方可使用此功能。
- 执行任务时,会使用任务执行账号访问该HBase。
2.【离线】Kudu作为来源和去向时新增支持1.10版本、Kerberos认证
- 功能使用注意事项
- 需要打通平台内置集群和Kudu所在集群的互信后方可使用此功能。
- 执行任务时,会使用任务执行账号访问该Kudu。
3.【离线】批量新建任务-页面形式新建 选择来源表组件优化
- 功能使用具体步骤
- 功能入口:
- 功能入口:
4.【离线】数据去向为HCP时,非结构化写入的技术方案优化:由Hadoop distcp改为Spark distcp,不依赖于Hadoop版本
5.【实时】来源为MySQL时支持自定义参数source.fields.convert-tinyint-one-boolean.enabled
- 功能介绍:
- 参数名称:source.fields.convert-tinyint-one-boolean.enabled,用于控制MySQL表字段类型为tinyint时写入去向的字段类型。默认值为true,即按照boolean类型写入数据去向;值为false时,会按照tinyint类型写入数据去向。
6.【实时】任务选择参数组的交互优化
- 功能介绍:
- 修改参数组后,不自动清空已选的来源表列表。如需调整来源表,可点击“刷新”图标获取最新来源表并重新选择。
版本:v3.15.0
新增功能
1.【离线+实时+数据导入】实时同步任务和数据导入对接安全中心功能权限,离线同步任务由安全中心旧版功能权限迁移至新版功能权限
- 功能介绍:
- 离线同步任务、实时同步任务、数据导入模块的功能权限对接安全中心功能权限。功能权限配置入口在安全中心-安全管理-角色管理-项目级-数据传输。
- 功能使用注意事项
- 默认仅任务负责人和安全中心授予任务操作权限的用户可操作任务。此外,安全中心可配置是否默认给项目负责人和项目管理员预置任务操作权限。
- 离线同步任务的功能权限原配置入口在安全中心-安全管理-权限管理-功能权限模块,此次配置入口变更系统会自动迁移权限数据。
- 各操作的功能权限要求详见数据传输-功能权限整体说明章节。
2.【离线】离线同步任务来源和去向新增数据源类型:Clickzetta
- 功能介绍:
- 离线同步任务来源和去向新增数据源类型:Clickzetta
- 功能使用注意事项
- 数据去向为Clickzetta时,由于Clickzetta提供的SDK限制,暂不支持int8字段类型。
3.【实时】实时传输对接安全中心审计日志
功能优化
1.【离线】Clickhouse作为来源和去向时新增支持22.3版本
2.【离线+实时】数据来源为Kafka时支持指定GroupID是由系统生成还是自定义设置groupid
3.【离线】Hive作为来源和去向时新增支持3.1.0版本、Simple认证
版本:v3.14.0
新增功能
1.【实时】数据来源为MySQL时支持针对来源表结构变更发送报警
- 功能介绍:
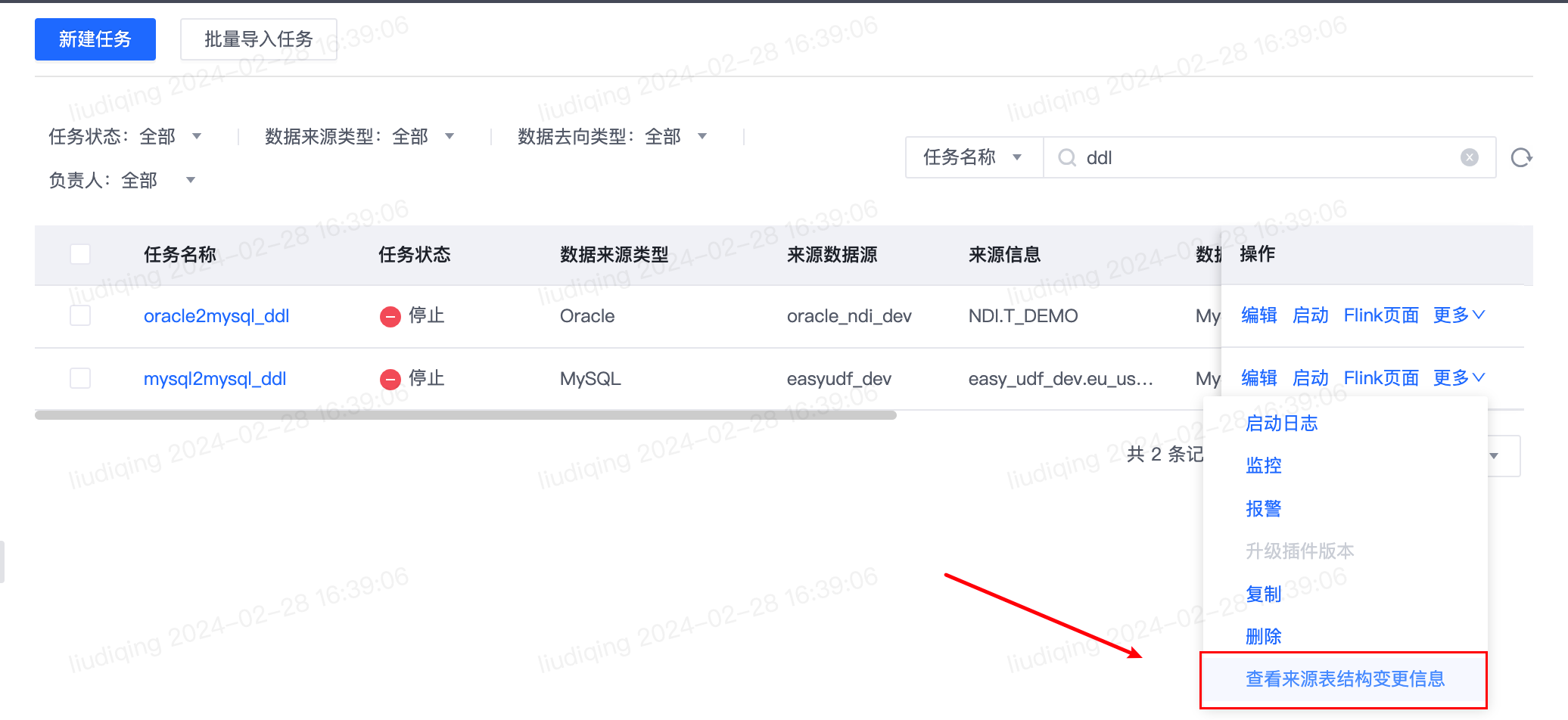
- 实时同步任务数据来源为MySQL时,针对来源表新增字段、删除字段、修改字段三类表结构变更场景,支持配置是否发送报警。此外,针对数据来源为MySQL的任务,支持前往“查看来源表结构变更信息”页面查看表结构变更相关具体信息。
- 来源表结构变更采集范围:
- 任务起始位点为全量初始化时,采集任务开始运行后来源表产生的DDL日志信息。
- 任务执行增量同步时,采集从传输起始位点开始来源表产生的DDL日志信息。
- 功能使用注意事项
- 如果同一条SQL语句中同时对应于多项DDL变更,目前无法完全准确识别表结构变更。示例:ALTER TABLE ndi.t_rg_source_table_change_strategy_02 modify COLUMN addcolumn_rename VARCHAR(200), modify COLUMN name VARCHAR(300)
- 功能详细使用步骤
- 数据传输-配置管理-实时同步任务-来源表结构变更策略:支持按照项目粒度配置任务表结构变更的报警接收方式和报警接收人
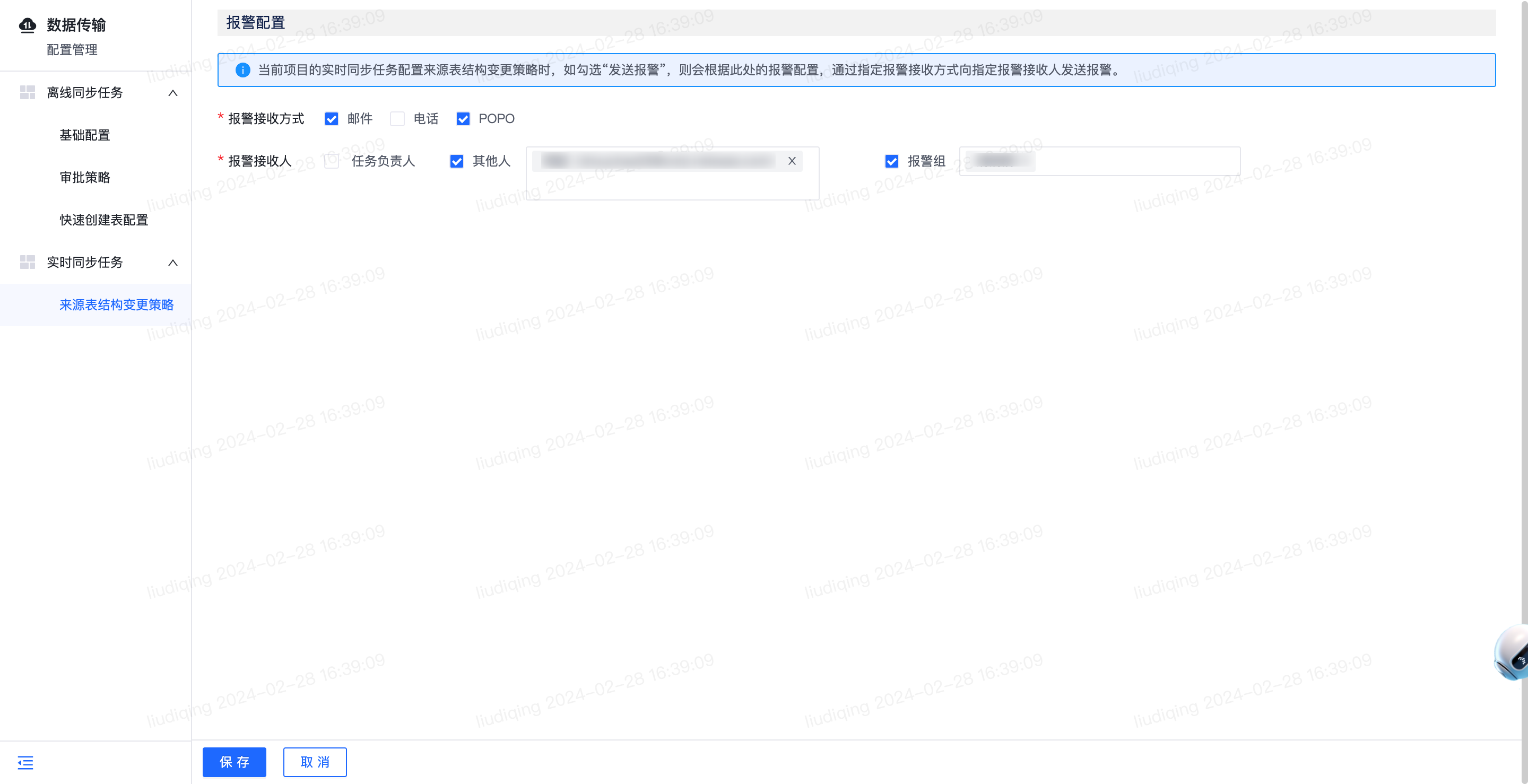
- 实时同步任务详情页:支持勾选来源表新增字段、删除字段、修改字段是否需发送报警
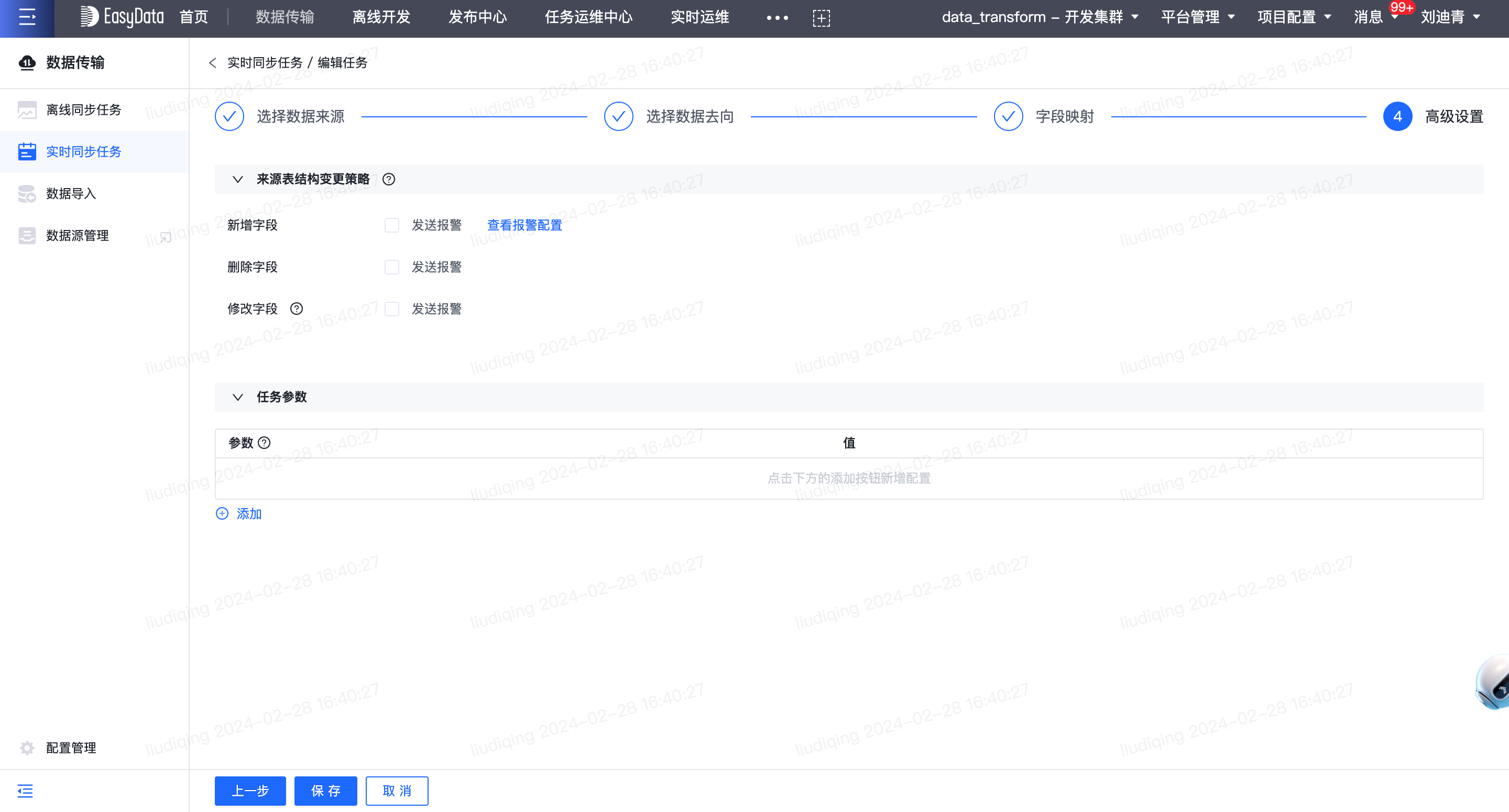
- 实时同步任务-查看来源表结构变更信息页面:支持查看任务的来源表结构变更具体信息。
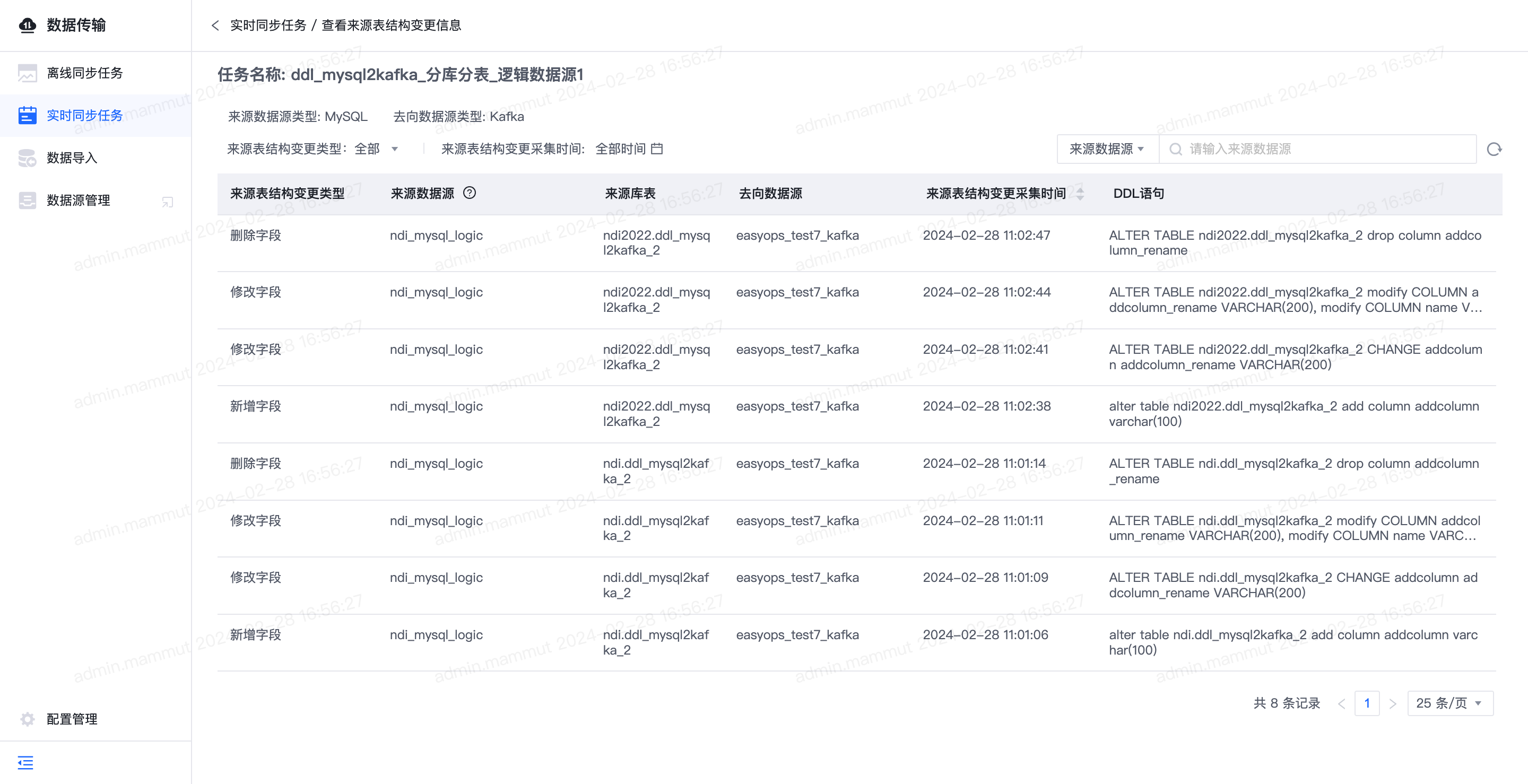
- 数据传输-配置管理-实时同步任务-来源表结构变更策略:支持按照项目粒度配置任务表结构变更的报警接收方式和报警接收人
2.【实时】支持任务目录管理
- 功能介绍:
- 实时同步任务模块支持目录的新建、重命名和删除,支持将任务保存在指定目录下,支持按照目录结构展示任务。
- 功能使用注意事项
- 最多支持新建三级目录。
- 已创建的历史任务的保存位置默认为“/根目录”,在列表页会展示在“未分组”目录下。如需修改历史任务的保存位置,可通过“批量修改保存位置”来批量修改任务的保存位置。
- 仅支持由项目负责人、项目管理员新建目录、删除目录和重命名目录。
- 如目录下存在子目录或任务,则目录不可删除。
- 实时任务导入时,会判断导入方是否存在导出方任务保存位置对应的目录,如导入方存在该目录的话任务的保存位置保持不变,会继续放在该目录下;如导入方不存在该目录,则自动在接收方先新建目录,再导入任务。
3.【离线】支持读写版本为2.1.x-CDH6.3.x、认证方式为Kerberos认证的Hive数据源
- 功能介绍:
- 支持读写版本为2.1.x-CDH6.3.x、认证方式为Kerberos认证的Hive数据源
- 功能使用注意事项
- 仅当用户环境部署Spark3、且已打通平台内置的NDH Hive和该CDH Hive的互信后方可使用此功能。
- 执行任务时,会使用任务执行账号访问该CDH Hive。
功能优化
1.【实时】字段映射页面视觉优化
版本:v3.13.0
新增功能
1.【离线】支持基于Excel模板批量新建离线同步任务
- 功能介绍:
- 支持基于Excel模板批量新建离线同步任务。
- 数据来源支持的数据源类型包含:DB2、DM、HANA、MySQL、Oracle、PostgreSQL、SQLServer、TDSQL、TiDB、VastBase G100、Vertica,去向数据源类型默认为:Hive,数据源名称默认为:当前项目-当前集群 Hive数据源。任务仅支持向导模式,不支持使用逻辑数据源,同一任务不支持填写多张来源表。
- 表建立方式值为创建新表时,批量新建任务前会自动建表,Hive表的字段名称与来源表字段名称相同,字段类型根据配置管理-快速创建表配置-字段类型映射规则映射,分区字段名称使用Excel中填写的分区字段名称,分区字段类型默认为string。
- 功能使用注意事项
- 单次最多可新建1000个任务。
- 仅支持上传“.xls”“.xlsx”格式文件,文件大小不超过 30 MB。
- 去向Hive表最多可支持两级分区。
- 功能详细使用步骤
- a.功能入口:

- b.使用流程:
- 1)点击”下载模板“,下载任务模板的Excel文件,并按照模板要求在Excel中填写任务信息。

