快速上手
使用流程

第一步:登记数据源
在项目中心(新)登记数据源,详见平台整体-控制台用户手册,此处不作赘述。
第二步:登记流表
1. 创建逻辑库
- 使用实时管理员及以上角色登录平台,选择 实时开发 。
- 选择左侧边栏 实时数仓 ,打开数仓选择页面。
- 单击
 流表管理,进入流表管理页面。
流表管理,进入流表管理页面。 - 单击
 创建库 , 进行逻辑库创建。
创建库 , 进行逻辑库创建。
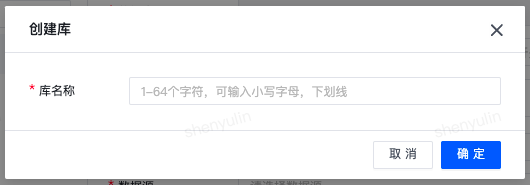
| 说明: 库名在同一项目内不可重复,建议根据 业务主题域 或 实时数仓分层 进行库名定义。 |
2. 创建流表
- 在流表管理页面,单击目标逻辑库,表单页面左上角显示对应库名表示切换成功。
- 单击 创建表 按键,进行表创建。
- 单击 保存 ,完成流表注册。
文档以Kafka类型流表创建作为样例进行说明。
| 表单参数 | 说明 | |
|---|---|---|
| 数据库 | 当前流表归属的逻辑库,默认置灰不可修改。用户可通过切换逻辑库重新创建表来更改数据库的值。 | |
| 表名 | 流表名称,任务开发时将直接使用此名称。 | |
| 描述 | 流表描述,通常用于描述流表的业务含义。 | |
| 数据源类型 | 选择流表对应的数据源类型。 | |
| 数据源 | 选择流表对应的数据源名称,此处仅展示当前项目获取使用授权的数据源。 | |
| Topic | 手动输入需要映射的Kafka Topic名称,多个Topic间使用 ; 进行分隔。注意:多个Topic的表结构需保持一致,否则任务运行会报错。 |
|
| 序列化方式 | Kafka Topic内数据的编译方式,支持Json、csv、avro、string、ua、ndc、canal-json、debezium-json、maxwell-json 等方式。
|
|
| 字段信息获取方式 | 支持 DDL解析 、 数据解析和从数据库获取 三种方式。 自动解析:所有流表数据源类型均支持 数据解析:数据源类型为Kafka、RocketMQ、Pulsar且序列化方式为 json、canal-json、debezium-json、maxwell-json时支持 从数据库获取:数据源类型为MySQL、Oracle、Elasticsearch、HBase、Kudu 时支持 |
|
| 字段信息 | 支持用户手动设置字段名与类型,当字段类型为array、map、row类型时支持设置嵌套字段,