- 2)点击”上传文件“按钮,上传Excel文件。文件解析中,请不要刷新/离开当前页面,或关闭浏览器,否则批量新建任务会失败。
上传文件后,会检测Excel填写内容是否符合要求,如不符合要求可在“检测未通过原因”列查看具体原因。仅当所有任务均检测通过后才可批量导入任务

- 3)所有任务均检测通过后,点击“导入”按钮,开始新建离线同步任务。
导入完成后,可查看导入结果。针对导入成功的任务,支持批量运行任务和批量新建离线开发任务;针对导入失败的任务,支持查看导入失败原因。
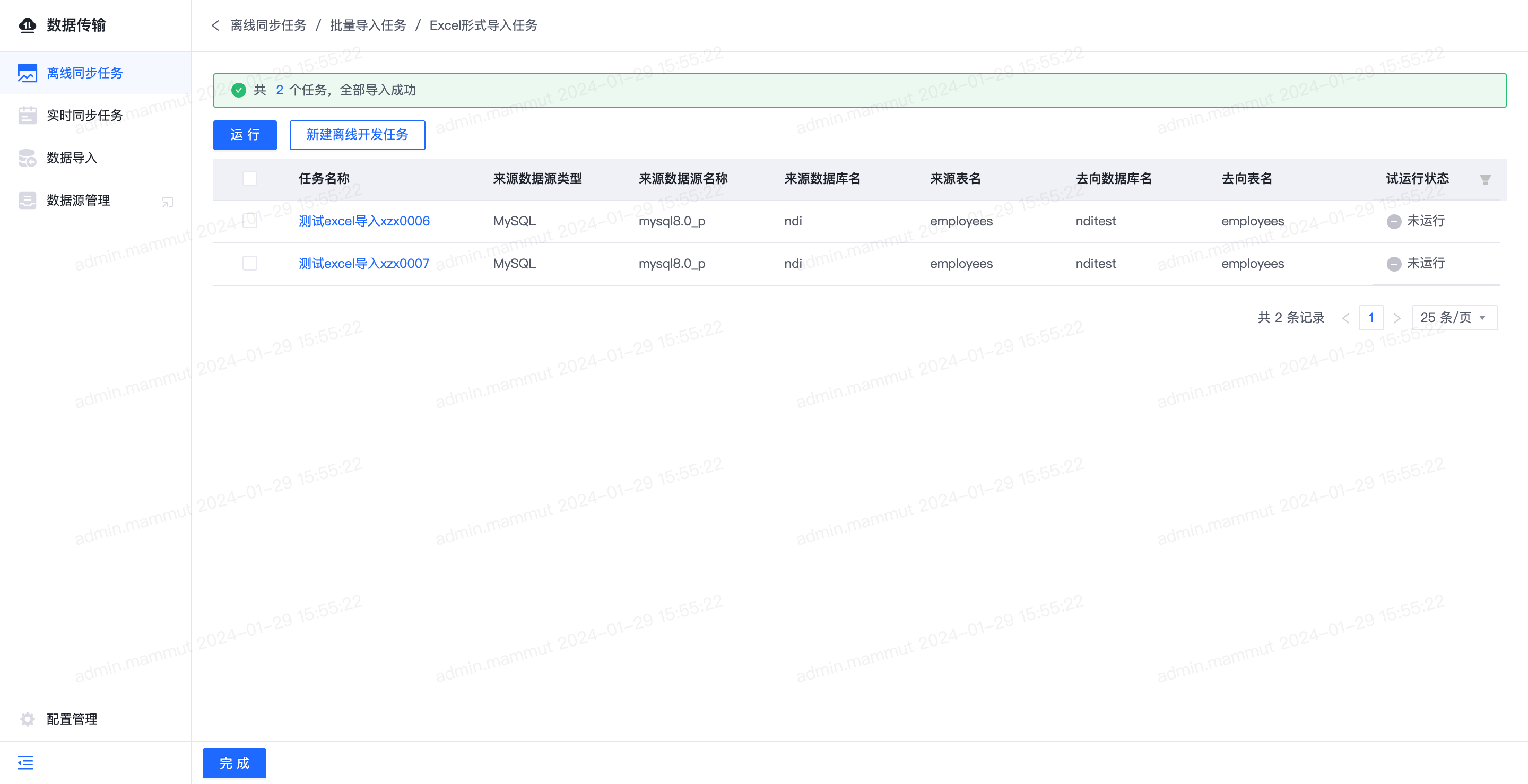
- 1)点击”下载模板“,下载任务模板的Excel文件,并按照模板要求在Excel中填写任务信息。
- a.功能入口:
2.【离线】OceanBase作为数据来源支持SQL模式
- 功能介绍:
- OceanBase作为数据来源支持SQL模式
- 功能详细使用步骤
- a.功能入口:

- a.功能入口:
3.【整体】对接安全中心资产整体转交
- 功能介绍:
- 安全中心支持按照项目粒度转交离线同步任务和实时同步任务的负责人,转交后被转交人权限同步删除。
- 功能详细使用步骤
- a.功能入口:
- a.功能入口:
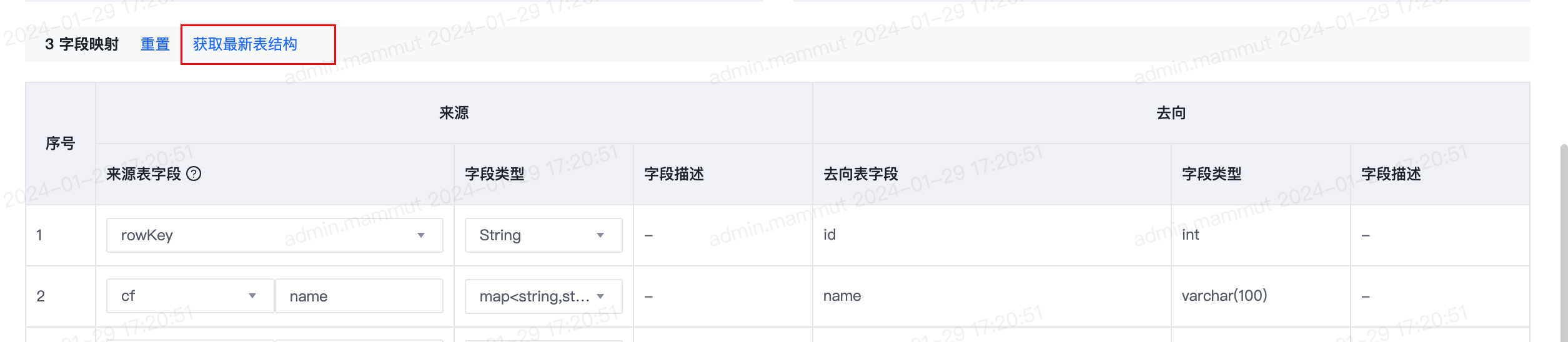
4.【离线】来源或去向为结构化数据源时字段映射支持获取最新表结构
- 功能介绍:
- 此前,来源和去向均为结构化数据源时,字段映射已支持“获取最新表结构“的功能,能针对来源表和去向表新增字段、删除字段、修改字段类型、字段顺序调整的表结构变更做出提示并自动进行字段映射调整。
- 此版本进行了功能增强。仅来源为结构化数据源时,支持对来源表的表结构变更做出提示并自动进行字段映射调整;仅去向为结构化数据源时,支持对去向表的表结构变更做出提示并自动进行字段映射调整。
- 来源表:1)新增字段:不改变已有的字段映射列表,下拉选项中增加新增字段;2)删除字段:如果被删除的字段原已在列表中被选中,则通知提醒框中进行报错提示,不阻塞保存任务;3)字段类型变更:更新“类型”列该字段的字段类型;4)字段顺序变更:字段映射列表中的来源表字段下拉列表按变更后的来源表字段顺序展示,不修改字段映射列表已有配置。
- 去向表:1)新增字段:字段映射列表中新增行,行序号为去向表中该字段的列序号。针对该行的来源表字段,来源数据源类型为HBase时,来源表字段的第一个单选框置为第一个列族,第二个输入框的位置填充去向表字段名称,来源为HBase以外的数据源类型时,来源表字段的输入框的位置填充去向表字段名称。2)删除字段:删除字段映射列表中的对应行;3)字段类型变更:更新“类型”列该字段的字段类型;4)字段顺序调整:字段映射列表中按变更后的去向表字段顺序展示,并保留映射的来源表字段信息。
- 功能详细使用步骤
- a.功能入口:
- a.功能入口:
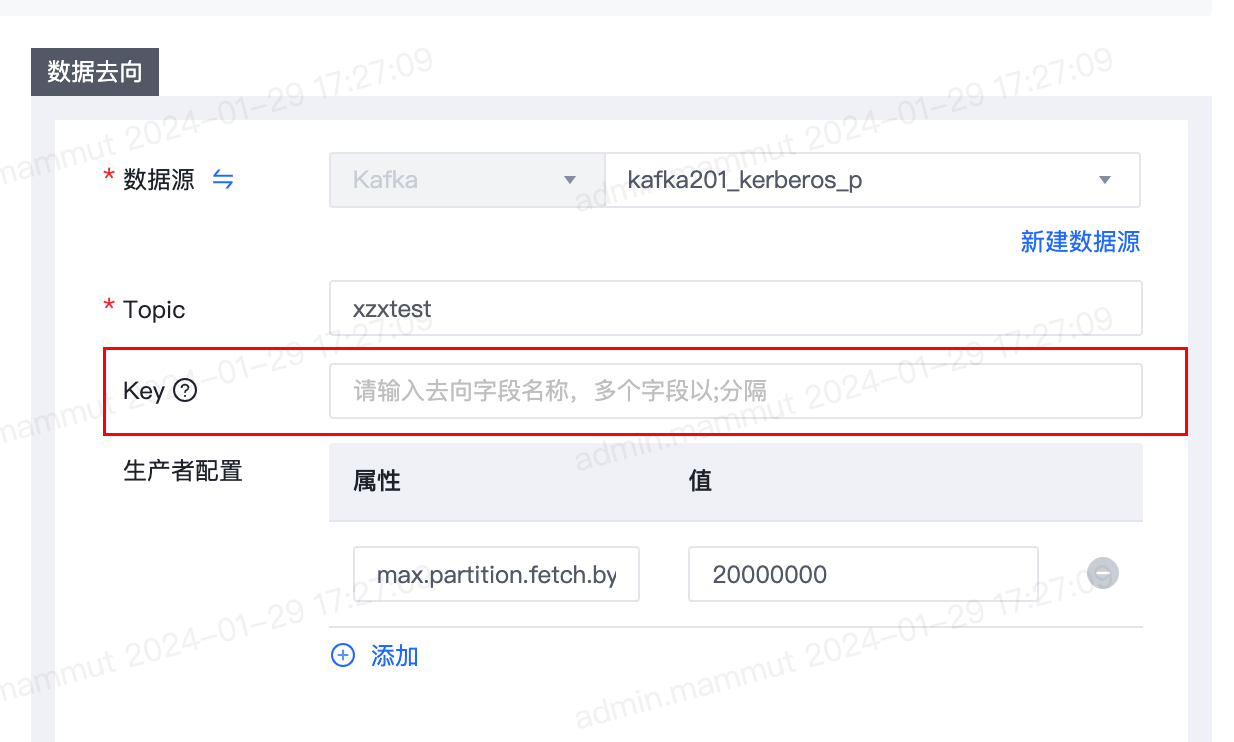
5.【离线】数据去向为Kafka时支持指定key
- 功能介绍:
- 数据去向为Kafka时支持指定key。Key支持填写一个或多个去向字段。如填写多个字段,字段间请以;分隔,写入时会按照json的序列化格式写入Kafka的Key。示例:Key填写id;name,当id值为1、name值为张三时,写入Kafka的Key为:{ "id”:”1”, “name”:”张三” }。
- 如未填写Key,则写入kafka记录Key为null,数据随机写入topic的各个分区中。
- 功能详细使用步骤
- a.功能入口:
- a.功能入口:
6.【实时】数据去向支持Oracle
- 功能介绍:
- 数据去向支持Oracle。
- 功能使用注意事项:
- Oracle字段名称格式限制:仅支持大小写字母、数字、下划线、中划线、$。
- 功能详细使用步骤
- a.功能入口:
- a.功能入口:
功能优化
1.【离线】Oceanbase数据库模式为Mysql时适配版本:3.2.4(企业版)
2.【离线】Doris适配版本:2.0
3.【离线】Tidb适配版本:6.1
4.【离线】任务列表支持按照试运行状态筛选任务
5.【离线+数据导入】支持根据Spark版本控制产品功能展示
版本:v3.12.0
新增功能
1.【离线同步任务】数据来源和去向新增数据源类型:Oceanbase
- 功能介绍:
- 数据来源和去向新增数据源类型:Oceanbase,支持的版本为:Oceanbase for Oracle-3.2.4(企业版)和Oceanbase for MySQL-3.1.1(社区版)。
- 功能使用注意事项
- 作为来源时仅支持向导模式、不支持SQL模式。
- 功能详细使用步骤
- 功能入口:
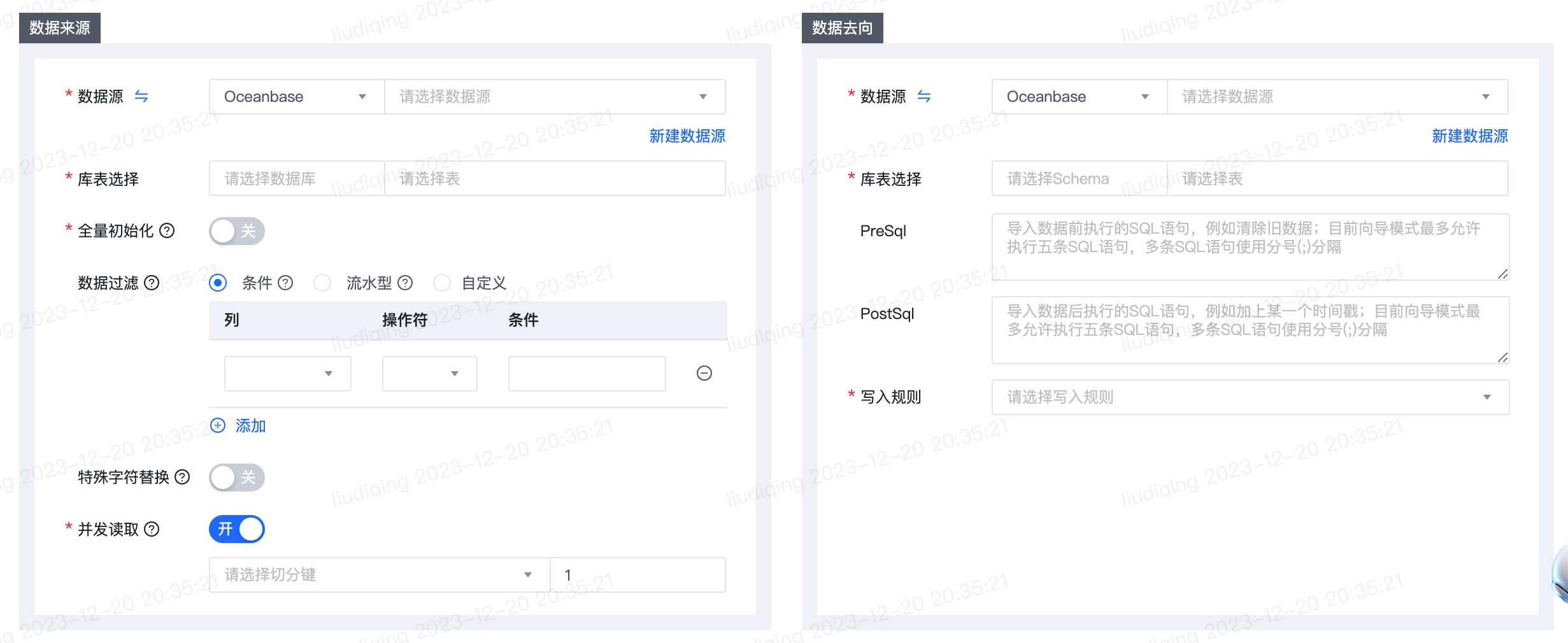
- 功能入口:
2.【实时同步任务】实时同步任务支持批量移交负责人
功能优化
1.【实时同步任务】数据去向为Iceberg时,新增自定义参数:target.delete.to.insert
- 功能介绍:
- Flink的rowkind分为:delete、insert、update-before、update-after。写入数据去向时,会根据rowkind判断该条数据的操作类型。自定义参数值默认为false,值设为ture的效果是:当数据的rowkind为delete时,能将rowkind转换为insert,则按照upsert写入规则写入Iceberg时,会先删除原记录再写入新的记录,则此条delete数据能成功写入iceberg,rowkind是insert,op_type是delete。
- 参数配置位置为任务详情页的高级设置的自定义参数。
2.【整体】数据传输快速创建Hive表,表负责人由项目账号改为执行建表的用户账号
- 功能介绍:
- 为保障数据安全,数据传输快速创建Hive表,表负责人由项目账号改为执行建表的用户账号。
3.【离线同步任务】来源为关系型数据库时,针对数据传输-v3.12.0版本起新建的任务,执行查询sql时列名默认带上引号
- 功能介绍:
- 此功能仅针对新增任务,不影响历史任务运行。
版本:v3.11.0
新增功能
1.【离线同步任务】数据来源和去向新增数据源类型:GaussDB
- 功能介绍:
- 数据来源和去向新增数据源类型:GaussDB,仅支持GaussDB for PostgreSQL,支持的版本为:8.1
- 功能使用注意事项
- 作为来源时仅支持向导模式、不支持SQL模式
- 功能详细使用步骤
- a.功能入口:
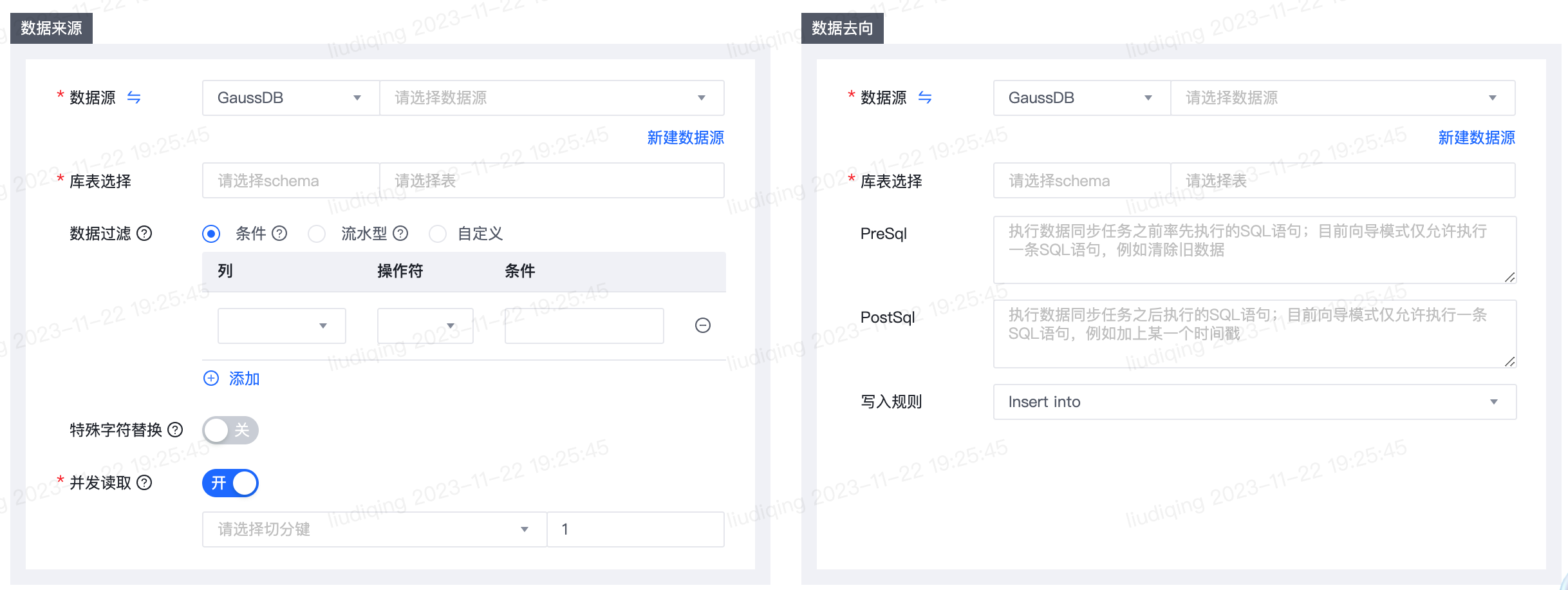
- a.功能入口:
2.【实时同步任务】数据去向新增数据源类型:MySQL
- 功能介绍:
- 数据去向新增数据源类型:MySQL,支持的版本为:5.7、8.0
- 功能详细使用步骤
- a.功能入口:
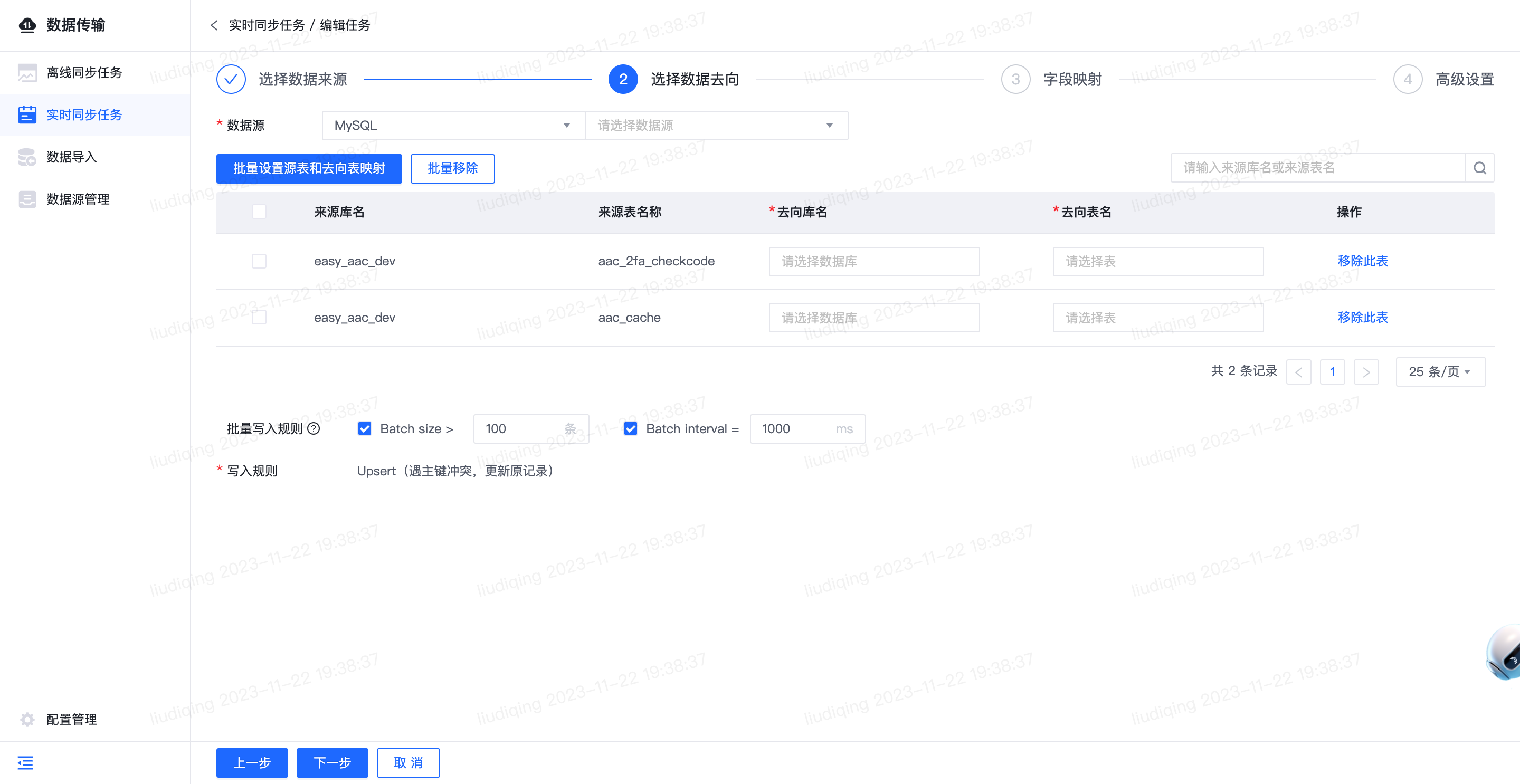
- a.功能入口:
功能优化
1.【离线同步任务+实时同步任务】参数组适配授权项目
- 功能介绍:
- 任务选择引用参数组时,下拉列表仅展示授权给当前项目的参数组。
- 保存任务时,校验已选取的参数组是否授权给当前项目,存在未授权的参数组则不可保存任务。
- 运行任务时,校验已选取的参数组是否授权给当前项目,如存在未授权的参数组则任务运行报错。
2.【离线同步任务】数据去向为Doris和StarRocks、导入方式为stream load时,新增自定义参数,支持设定去向表新增字段时任务是否报错
- 功能介绍:
- 数据去向为Doris和StarRocks、导入方式为stream load时,支持通过任务的高级设置-自定义参数填写:target.loadColumns,值支持填写:true/false,默认值为true,实现去向表新增字段时任务不报错,离线同步任务不向新增字段写入数据。
- 支持通过EasyOps配置参数,实现对平台下的所有去向为Doris和StarRocks、导入方式为stream load的任务生效,参数名称为:ndi.spark.spark-conf.spark.transmit.writer.doris.loadColumns
- 技术实现方案为:stream load的请求header中加入columns属性,放入去向列名。
3.【离线同步任务】数据来源为Iceberg时,数据去向为Vertica时写入规则支持:copy
- 功能使用注意事项
- 仅数据来源数据源类型为:Hive、MySQL、Oracle、PostgreSQL、StarRocks、Doris、Vertica、Iceberg、FTP-text,且特殊字符替换开关关闭时,写入规则支持选择Copy。
4.【离线同步任务】数据来源和去向为Doris时,新增支持版本:1.2
5.【离线同步任务】数据去向为Doris、导入方式为broker load时,支持指定broker
- 功能介绍:
- 如填写broker,则传输任务基于此处指定的broker导入数据;填写多个broker时随机选取活跃的broker;如未填写broker,则使用数据源登记的账号连接数据源查询broker名称。注意:Doris限制仅数据库管理员账号可查询broker名称,请在数据源登记时登记数据库管理员账号,否则将查询失败。
6.【离线同步任务】数据去向为DM,写入规则支持merge into
- 功能介绍:
- Merge into的实现效果为:遇更新键冲突,更新原记录。更新键建议选择主键,选取多个字段联合作为更新键时,仅当字段拼接值冲突时,会更新原记录。
7.【离线同步任务】发布中心发布离线同步任务时,适配资源发布失败策略
- 功能介绍:
- 发布中心发布离线同步任务时,适配资源发布失败策略,用于实现接收方发布实例包发布到开发模式和发布到线上模式时,遇失败资源是自动跳过还是终止发布。
8.【离线同步任务】离线同步任务支持导出线上模式任务
- 功能介绍:支持批量导出线上模式的任务配置
- 功能入口:
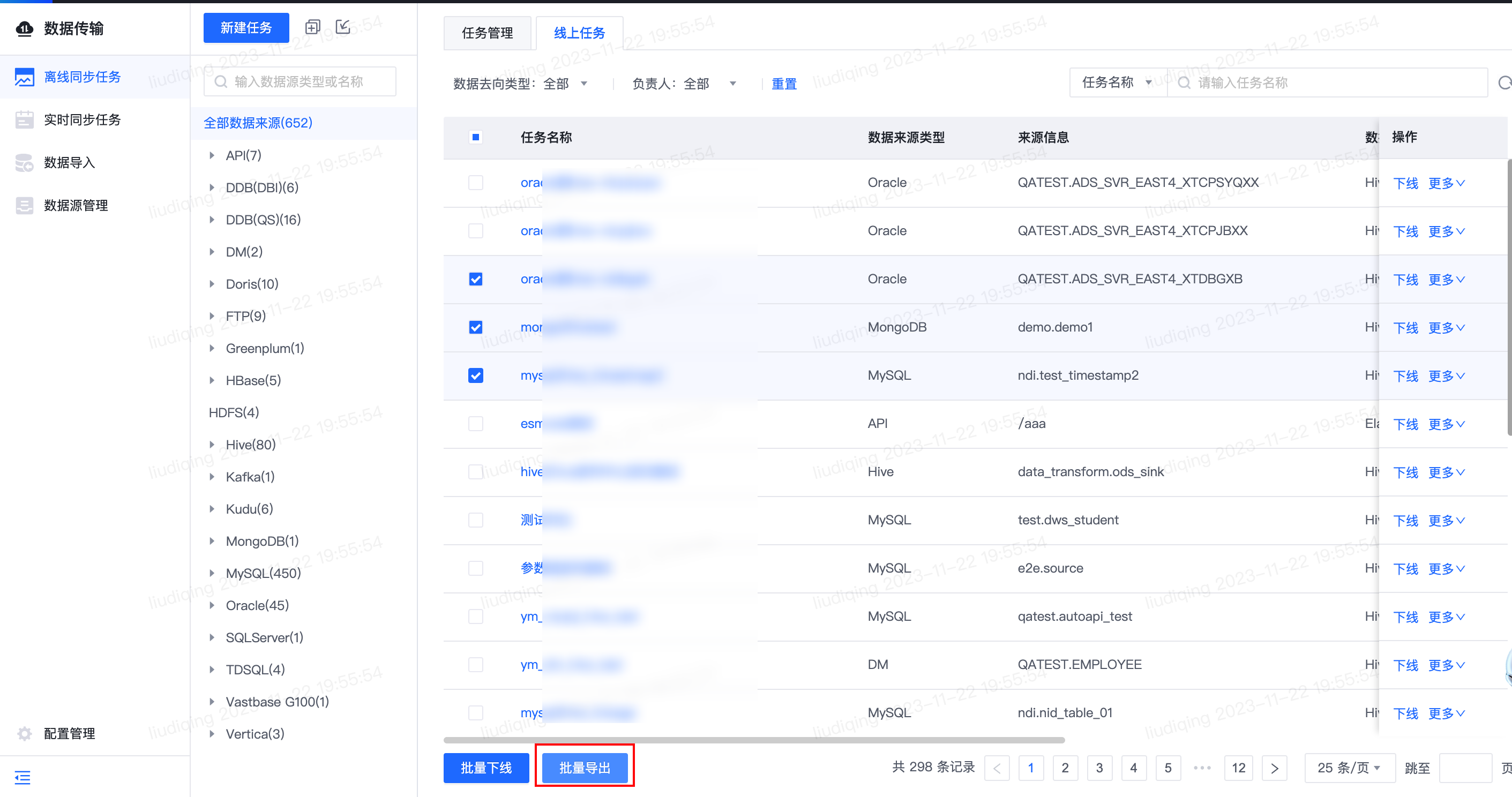
9.【实时同步任务】数据来源-传输起始位点支持参数组参数
- 功能介绍:
- 具体位置含:
- 来源为Kafka、消费起始位点为时间戳
- 来源为MySQL、消费起始位点为时间戳
- 来源为MySQL、消费起始位点为指定binlog日志-binlog日志位置
- 来源为Oracle、增量读取方式为logminer、消费起始位点为时间戳
- 来源为Oracle、增量读取方式为logminer、消费起始位点为指定scn
- 来源为Oracle、增量读取方式为ogg、消费起始位点为时间戳
- 来源为SQLServer、消费起始位点为指定lsn
- 来源为TeleDB、消费起始位点为指定binlog日志-binlog日志位置
- 来源为TelePG、消费起始位点为指定lsn
- 具体位置含:
10.【实时同步任务】数据来源为Kafka、去向为Kudu时,字段映射-来源的字段类型支持映射去向表字段类型
11.【实时同步任务】新增自定义参数
- 功能介绍:
- 参数名称:cast.opts-to-string.formatted,默认值:false,可选值: true/false。值为true时,将来源MySQL的${op_ts}字段转换为timestamp,时区采用计算节点的机器时区。支持针对任务粒度设置自定义参数,并支持配置EasyOps全局参数针对平台粒度生效。其中,任务级别参数优先级高于EasyOps全局参数。
- 参数名称:ogg-json.time-zone,默认值:UTC。来源为Kafka、序列化格式为ogg-json时,针对${op_ts}和${current_ts}字段,支持通过自定义参数设置时区,默认值为零时区。支持针对任务粒度设置自定义参数,并支持配置EasyOps全局参数针对平台粒度生效。其中,任务级别参数优先级高于EasyOps全局参数。
12.【整体】配合平台整体支持项目禁用功能,禁用的项目的数据传输页面将无法查看。
其他变更
1.发布中心发布离线同步任务的产品功能变更:资源列表由展示当前项目-集群的全部任务,改为仅展示已提交上线的任务。发布离线同步任务时,由发布任务的开发模式配置,改为发布任务的线上模式配置。
注意:针对数据传输-v3.11.0版本上线前已发布的发布实例包,如发布实例包包含离线同步任务,发布离线同步任务时仍发布开发模式配置。
2.数据去向为Doris和StarRocks、导入方式为stream load时,如去向表新增字段,由任务报错改为任务不报错。
版本:v3.10.0
新增功能
1.【离线同步任务】创建Hive表时支持启用表名规则校验
- 功能介绍:
- 配置管理-快速创建表配置模块:当前项目启用表名规则开关打开时,在当前项目-集群创建Hive表时,会引用模型设计中心“原数据层-ods”对应集群的表名规则进行表名规则检测。
- 表名规则检测范围包含:1、离线同步任务中,数据去向为Hive的“快速创建表”功能,2、批量创建任务,数据去向为Hive时创建的表。
- 功能使用注意事项:
- 配置管理-快速创建表配置模块:“启用表名规则”开关针对当前项目下所有集群均生效。
- 在某个项目-集群的离线同步任务创建Hive表时,如需引用模型设计中心“原数据层-ods”对应集群的表名规则进行表名规则检测,需要满足两个条件:1、当前项目的“启用表名规则”开关打开,2、当前项目-集群所属的项目组-集群的模型设计中心“原数据层-ods”表名规则状态为启用。
- 功能详细使用步骤:
- 配置管理-快速创建表配置模块:开启“启用表名规则”开关。注意:仅项目负责人和项目管理员可编辑配置管理模块。
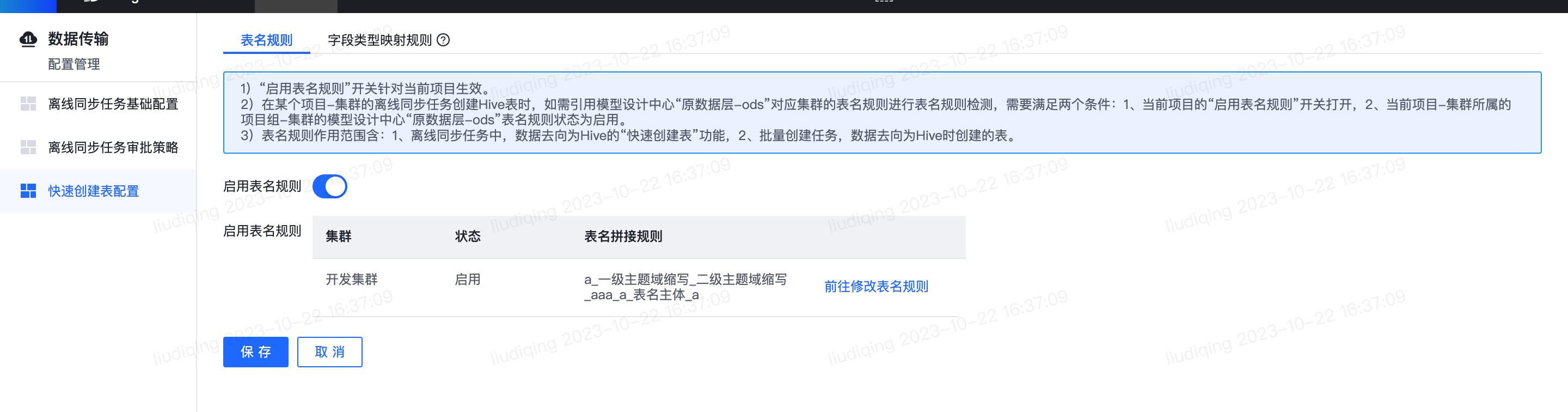
- 离线同步任务:编辑任务(数据去向为Hive)-快速新建目标Hive表,点击“生成SQL语句“和”执行“按钮时,将校验表名称是否符合表名规则。
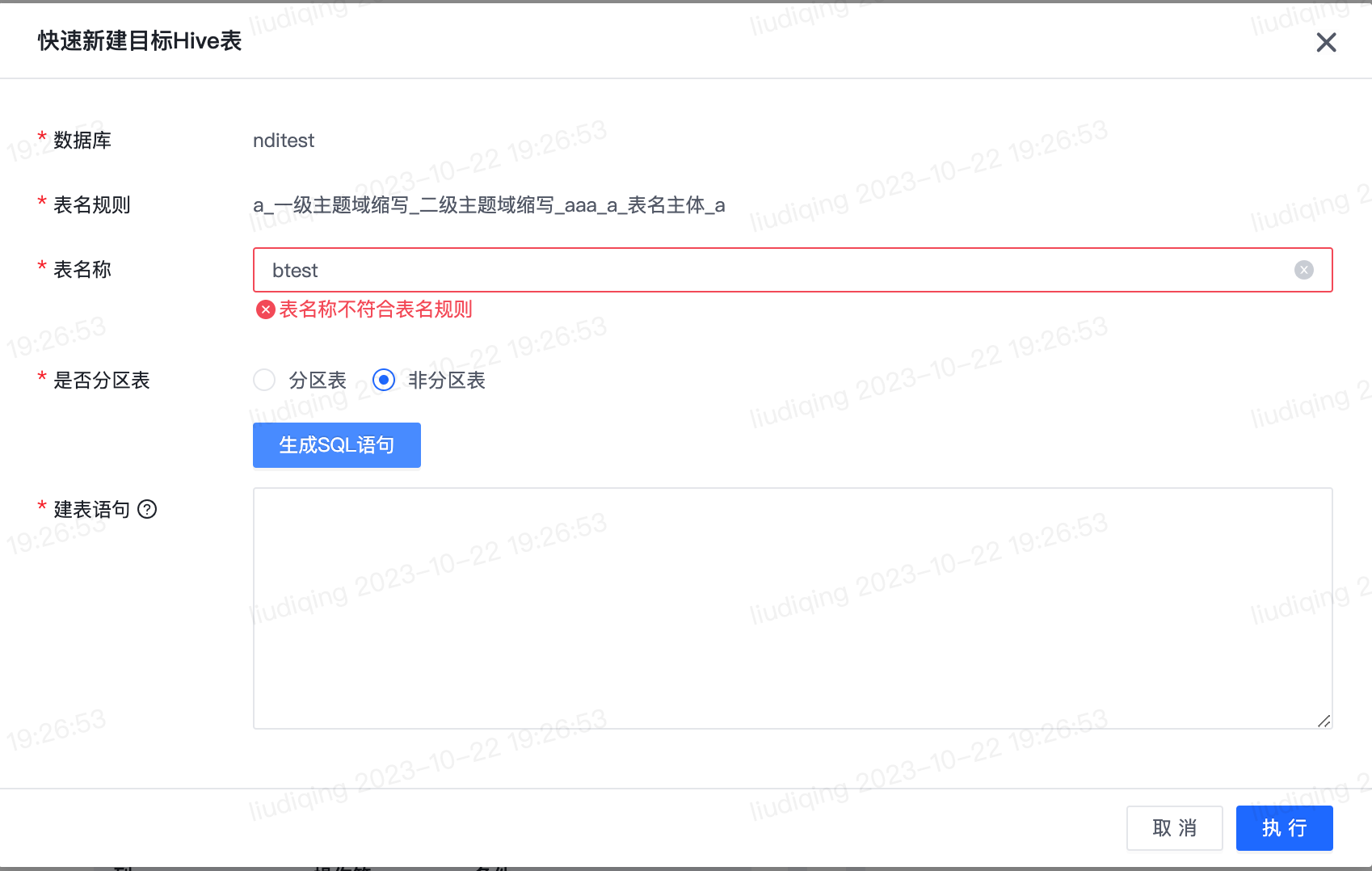
- 离线同步任务:批量新建任务(数据去向为Hive)-生成表配置,点击“生成SQL语句“和”执行“按钮时,将校验表名称是否符合表名规则。
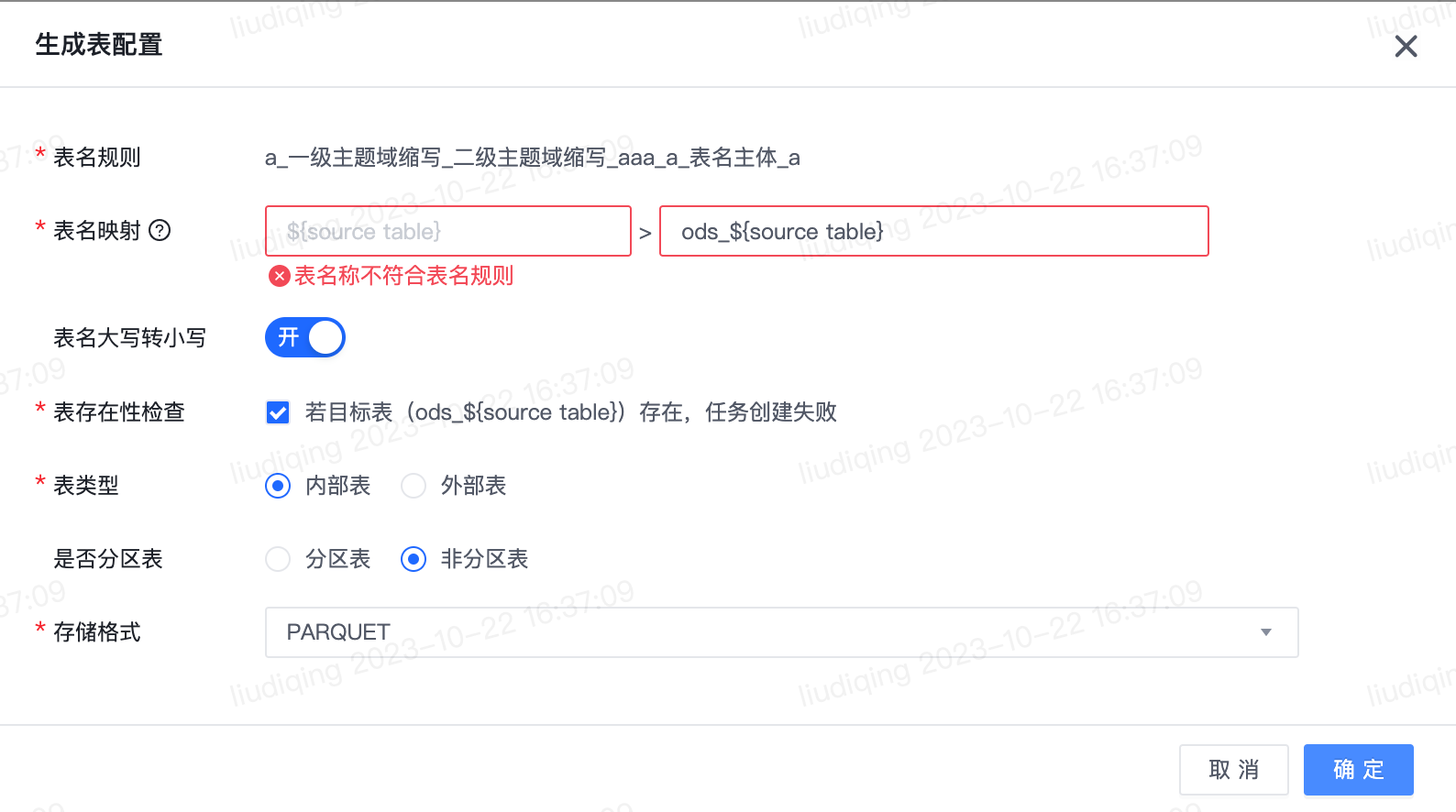
- 配置管理-快速创建表配置模块:开启“启用表名规则”开关。注意:仅项目负责人和项目管理员可编辑配置管理模块。
2.【实时同步任务】任务支持引用参数组
- 功能介绍:
- 实时同步任务支持引用参数组,用于1)任务导入导出时对库名、Topic名等进行替换,2)任务常用的高级配置-自定义参数配置为参数组,可实现不同任务间的自定义参数复用。