|
|
| 配置 | 支持自定义配置Flink高级参数,由于不同引擎版本参数不同,在使用过程中请注意对应引擎版本。 |
(1)消息队列
1. Kafka
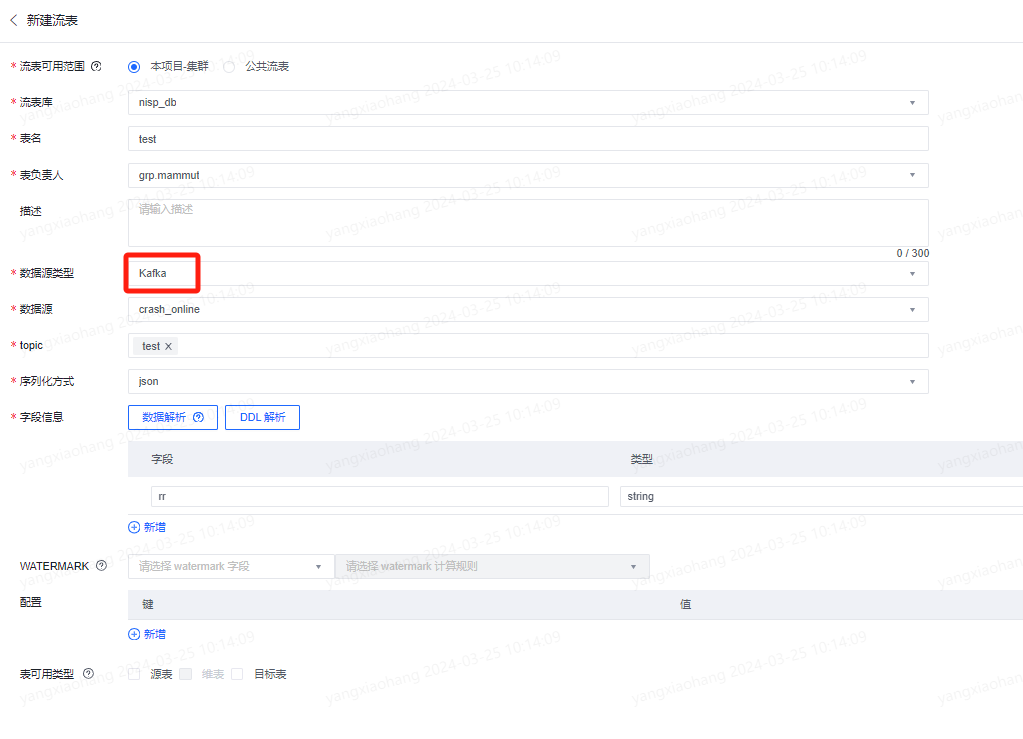
1、数据源类型选择Kafka
2、选择topic,支持下拉选择,也支持自主填写。
3、填写字段,kafka数据源支持从数据源读取数据后解析字段自动生成,也可选择直接复制DDL解析。
4、填写WATERMARK(注意WATERMARK需要timestamp(3)字段)
5、点击保存(勾选不进行语法检查则直接保存)。
2. RocketMQ
登记方式同Kafka,但是目前RocketMQ暂不支持数据解析方式获取字段。
3. Pulsar
登记方式同Kafka,但是目前Pulsar暂不支持数据解析方式获取字段
(2)关系型数据库
1. MySQL
1、数据源类型选择mysql,按照指引选择对应的库表。
2、填写字段,关系型数据库支持直接从源库表中获取字段不必用户自己填写。
3、mysql无需填写WATERMARK。
4、点击保存
2. Oracle
Oracle 填写方式同Mysql。
(3)NoSQL
1. ElasticSearch
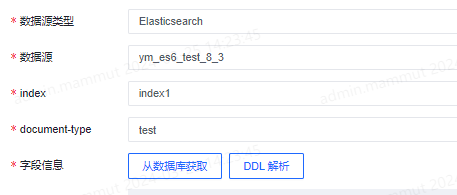
ES中当选择数据源后无需再填写库表,但是需要选择索引,在6.x版本中document-type字段已经被废弃,所以如果数据源是7.x的版本document-type字段无需填写。
ES支持从数据库中获取字段信息并自动解析。
2. Hbase
填写方式同MySQL。
3. Kudu
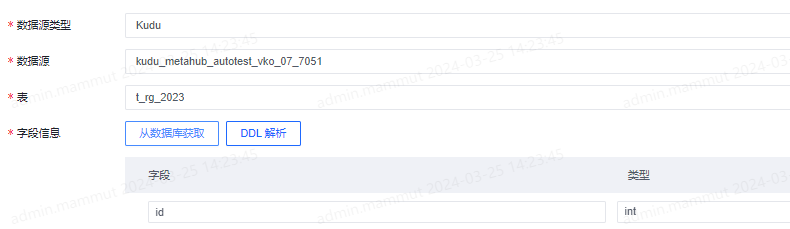
Kudu数据源只需填写数据源和表,字段信息可以直接从数据库中获取。
(4)数据湖
1. Iceberg
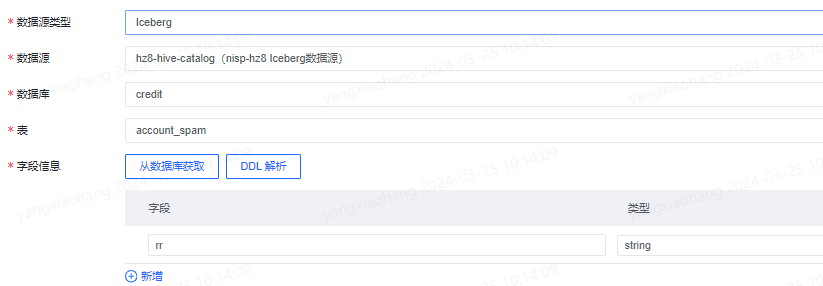
数据源选择时,选择该集群的Iceberg数据源即可。其余配置与Mysql登记相同。
第三步:创建流表
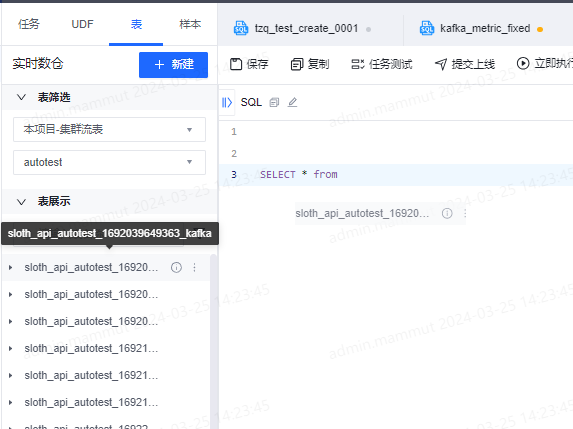
1、进入sql任务开发页面。
2、编写sql任务,使用时可以如上图所示直接打开表tab页面拖拽流表到任务中指定位置。
3、提交运行 使用流表时,SQL中无需额外执行create table,系统会自动去获取数据源信息。