- 功能使用注意事项:
- 同一实时同步任务内多个参数组内有相同参数项时,系统取排在前面的参数组的参数值。
- 如果字段映射支持的内置变量与参数组参数冲突时,内置变量优先级更高。
- 如果高级设置填写的参数与参数组参数冲突时,则高级设置填写的参数优先级更高。
- 如果导入引用参数组的实时同步任务时,会检测导入端是否存在同名参数组,如不存在则检测不通过,导入失败。如导入端存在同名参数组,则在导入端会将任务引用的参数组id替换为导入端同名参数组的id。
功能详细使用步骤:
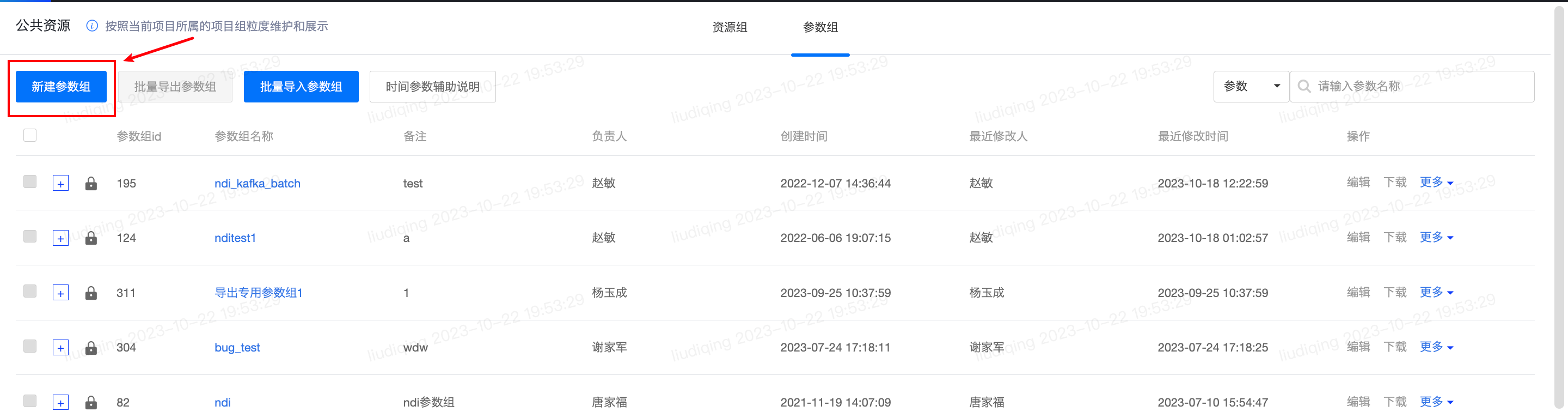
- 公共资源-参数组模块:新建参数组,设置参数名称和参数值
数据传输-实时同步任务:“引用参数组”配置项选取需引用的参数组。
- 1)如参数组的使用场景是:任务常用的高级配置-自定义参数配置为参数组,可实现不同任务间的自定义参数复用,则“引用参数组”配置项选取需引用的参数组即可。
2)如参数组的使用场景是:任务导入导出时对库名、Topic名等进行替换,除“引用参数组”配置项选取需引用的参数组外,请在使用变量处按照${参数组名称}的格式填写参数组参数。示例详见下图。支持使用参数组参数的位置包含:

- 数据来源:1、数据源类型为Kafka-【topic名称】,2、任务类型为多表同步,数据源类型为MySQL、Oracle、TeleDB、SQLServer-【数据库名称】,3、任务类型为多表同步或分库分表同步,数据源类型为Oracle,增量读取方式为ogg-【Topic名称】
- 数据去向:1、数据源类型为Kudu-【去向表名】,2、数据源类型为Iceberg、Arctic、Hive-【去向库名】和【去向表名】,3、数据源类型为Kafka-【去向Topic】
- 字段映射:数据去向为Kudu、Iceberg、Arctic、Hive时,来源表字段类型为自定义表达式时,支持填写参数组参数
- 公共资源-参数组模块:新建参数组,设置参数名称和参数值
3.【实时同步任务】插件版本为1.x的任务,支持升级插件版本至2.x
- 功能介绍:
- 相较于1.x的插件版本,实时同步任务2.x的插件版本支持了更丰富的产品功能(如:数据来源支持TelePG等)。此前,插件版本为1.x的历史任务不可升级插件版本,此版本提供了升级插件版本的功能。
- 功能使用注意事项:
- 仅当插件版本为1.x且任务状态为:未启动、停止、启动失败、运行失败的任务,支持升级插件版本。
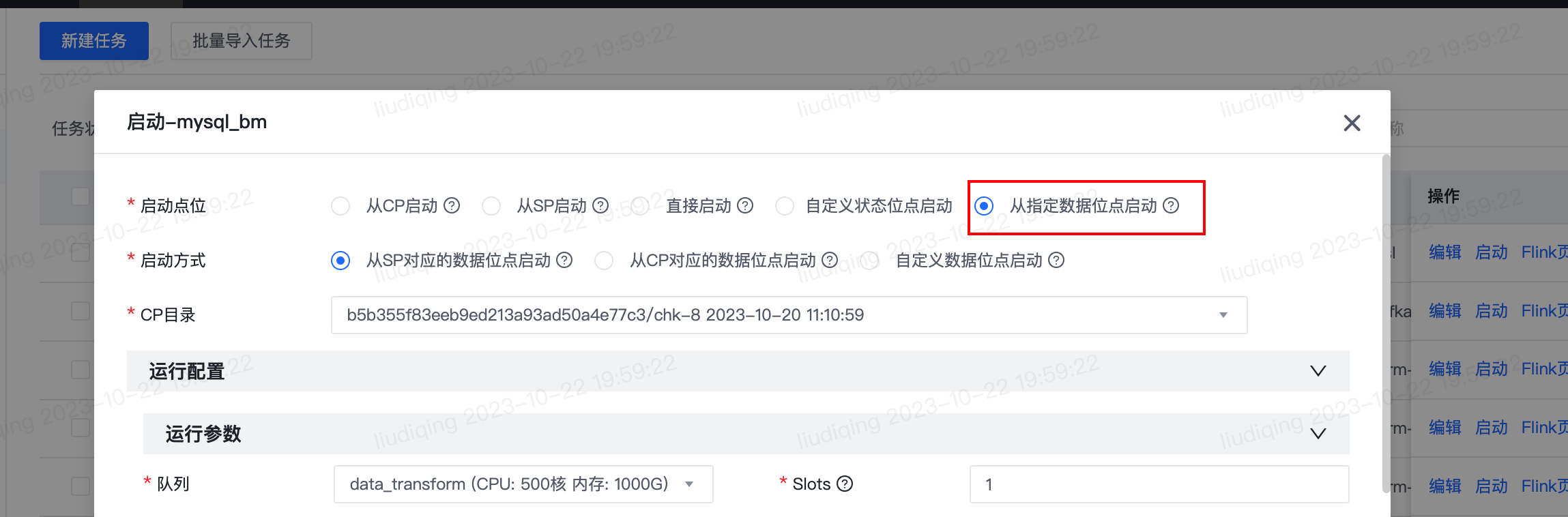
- 由于1.x和2.x插件版本的任务状态不兼容,升级插件版本后首次启动任务时,如选择“从CP启动”或“从SP启动”,任务运行可能会报错。因此,升级插件版本后首次启动任务时,启动点位请选取“从指定数据位点启动”,启动方式建议选取“从SP对应的数据位点启动”,保障数据的完整性。如此前任务停止时未保存SP,则建议选取“从CP对应的数据位点启动”并建议选取时间较早的CP目录,避免数据丢失。
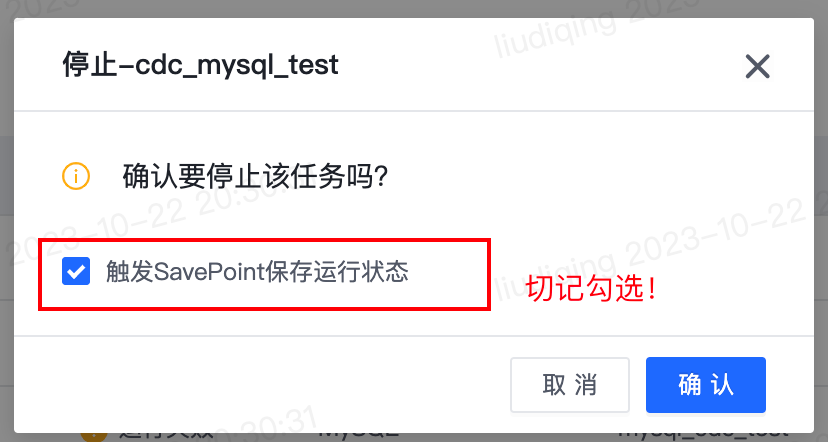
- 功能详细使用步骤:
- 点击“停止”按钮停止任务。注意:切记勾选“触发SavePoint保存运行状态“。
- 点击“升级插件版本”按钮并确认升级,任务的插件版本将会由1.x升级至2.x。

- 点击“启动”按钮,启动点位选择“从指定数据位点启动”。启动方式建议选取“从SP对应的数据位点启动”,保障数据的完整性。如此前任务停止时未保存SP,则建议选取“从CP对应的数据位点启动”并建议选取时间较早的CP目录,避免数据丢失。
- 点击“停止”按钮停止任务。注意:切记勾选“触发SavePoint保存运行状态“。
4.【实时同步任务】提供启动任务和停止任务的OpenAPI
- 功能介绍:
- OpenAPI使用说明详见OpenAPI说明文档。
功能优化
1.【离线同步任务】MongoDB作为来源时支持自定义字段类型
- 功能介绍:
- MongoDB作为来源时,原仅支持由MongoDB Reader插件在执行任务时自动采样推断字段类型,存在字段类型推断不准确导致任务报错的风险。故此版本开放字段类型定义方式,支持由用户在配置任务时自定义字段类型,并提供根据采样数据解析字段类型的辅助功能,提升自定义字段类型的配置效率。
- 字段类型定义方式为“自定义字段类型”时,支持配置空字段处理策略,即当一条数据解析时,数据内容中找不到字段时的处理方式采取任务报错或设为null数据。
- 优化后功能使用步骤:
- 点击“数据解析”按钮,将自动从选取的MongoDB集合中获取一条数据并填充至数据解析弹窗的样例数据输入框,点击“解析”按钮即可解析字段名称和字段类型并填充至表格。如系统自动获取的数据不符合预期,也支持由用户手动输入数据样例。
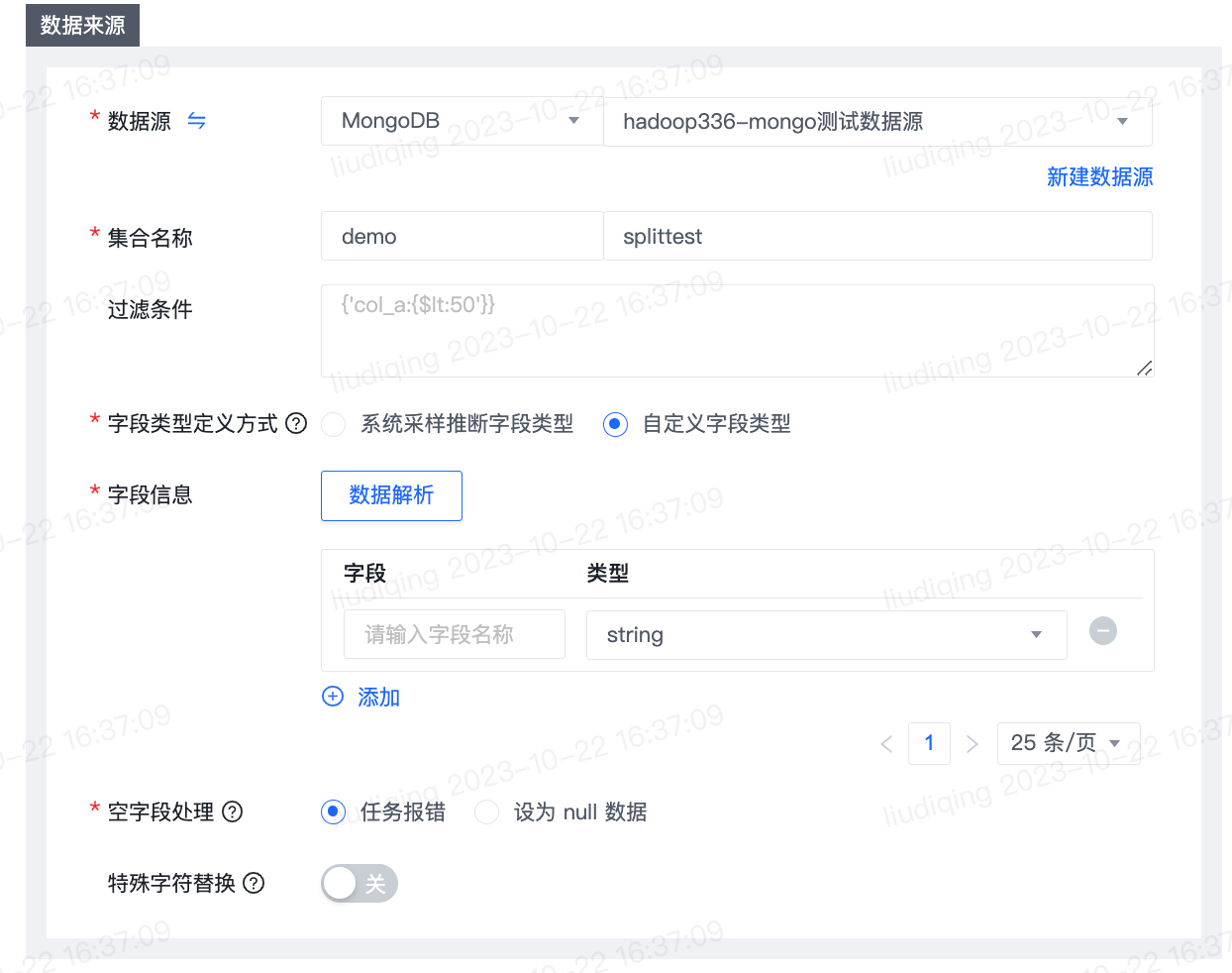
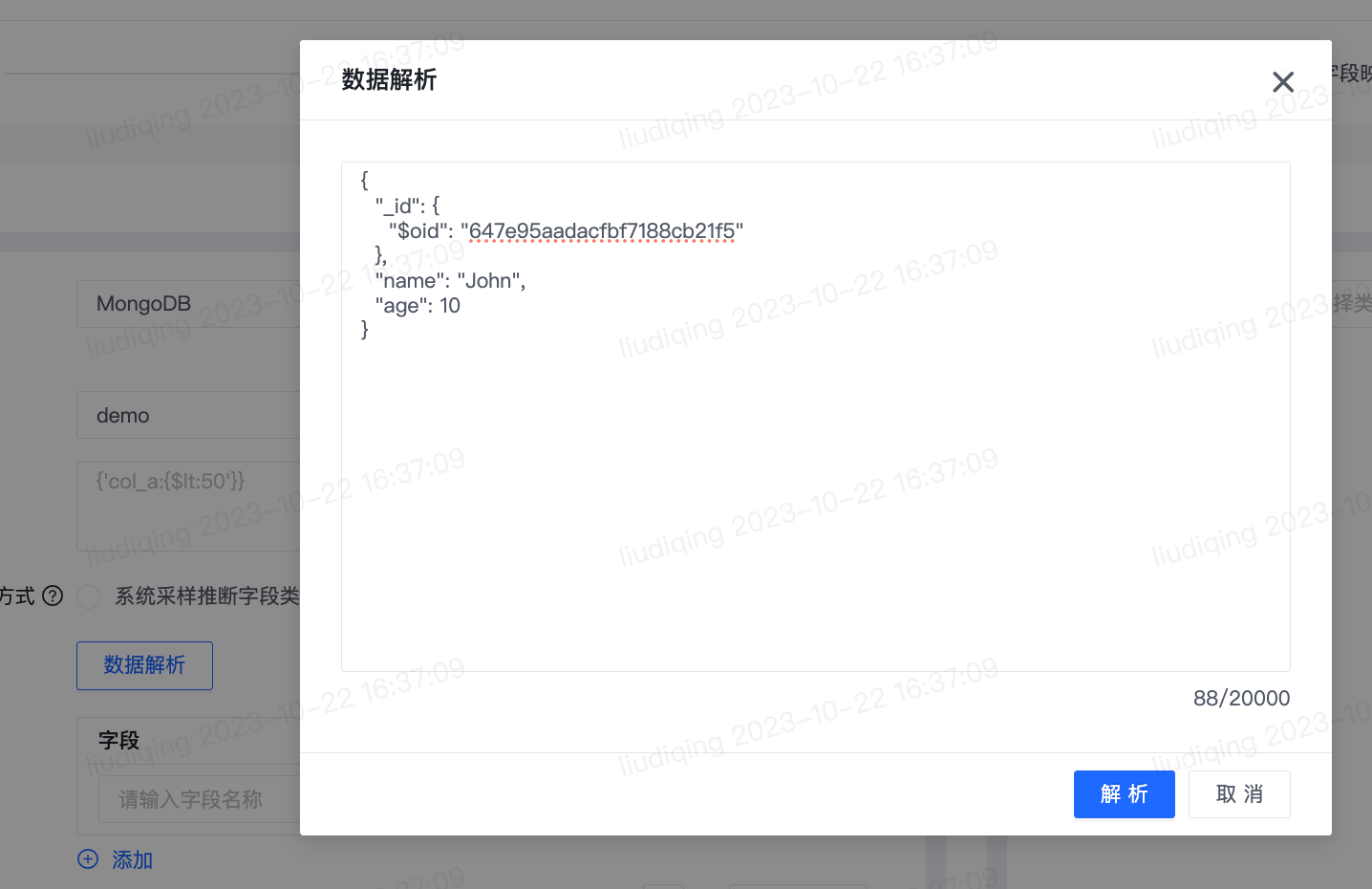
- 点击“数据解析”按钮,将自动从选取的MongoDB集合中获取一条数据并填充至数据解析弹窗的样例数据输入框,点击“解析”按钮即可解析字段名称和字段类型并填充至表格。如系统自动获取的数据不符合预期,也支持由用户手动输入数据样例。
2.【离线同步任务】MongoDB适配版本:3.0、6.0
3.【离线同步任务】TDSQL适配版本:10.3.14(MySQL 8.0)
4.【离线同步任务】Redis新增版本:3.0(集群部署模式:single)、3.2(集群部署模式:single)、5.0(集群部署模式:single)
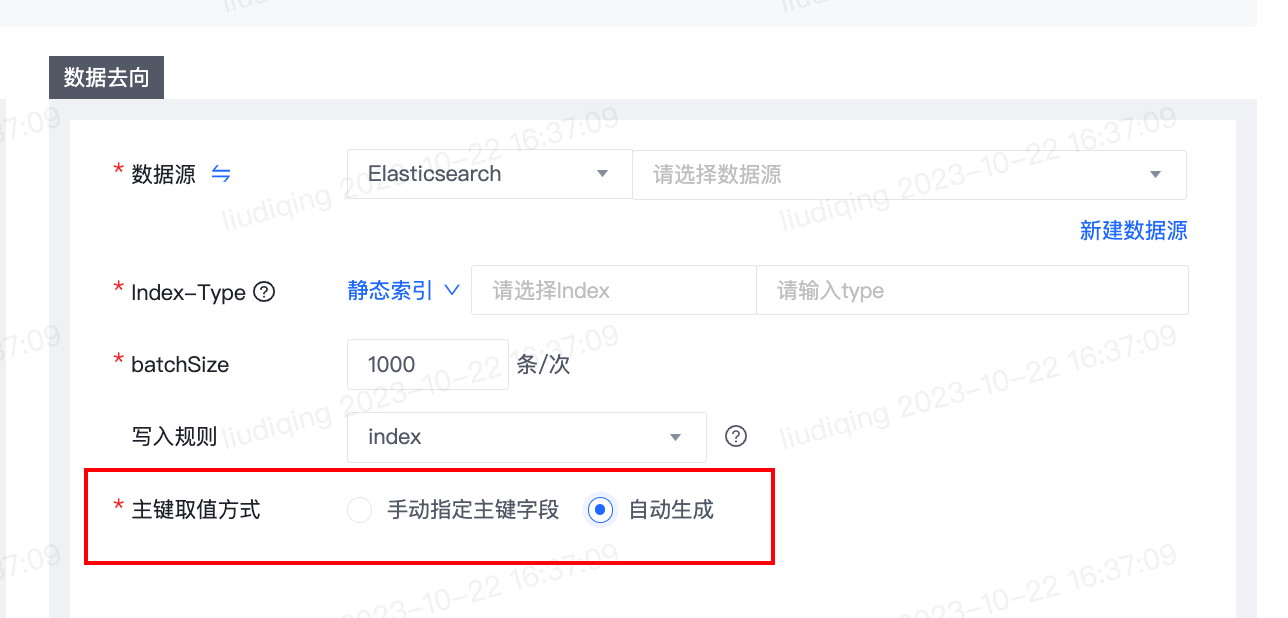
5.【离线同步任务】ES作为数据去向时支持配置“主键取值方式”
- 功能介绍:
- ES作为数据去向时支持配置“主键取值方式”:取值方式为手动指定主键字段时,由用户指定选取ES的哪个字段作为主键;取值方式为自动生成时,主键值在写入ElasticSearch时由系统自动生成。
- 历史任务的“主键取值方式”默认为“手动指定主键字段”。
版本:v3.9.2
新增功能
1.【离线同步任务】数据去向为FTP、目标文件名为指定文件名时,支持根据来源表字段动态生成文件
- 功能介绍:
- 指定文件名支持填写来源表字段名称,格式:${ 来源表字段名称 }(注意:来源表字段名称前后带空格)。其中,${ 来源表字段名称 }变量支持填写来源表字段名称和Hive表的分区字段名称,任务运行时如发现来源表不存在该字段,任务运行时会报错。
- 示例:指定文件名输入userinfo_${ dt },来源Hive表为一级分区表。当读取来源Hive表dt=2023-01-01分区的数据,对应的FTP文件名为userinfo_2023-01-01。
2.【离线同步任务】批量新建任务,数据来源为Hive、数据去向为FTP、目标文件名为指定文件名时,支持内置变量
- 功能介绍:
- 支持填写内置变量:${source table}、${primary partition}、${secondary partition}、${tertiary partition}。其中${source table}表示来源表表名,${primary partition}、${secondary partition}、${tertiary partition}仅当来源为Hive表时生效,分别表示一级分区、二级分区、三级分区的值。
- 批量创建任务时,会将内置变量${source table}解析为来源表名,会将内置变量${primary partition}、${secondary partition}、${tertiary partition}中“primary partition”、“secondary partition”、“tertiary partition”解析为来源Hive表的对应分区字段名称(字段名称前后包含空格)。如来源不是Hive表或Hive表不存在对应级别的分区,则批量创建任务时解析时变量值为空。
- 示例:指定文件名输入ods${source table}${primary partition}${secondary partition},来源Hive表为一级分区表,表名为userinfo,一级分区名为dt。当批量创建任务时,指定文件名会解析为:ods_userinfoa${ dt }_。
版本:v3.9.1
新增功能
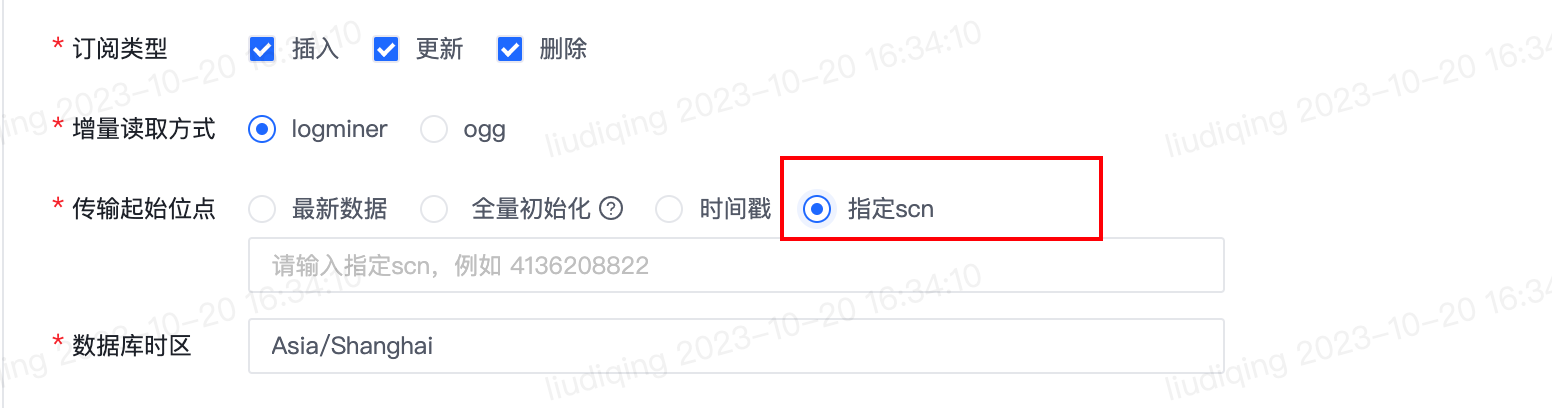
1.【实时同步任务】数据来源为Oracle、增量读取方式为logminer时,传输起始位点支持:指定scn
- 功能介绍:
- 任务类型为多表同步或分库分表同步、增量读取方式为logminer时,传输起始位点支持:指定scn
- 任务类型为多表同步或分库分表同步、增量读取方式为logminer时,传输起始位点支持:指定scn
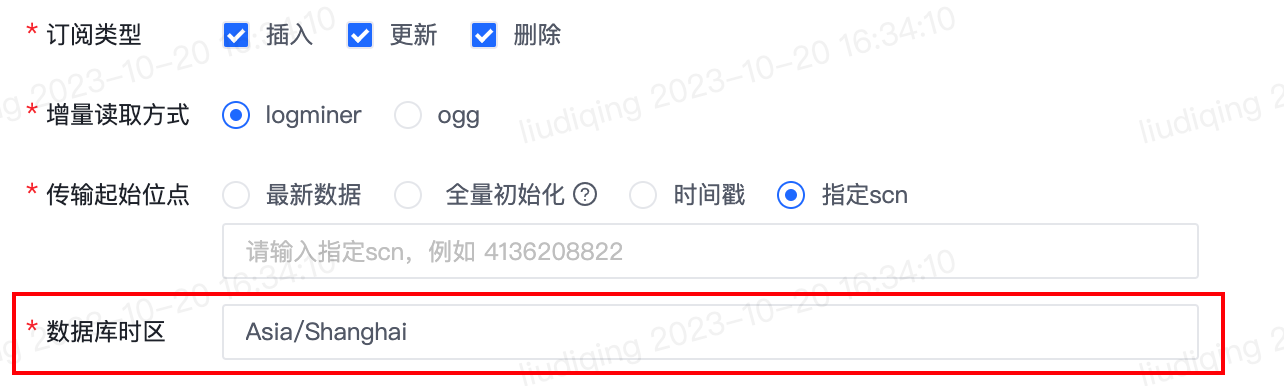
2.【实时同步任务】数据来源为Oracle时,支持配置数据库时区
- 功能介绍:
- 数据来源为Oracle时,支持配置数据库时区
- 数据来源为Oracle时,支持配置数据库时区
功能优化
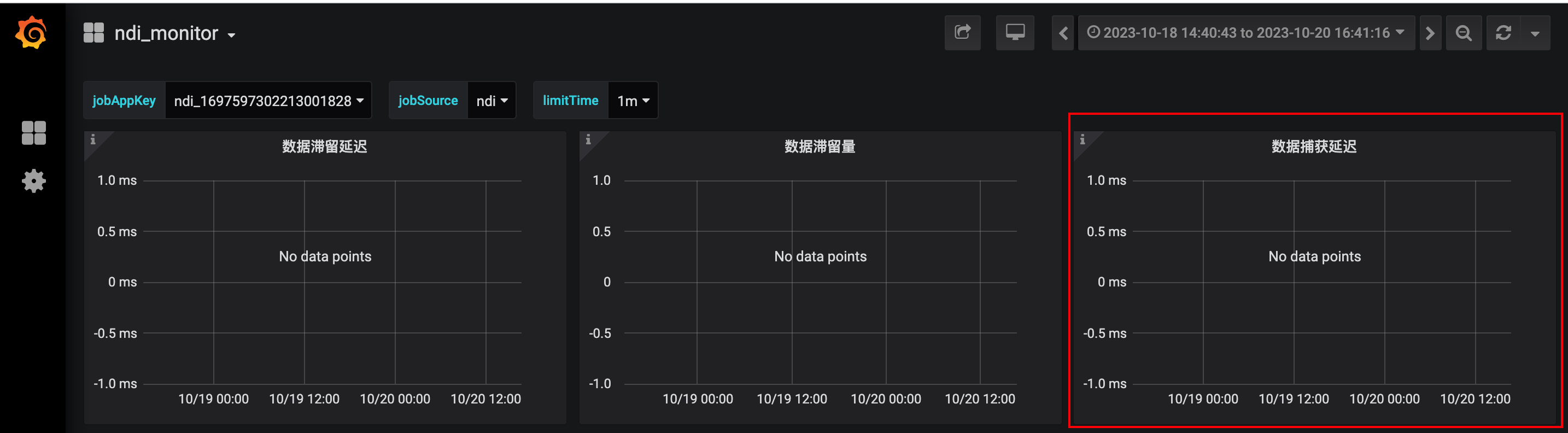
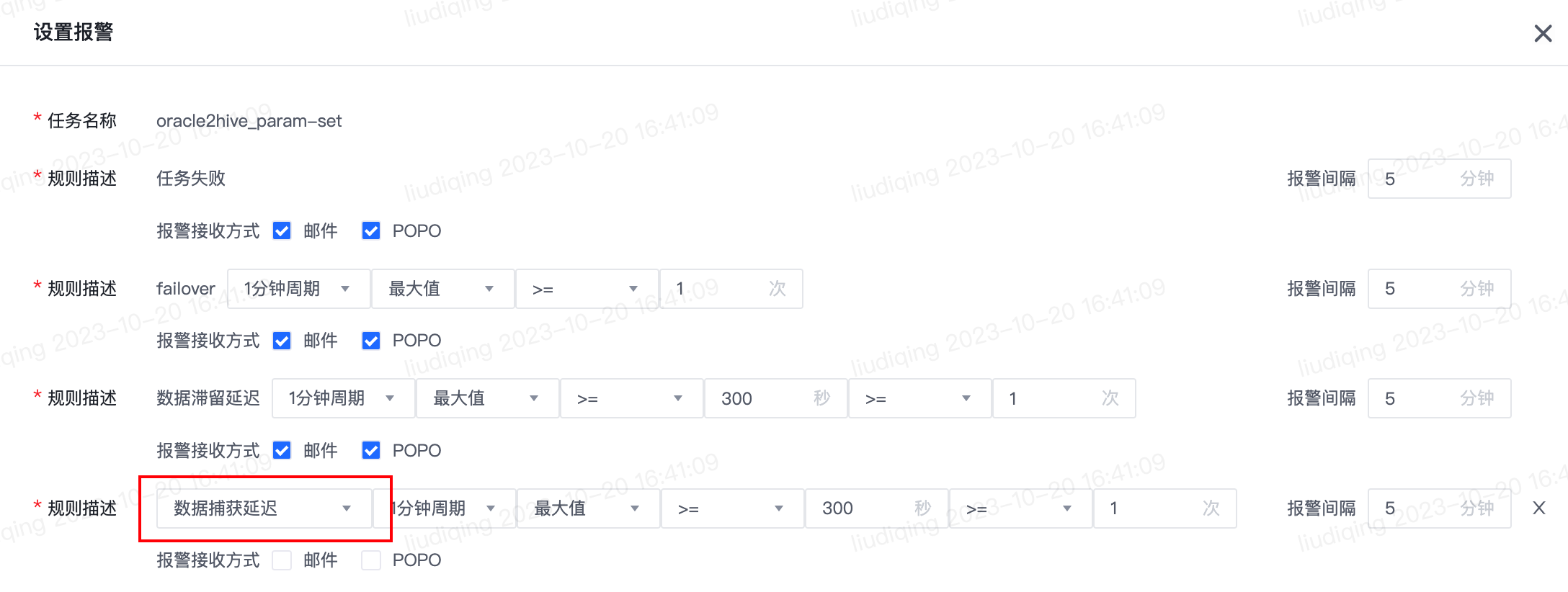
1.【实时同步任务】数据来源为Oracle时,监控新增“数据捕获延迟”指标,并支持针对“数据捕获延迟”指标发送告警
- 功能介绍:
- 数据来源为Oracle时,监控新增“数据捕获延迟”指标,并支持针对“数据捕获延迟”指标发送告警。
- 数据捕获延迟=任务处理时间-scn扫描时间
版本:v3.9.0
新增功能
1.【实时同步任务】数据来源新增TelePG数据源
- 功能介绍:
- 任务类型为多表同步时,数据来源支持读取TelePG数据源。
- 功能使用注意事项:
- 请注意设置合理的日志回收策略。任务启动时,如果指定读取的数据区间内存在被回收的日志,则任务不会报错,但仅可读取未回收的日志对应的数据,存在数据丢失风险。
仅支持读取编码格式为UTF-8的文本数据,数据库请勿使用ASCII等其余编码格式。
数据库Replica Identity(用于指定在进行数据复制时如何确定唯一性标识符的设置)的值建议设置为“FULL(表示使用所有表列作为唯一性标识符)”,虽然可能会增加复制的数据量,但能保障数据的一致性和完整性。
- 请注意设置合理的日志回收策略。任务启动时,如果指定读取的数据区间内存在被回收的日志,则任务不会报错,但仅可读取未回收的日志对应的数据,存在数据丢失风险。
- 功能详细使用步骤:
- 功能入口:
- 功能入口:
2.【离线同步任务】数据传输来源或去向为Hive时,适配版本:2.1.x-CDH6.3.x
- 功能介绍:
- 数据传输来源或去向为Hive时,适配版本:2.1.x-CDH6.3.x。
- 功能使用注意事项:
- 读写Hive版本:2.1.x-CDH6.3.x基于Spark3的特性:multiple catalog实现。仅当用户环境支持Spark3.3时,支持读写此版本,否则任务会报错。
- 来源版本为:2.1.x-CDH6.3.x,读取方式支持基于Spark读取数据,任务模式支持向导模式。
- 功能详细使用步骤:
- 功能入口:

- 功能入口:
功能优化
1.【离线同步任务】批量创建任务功能增强:来源新增Hive,去向新增FTP,新增高级配置模块
- 功能介绍:
- 来源新增Hive数据源,支持读取平台内置Hive数据源。来源为任意数据源类型时,新增特殊字符替换功能。
- 去向新增FTP数据源,功能对标创建单个离线同步任务。
- 新增高级配置模块。
- 功能使用注意事项:
- 来源为Hive时,仅支持读取平台内置Hive数据源。如需读取同集群下其余项目的库,请将库公开给当前项目并授予批量创建任务的用户账号和任务执行账号读权限。
- 去向为FTP时,仅支持选取当前用户有写权限的数据源。
2.【离线同步任务】脱敏规则支持选取脱敏算法为UDF Studio中的UDF的脱敏规则及数据来源为API、HBase、Elasticsearch时的来源表字段选取优化
- 功能介绍:
- 脱敏规则支持选取脱敏算法为UDF Studio中的UDF的脱敏规则,字符型字段和数值型字段均可选取相应脱敏规则。其中,脱敏算法统一显示为“UDF Studio中的UDF",算法配置显示函数中文名称。
- 数据来源为API、HBase、Elasticsearch时的来源表字段选取优化:
1)来源为API时,数据脱敏-来源表字段支持选取字段映射已选取的来源表字段。如字段映射选取自定义表达式,填写格式为a as b时,数据脱敏-来源表字段选项文案为“b”。
2)来源为HBase时,数据脱敏-来源表字段支持选取字段映射已选取的来源表字段。如字段映射选取列族并填写列修饰符,则数据脱敏-来源表字段选项文案格式为“列族:列修饰符”。
3)来源为Elasticsearch时,数据脱敏-来源表字段支持选取字段映射已选取的来源表字段。如字段映射选取自定义表达式,填写格式为a as b时,数据脱敏-来源表字段选项文案为“b”。
- 功能使用注意事项:
- 配置任务时仅可选取当前用户有权限的函数。
- 运行任务时会校验任务执行账号是否有函数权限,若无权限则任务报错。
- 运行任务时,如果函数有测试态,开发模式用函数的测试态,线上模式有函数的线上态;如果函数没有测试态,开发模式和线上模式都用函数的线上态。
- 功能优化后使用步骤:
- 功能入口:

- 功能入口:
3.【离线同步任务+实时同步任务+数据导入】选取和使用队列时增加对队列适用场景的判断逻辑
- 功能介绍:
- 离线同步任务:试运行仅可选取队列适用场景包含离线同步的队列;任务运行时校验队列的适用场景,如不包含离线同步,则任务报错。
- 数据导入:导入数据时仅可选取队列适用场景包含离线同步的队列;任务运行时校验队列的适用场景,如不包含离线同步,则任务报错。
- 实时同步任务:试运行仅可选取队列适用场景包含实时同步的队列;任务运行时校验队列的适用场景,如不包含实时同步(数据传输),则任务报错。
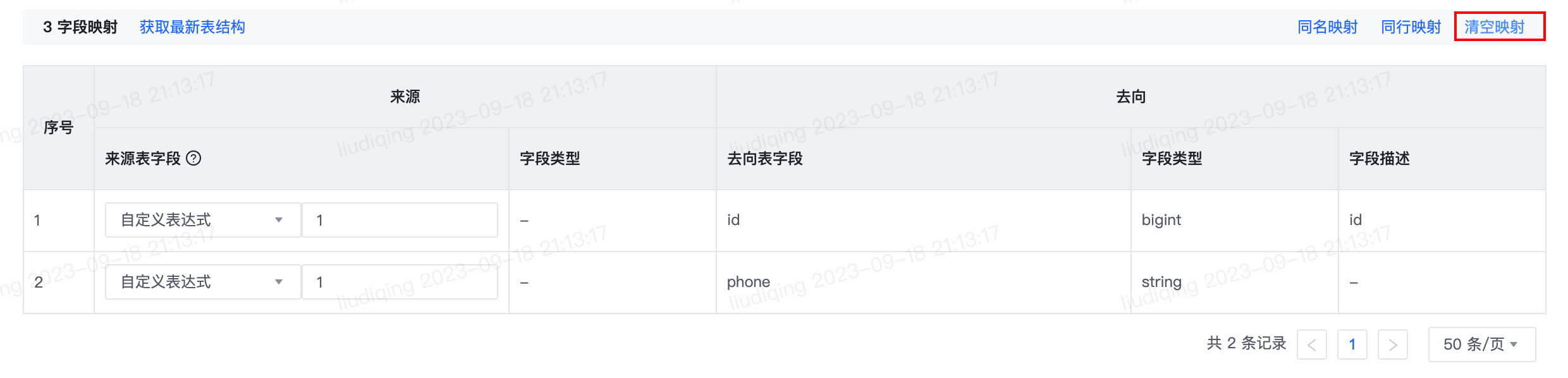
4.【离线同步任务】来源和去向为结构化数据源时支持清空映射
- 功能介绍:
- 字段映射新增清空映射按钮,点击按钮如二次确认要清空映射,则数据去向为Hive、Doris、StarRocks、Maxcompute时,来源表字段列将均置为自定义表达式;数据去向为其余数据源类型时,来源表字段列将均置为不导入。
- 功能优化后使用步骤:
- 功能入口:
- 功能入口:
版本:v3.8.0
新增功能
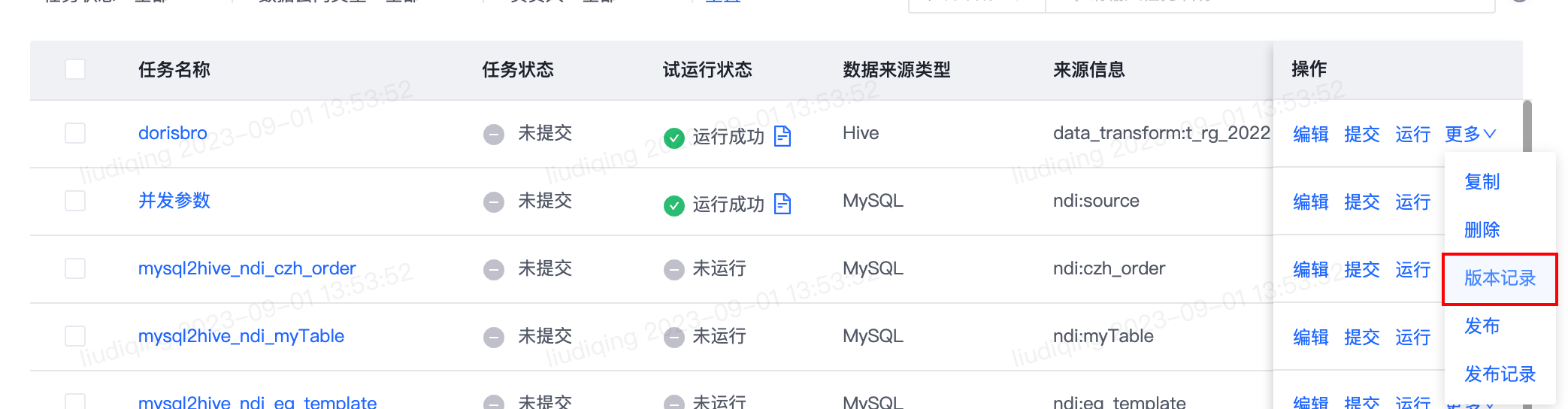
1.【离线同步任务】支持版本管理功能
- 功能介绍:
- 离线同步任务每次提交上线,会生成一个版本号。支持查看历史版本,支持历史版本间的版本比对,支持开发模式最新版本和历史版本间的版本比对,并支持开发模式回滚至历史版本。
- 功能使用注意事项:
- 如果用户没有任务的查看权限,则不可点击“版本记录”按钮置灰不可点,不可查看历史版本和比对历史版本。
- 如果用户没有任务的编辑权限,则不可点击“回滚”按钮。
- 功能详细使用步骤:
- 功能入口:操作-版本记录
- 功能入口:操作-版本记录
2.【实时同步任务】支持任务导入导出
- 功能介绍:
- 支持批量导入和批量导出实时同步任务,提升测试环境和生产环境的任务互通
- 功能详细使用步骤:
- 批量导入任务-功能入口:

- 批量导出任务-功能入口:

- 导入任务时:
(1)支持由用户选择任务负责人设置为导出端任务负责人或导入人。
(2)如果读写的数据源包含:{项目}-{集群}Hive/Arctic/Iceberg数据源,导入任务时将“{导出项目名称}-{导出集群名称}Hive数据源” 替换为“{导入项目名称}-{导入集群名称}Hive/Arctic/Iceberg数据源”。
(3)引用的数据源替换为目标端同名数据源。(注意:含来源数据源,去向数据源,来源为Oracle增量读取方式为ogg的消息数据源,任务类型为分库分表同步时来源为MySQL-指定binlog日志下的物理数据源,任务类型为分库分表同步时来源为SQLServer-指定ls下的物理数据源。
(4)支持由用户选择是否需同名覆盖
如未开启“覆盖同名任务”:仅覆盖uuid相同的任务。uuid是任务的唯一标识,在导入端导入并新建任务时,系统会将新建任务的uuid值赋值为导出端任务的uuid值。任务再次导入时,会按照uuid值匹配对应任务。需要注意:如覆盖时发现导入端已存在与导出端任务名称相同但uuid不同的任务,则导入失败。
如开启“覆盖同名任务”:则会先根据uuid进行匹配并覆盖对应的任务,如导入端无uuid相同的任务,再用任务名称匹配并覆盖对应的任务。在导入端覆盖同名任务时,系统会将任务的uuid值修改为导出端任务的uuid值。
- 批量导入任务-功能入口:
3.【实时同步任务】来源支持SQLServer
- 功能介绍:任务类型为多表(Topic)同步或分库分表同步时,来源数据源类型支持SQLServer
- 功能详细使用步骤:
- 功能入口:
- 功能入口:
功能优化
1.【离线同步任务】对接UDF Studio,API作为数据来源支持使用UDF进行前置处理
- 功能介绍:
- API包含动态token、动态密钥算法以及前置认证时,支持选取UDF Studio的函数作为前置处理脚本以应对复杂的前置处理逻辑。具体流程为:传输请求API接口数据前会执行UDF,获取UDF处理后的url,header,params和body再去请求API。
- 功能使用注意事项:
- 配置任务时,仅可选择当前用户有权限、函数适用产品包含数据传输的UDF。运行任务时,会校验任务执行账号是否有函数权限,如无权限,任务会报错。
- 任务运行时:
1)如果函数有测试态,开发模式用函数的测试态,线上模式有函数的线上态
2)如果函数没有测试态,开发模式和线上模式都用函数的线上态
- 功能详细使用步骤:
- 函数使用说明:
1)实现接口 Function
2) 传输请求API接口前会调用UDF的apply方法,得到用户处理后的url,header,params和body再去请求API。
3)建议对UDF的依赖jar进行shade避免冲突。 - 编码示例:
public class UDF implements Function<Map<String, Map<String, String>>, Map<String, Map<String, String>>> { @Override public Map<String, Map<String, String>> apply(Map<String, Map<String, String>> stringStringMap) { // 请求api的header Map<String, String> header = stringStringMap.get("header"); // 请求参数(get请求会有) Map<String, String> paramsMap = stringStringMap.get("params"); // 任务参数包含body(post请求会有)、url、requestType(get/post) Map<String, String> taskInfoMap = stringStringMap.get("taskInfo"); // 做些你想做的处理逻辑,比如塞点参数进header、paramsMap、body if ("get".equals(taskInfoMap.get("requestType"))) { header.put("appId", "super"); paramsMap.put("searchKey", "111"); } else { header.put("appId", "super"); taskInfoMap.put("body", ""); } // 返回map // 如果是get请求会根据用户处理完返回的header,params,url去请求 // 如果是post请求会根据用户处理完返回的header,body,url去请求 return stringStringMap; } }
- 函数使用说明:
2.【离线同步任务】来源为FTP或HDFS、去向为FTP或HDFS、来源读取方式为非结构化时,数据传输distcp技术方案改为spark-distcp,不依赖于Hadoop版本
- 功能介绍:
- 原distcp技术方案对客户环境Hadoop版本有要求,此次方案优化后非结构化传输功能可不受限于客户环境的Hadoop版本。
3.【实时同步任务】来源为Oracle时,增量读取方式支持ogg
- 功能介绍:
- 部分场景下,Oracle的DBA不支持向数据开发团队开放Oracle数据库的CDC binlog读取权限,而是将Oracle数据源下多个库表的CDC binlog数据同步至Kafka的同一topic下。为下游应用方便,数据开发需要通过数据传输将同一topic下按照Oracle表进行数据分发,将每一张Oracle表的数据分别分发至不同的去向表。
- 优化后功能使用步骤:
- 功能入口:

- 功能入口:
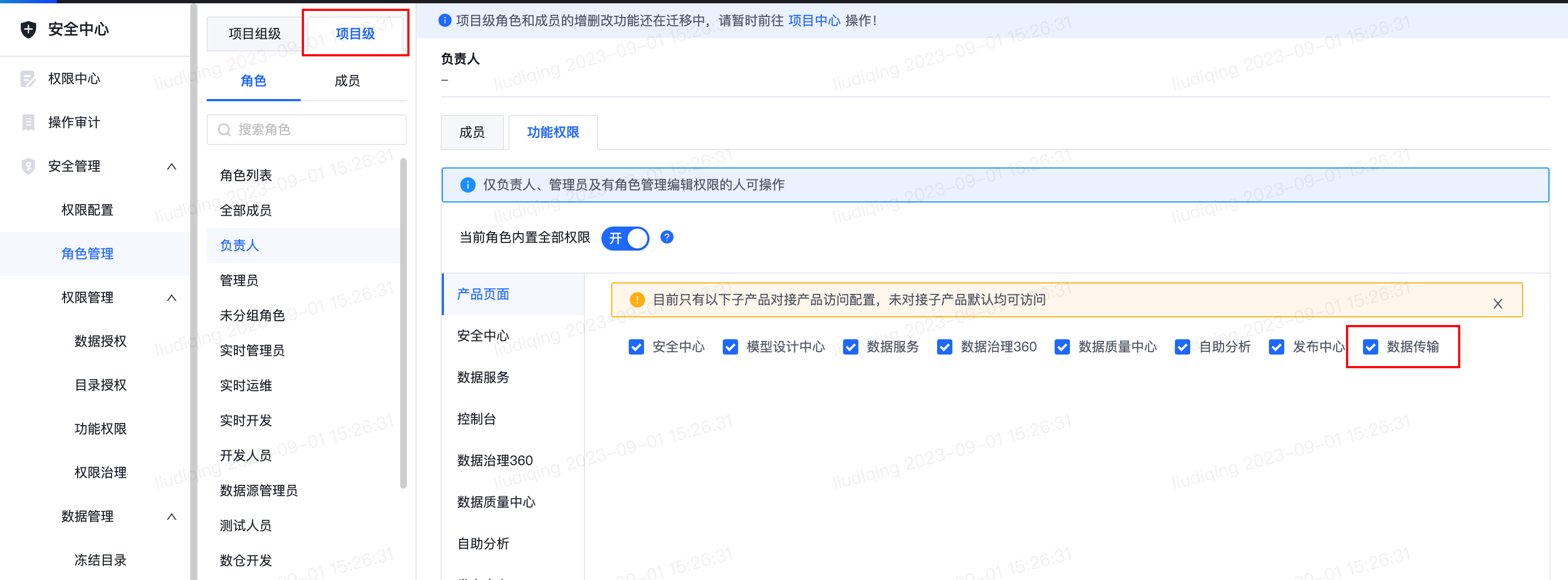
4.【整体】对接安全中心-产品访问权限控制
- 功能介绍:在安全中心项目级别给角色/成员勾选数据传输的产品页面访问配置后,用户才可访问数据传输页面,否则访问会报错。
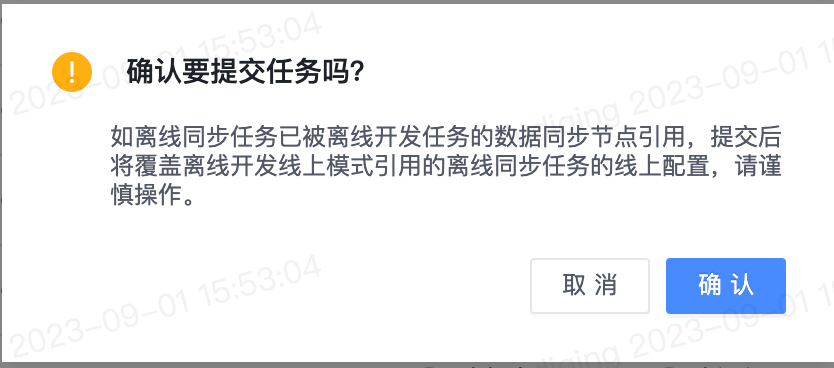
5.【离线同步任务】提交离线同步任务时增加二次确认
- 功能介绍:为避免用户误提交影响线上任务,提交离线同步任务时增加二次确认。
6.【离线同步任务】增加Ops参数,用于在平台粒度配置数据去向为Kudu时是否批量转换与去向字段类型不兼容的来源表字段类型
- 功能介绍:
- 如需批量转换字段类型,则添加自定义参数,参数名称:ndi.spark.spark-conf.spark.transmit.common.supportedCastTypeList,参数值:kudu
7.【实时同步任务】增加Ops参数,用于在平台粒度配置数据去向为Kudu时是否批量转换与去向字段类型不兼容的来源表字段类型
- 功能介绍:
- 如需批量转换字段类型,则添加自定义参数,参数名称:ndi.streamConfig.supportedCastTypeList,属性值:kudu
8.【实时同步任务】来源为TeleDB、Oracle、MySQL、SQLServer、Kafka-ogg json时支持内置变量
- 功能介绍:
- 1、数据来源为MySQL、Oracle、SQLServer、TeleDB,任务类型为分库分表同步或多表(Topic)同步时,自定义表达式支持填写和解析变量:${op}、${op_ts}。${op}表示来源数据库日志中的操作类型,${op_ts}表示来源数据库中的操作时间。
- 2、数据来源为Kafka,序列化格式为ogg-json时,自定义表达式支持填写和解析变量:${pos}、${op_ts}、${current_ts}、${table}。对应于ogg-json中的首层字段,${pos}表示当前事件在ogg流中的位置${op_ts}表示数据库日志中的操作时间,${current_ts}表示数据库日志的获取时间,${table}表示当前时间对应的表名称。
9.【离线同步任务】Kafka数据源适配Spark3.3版本
10.【实时同步任务】新增插件版本2.x
- 功能介绍:
- 历史任务默认版本为1.x,新增任务默认版本为2.x,此功能不影响历史任务。此外,复制任务时,复制创建出的任务与复制的任务的插件版本保持一致;导入任务时,与导出端导出的任务保持一致。
版本:v3.7.1
功能优化
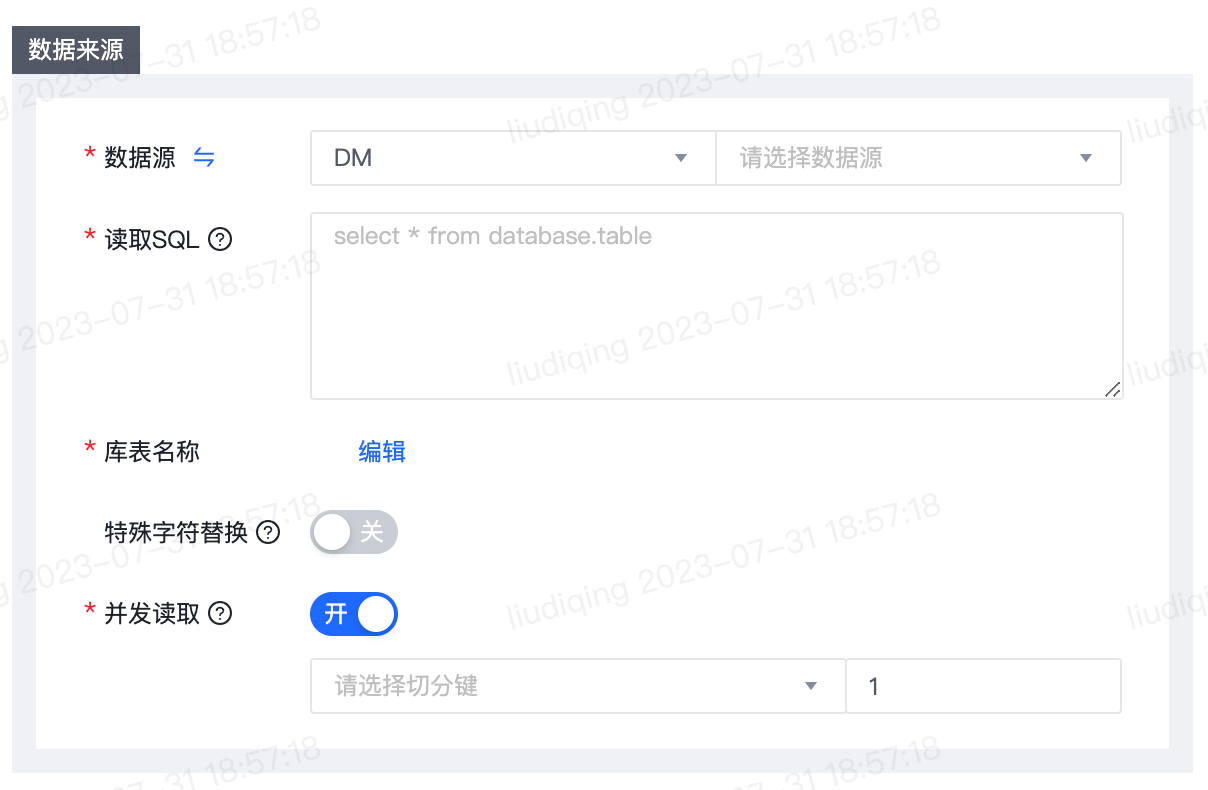
1.【离线同步任务】数据来源来源为DM、VastBase G100时支持SQL模式
- 功能介绍:
- 数据来源来源为DM、VastBase G100时支持SQL模式,用于多表关联查询等场景
- 优化后功能使用步骤:
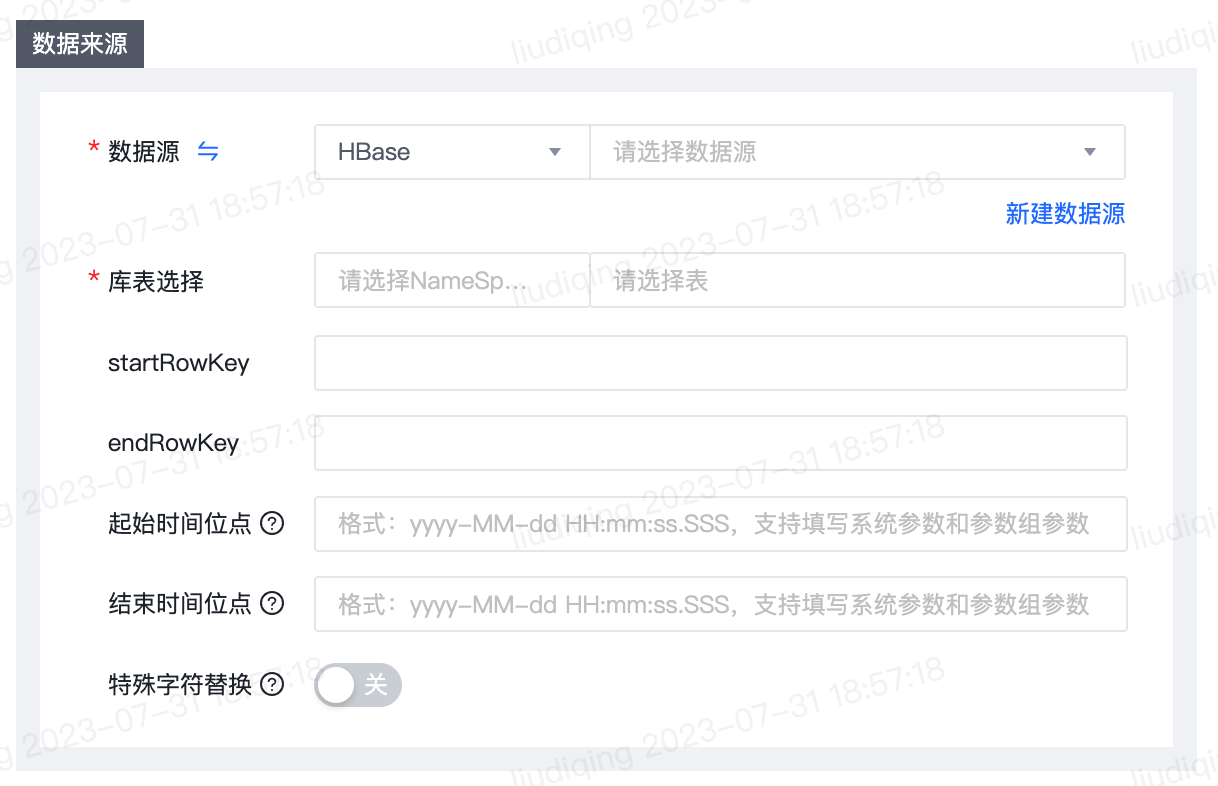
2.【离线同步任务】数据来源为HBase时支持根据timestamp时间戳过滤数据并支持读取timstamp字段
- 功能介绍:
- HBase表每个cell(存储单元)均包含timestamp时间戳,timestamp表示该Rowkey值对应的该列数据的更新时间。此前,离线传输读取Hbase时,在读取范围内如果同一Rowkey值对应的同一列存在多次更新,则仅读取该列最新版本的数据。此次支持根据timestamp值过滤数据,仅读取指定时间范围内更新的数据;支持读取HBase单元格的timestamp字段并写入去向表字段。
- 功能使用注意事项:
- 如果填写起始时间位点和结束时间位点,则会使用时间戳范围过滤条件进行读取HBase表数据。请按照格式:yyyy-MM-dd HH:mm:ss.SSS填写,其中“SSS”可不填,如不填则默认取000,系统执行时会将该值转成timestamp后从HBase中读取相应数据。支持填写系统参数和参数组参数。
- 如未填写起始时间位点,则默认从最早数据开始读取。如未填写结束时间位点,则默认读取至最新数据。
- 如果同时填写startRowKey、endRowKey和起始时间位点、结束时间位点,则会读取指定RowKey范围内指定时间戳范围内的数据;如果仅填写startRowKey、endRowKey,则会读取指定RowKey范围内的数据,不限时间戳范围;如果仅填写起始时间位点、结束时间位点,则会读取指定时间戳范围内的数据,不限RowKey范围。
- 任务配置字段映射时,来源表字段如选取timestamp字段,运行任务时,同一RowKey值对应的多列数据对应的timestamp值不同时,则timestamp字段值取timestamp最新的列对应的timestamp值。
- 优化后功能使用步骤:
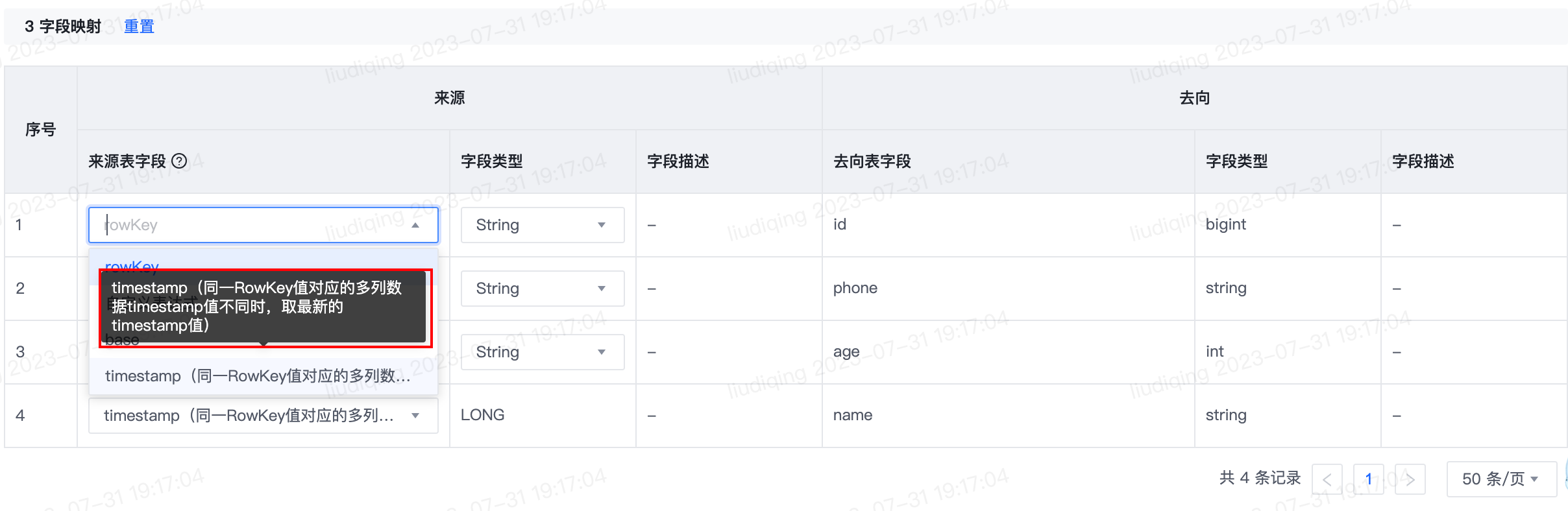
3.【实时同步任务】来源为Kafka、去向为结构化数据源时,支持获取最新表结构功能
- 功能介绍:
- 针对去向表表结构变更的各类场景,处置策略如下:
a.字段顺序调整:字段映射列表中按变更后的去向表字段顺序展示,并保留映射的来源表字段信息。
b.新增字段:字段映射列表中新增行,行序号为去向表中该字段的列序号。针对该行的来源表字段:先使用同名映射匹配是否存在同名的来源表字段,如存在同名字段则来源表字段置为同名字段,如不存在同名字段则清空来源表字段选择框的值。
c.删除字段:删除字段映射列表中的对应行
d.字段类型变更:更新“字段类型”列该字段对应的值
e.字段描述变更:更新“描述”列该字段的字段描述
此外,针对去向表的表结构变更,消息通知框中会详细提示各类变更情况以及相应的字段。
- 针对去向表表结构变更的各类场景,处置策略如下:
- 优化后功能使用步骤:
4.【实时同步任务】数据来源为Kafka时,适配版本和认证方式:2.0.1、无认证;2.0.1、Kerberos认证
5.【实时同步任务】新增“未知”任务状态
- 功能介绍:
- 针对联通yarn或k8s集群时,出现查询异常(无法联通或查询失败)时未获取到任务状态的任务,新增任务状态:未知。
- 功能使用注意事项:
- 此任务状态的任务不可启动、停止。启动中、运行中、停止中的任务可能会翻转为此状态。此状态可翻转为启动中、运行中、停止中、启动失败、运行失败。
6.【实时同步任务+离线同步任务+数据导入】获取队列时,如队列资源获取失败时,仅展示队列名称
- 功能使用注意事项:
Bug修复
1.【实时同步任务】修复任务任务类型为分库分表同步时,任务配置页面和任务执行时库表正则匹配规则不一致的问题
版本:v3.7.0
新增功能
1.【离线同步任务】离线同步任务对接发布中心
- 功能介绍:离线同步任务支持对接发布中心实现跨环境发布。
- 功能使用注意事项:
- 项目-集群下所有离线同步任务均可通过发布中心发布至接收方的开发模式/线上模式。
- 数据源、Hive库、参数组已对接发布中心的数据源映射/Hive库映射/参数组映射。如发布方任务使用的数据源、Hive库、参数组在发布中心已配置映射策略,则根据映射策略替换为接收方的数据源、Hive库、参数组,如此时接收方相应资源已被删除则任务检测不通过;如发布中心未配置映射策略则按照同名映射的规则替换为接收方的数据源、Hive库、参数组,如此时接收方不存在同名的资源则任务检测不通过。
- 如发布方任务引用了脱敏规则,按照同名映射的规则替换为接收方的脱敏规则,如此时接收方不存在同名的脱敏规则则任务检测不通过。
- 实际在接收方执行导入时,Hive库的替换逻辑为:优先按配置的接收方参数组的参数替换(如有),再按照Hive库映射配置的Hive库映射到的接收方库替换(如有),最后按照原始的发布方库。
2.【实时同步任务】数据去向新增支持Kudu数据源
- 功能介绍:
- 实时同步任务去向新增支持Kudu数据源。
3.【实时同步任务】数据去向新增支持Kafka数据源
- 功能介绍:
- 实时同步任务去向新增支持Kafka数据源。
4.【数据导入】数据导入配置支持复用
- 功能介绍: 此前,每次用户如需导入本地数据,需要完成如下步骤:上传文件、选择数据去向并配置字段映射。在周期性上传的场景中,每次重新配置任务操作较为麻烦,故此版本实现数据导入配置支持复用:支持编辑已有的导入配置、支持基于已有的导入配置上传新文件和查看导入记录。
功能优化
1.【实时同步任务】数据来源为Kafka时新增序列化格式:ogg-json、maxwell-json
2.【离线同步任务】支持配置日志打印信息,并丰富日志打印内容
- 功能介绍:
- 数据传输-配置管理模块支持配置日志打印信息:打印内容和打印间隔。打印内容中,如勾选传输行数、传输速率、传输耗时,则所有离线同步任务日志中均打印勾选项;如勾选传输百分比,则离线同步任务数据来源为关系型数据库时打印传输百分比。
- 日志打印任务基本信息和任务执行配置:作业基本信息含项目、集群、运行账号,任务执行配置以json的序列化格式进行打印,含reader、writer等信息。
- 日志打印任务细化的执行步骤: 1)来源是关系型数据库,执行步骤依次为:“开始切分来源端数据(切分键:xxxx,并发度:xxxx)”、“来源端数据切分完成(切分键:xxxx,并发度:xxxx)”、“开始读取来源端数据“、”来源端数据读取完成“;注意:如果来源未开启并发读取,则不展示切分的执行步骤。 2)去向是关系型数据库,执行步骤依次为“开始执行去向端PreSql,PreSql:xxxxx”、“去向端PreSql执行完成,PreSql:”、“开始向去向端写入数据”、“去向端数据写入完成”、“开始执行去向端PostSql,PostSql:xxxxx”、“去向端PostSql执行完成,PostSql:”。
3.【数据导入】数据去向为Hive时支持快速创建Hive表。
4.【离线同步任务】数据脱敏功能增强:支持使用基于自定义udf的脱敏规则、扫描时支持选择扫描执行队列
5.【实时同步任务】去向为Hive、Iceberg、Arctic时根据字段内容动态分区支持使用函数
6.【离线同步任务】ES读取优化:复杂字段类型设置支持用户选择读取模式:读取为string类型或系统推断字段类型
7.【离线同步任务】并发读取的切分键支持搜索,Hover显示完整展示字段名称
版本:v3.6.0
新增功能
1.【离线同步任务】数据来源和去向新增支持Iceberg数据源
- 功能介绍:
- 离线同步任务来源和去向新增支持Iceberg数据源。升级时默认隐藏Iceberg数据源,如有需要可通过Ops配置开启,配置文档:通过easyops修改支持的数据源类型。
- 配置任务时,如使用Iceberg作为数据来源,需保证配置任务的用户有对应表的读权限;如使用Iceberg作为数据去向,需保证配置任务的用户有对应表的写权限,否则用户无法成功选中表。
2.【离线同步任务】数据来源和去向新增支持TDSQL数据源
- 功能介绍:
- 离线同步任务来源和去向新增支持TDSQL数据源。升级时默认隐藏TDSQL数据源,如有需要可通过Ops配置开启,配置文档:通过easyops修改支持的数据源类型。
- 配置任务时,如使用TDSQL作为数据来源,需保证配置任务的用户有对应数据源的读权限;如使用TDSQL作为数据去向,需保证配置任务的用户有对应数据源的写权限,否则用户无法成功选中数据源。
3.【实时同步任务】数据去向新增支持Arctic数据源
- 功能介绍:
- 实时同步任务去向新增支持Arctic数据源。升级时默认隐藏Arctic数据源,如有需要可通过Ops配置开启,配置文档:通过easyops修改支持的数据源类型。
- 配置任务时,如使用Arctic作为数据去向,需保证配置任务的用户有对应表的写权限,否则用户无法成功选中表。
功能优化
1.【离线同步任务】支持基于HiveJDBC读和写版本为1.1.0-CDH5.14.0的Hive
- 功能介绍:
- 离线同步任务数据来源和去向支持选取版本为1.1.0-CDH5.14.0、传输协议为Hive JDBC的Hive数据源,传输任务会基于HiveJDBC协议读和写Hive表。
功能使用步骤:
- 1、前往项目中心(新)登记Hive数据源。版本选中:1.1.0-CDH5.14.0,传输协议选中:Hive JDBC。

- 2、传输任务数据来源侧选中已登记的数据源,选择库表并按需配置数据过滤条件和特殊字符替换。
注意:Hive版本为:1.1.0-CDH5.14.0,传输协议为:Hive JDBC时,读取方式为基于Hive JDBC读取数据

3、传输任务数据去向侧选中已登记的数据源,选择库表,并按需完成相关配置。

分区:如Hive表为分区表,请填写分区值;如Hive表为非分区表,任务配置时不会展示分区配置项。写入规则:Hive版本为:1.1.0-CDH5.14.0,传输协议为:Hive JDBC时,写入规则支持Insert into(追加数据)和Truncate then append(清空表数据后插入数据)。需要注意:Truncate then append系统写入时会分为两条SQL执行,先清空表数据,再插入数据,如在清空表数据后、插入数据前任务报错,则表中对应数据会为空。
批量条数:1)一次性批量提交的记录数大小。该值可以极大减少数据同步系统与数据源的网络交互次数,并提升整体吞吐量。如果该值设置过大,会导致数据同步运行进程OOM异常。2)每提交一批记录,HiveServer就会向YARN提交一个MapReduce任务,如果写入记录数多则会提交较多的任务,占用大量集群资源。
- 1、前往项目中心(新)登记Hive数据源。版本选中:1.1.0-CDH5.14.0,传输协议选中:Hive JDBC。
2.【离线同步任务】支持批量运行和批量提交任务
- 功能介绍:
- 支持批量运行和批量提交任务,提升批量场景下的操作效率。
- 功能使用注意事项:
- 如命中以下任一条件,则任务不可批量运行。1)当前用户账号缺少该任务的“运行&上线&下线”权限;2)当前任务正在运行中;3)任务审批中,不可运行;4)任务审批不通过,不可运行。
- 如命中以下任一条件,则任务不可批量提交。1)当前用户账号缺少该任务的“运行&上线&下线”权限;2)任务审批中,不可提交;3)任务审批不通过,不可提交。
3.【离线同步任务】Kafka适配新的版本和认证方式:2.3.1、无认证;2.3.1、sasl_plaintext认证;2.7.1、无认证;2.7.1、sasl_plaintext认证。
- 功能介绍:
- 离线同步任务Kafka作为来源和去向适配新的版本和认证方式。
4.【离线同步任务】DM适配8.1版本
- 功能介绍:
- 离线同步任务DM作为来源和去向适配版本:8.1。
5.【离线同步任务】支持通过SQL模式读取平台内置Hive数据源
- 功能介绍:
- 离线同步任务的任务模式为SQL模式时,数据来源的数据源类型新增Hive,支持选取平台内置的Hive数据源。
6.【离线同步任务】任务查询Oracle时使用绑定变量
- 功能介绍:
- 任务查询Oracle时使用绑定变量,优化SQL查询效率
7.【离线同步任务】Clickhouse适配Spark3.3
- 功能介绍:
- 离线同步任务Clickhouse作为来源和去向适配Spark3.3