Doris
离线同步任务支持Doris数据源,支持该数据源的抽取(Reader)和导入(Writer),当前支持的版本为:0.14.0、0.14.13.1、0.14.12.7、1.1.0、1.1.1。
使用前提
在使用之前需要在项目中心(新)完成Doris数据源的登记并测试通过。
数据源登记过程中,需要填写如下信息:
- 数据源名称:Doris数据源的名称
- 数据源标识:仅允许包含英文小写、数字、下划线,只允许英文小写开头,最大长度为64个字符。平台内唯一,保存数据源后数据标识不可修改
- 归属项目:由于元数据中心是项目组级别,因此此处支持选择项目组下的项目,默认为当前项目名称
- 负责人:默认为当前创建人员
- 协助管理员:同负责人,有该数据源的管理权限,包括编辑、设置“源系统账号映射”。可在安全中心为自己或其他人设置该数据源的使用权限
- 数据源连接:根据jdbc:mysql://SeverIP:Port/Database格式进行填写
- fenodes:FE上的http server地址
- 用户名:填写访问数据源的用户名
- 密码:填写用户名所对应的密码
|
唯一性校验规则:基于数据源连接进行校验。 |
数据源配置完成后,需点击测试连接按钮进行测试,测试通过后才可使用。
除了数据源需要准备之外,进行离线同步任务创建和数据源的使用都需要在安全中心-功能权限中添加相应的权限(可参考数据传输权限、元数据中心权限)。
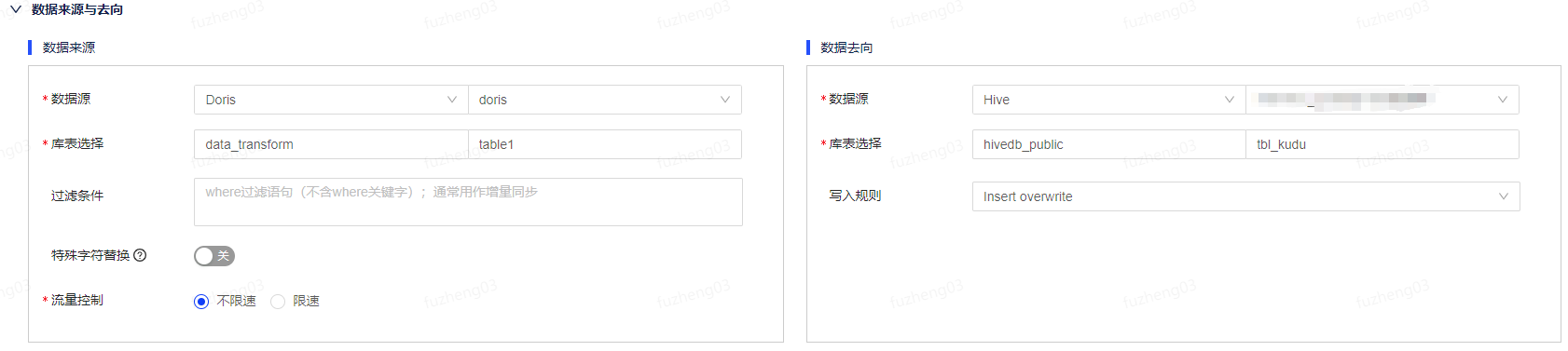
Doris作为数据来源
以Doris to Hive为例,在数据来源端选择Doris数据源类型及数据源名称,选择需要进行读取的schema和表。数据过滤支持填写where过滤语句(不含where关键字),通常用作增量同步,支持系统参数和参数组参数。特殊字符替换、并发读取、流量控制根据实际情况进行填写。
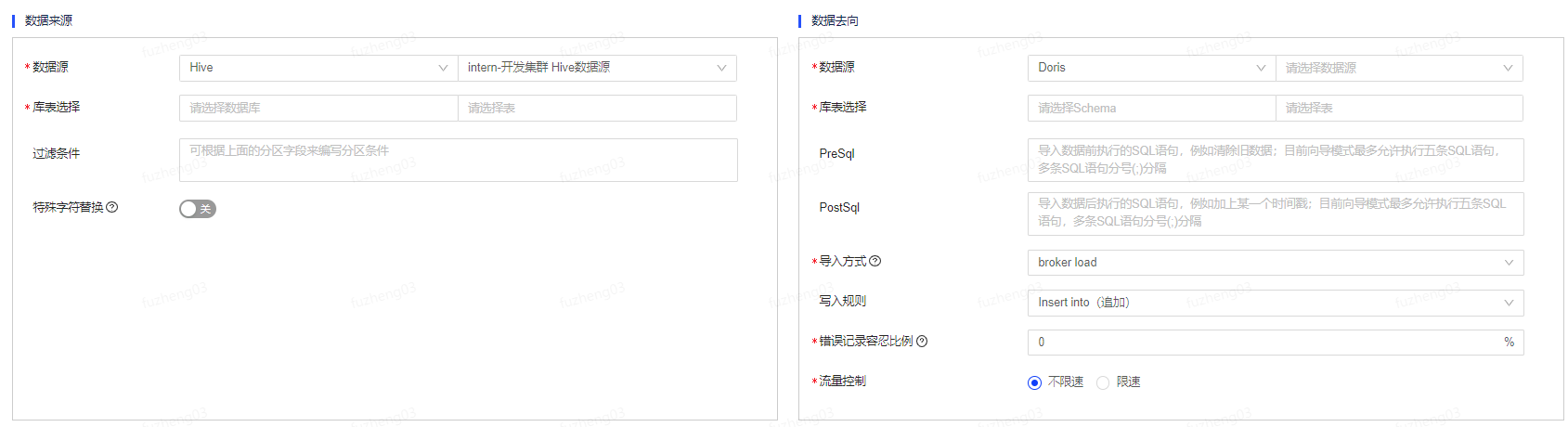
Doris作为数据去向
以Hive to Doris为例,当Doris作为数据去向时,除了需要填写数据源类型、数据源等基础信息之外,还可以填写PreSql和PostSql。
- PreSql:导入数据前执行的SQL语句,例如清除旧数据;目前向导模式仅允许执行五条SQL语句,多条SQL语句通过“;”分隔,最大长度为2000个字符。
- PostSql:导入数据后执行的SQL语句,例如加上某一个时间戳;目前向导模式仅允许执行五条SQL语句,多条SQL语句通过“;”分隔,最大长度为2000个字符。
Doris支持两种数据导入方式:stream load和broker load。
- stream load:读取登记数据源的数据时,建议使用stream load导入方式(例如mysql to doris)。
- broker load:读取平台内部hive表数据、数据量在几十到百GB级别时,建议使用broker load导入方式(要求Doris与Hive在同一kdc下)。
此外,当选择broker load时需要填写错误记录容忍比例。错误记录容忍比例指的是最大容忍可过滤的错误记录比例,默认零容忍。任务运行时,如果错误记录的比例超出错误记录容忍比例,则任务运行失败。
Hive to Doris场景支持复杂类型转换,当数据来源端字段类型为:map、array类型时,支持转为json写入去向端。

读取数据时,数据来源端字段类型为map、array时,默认转为json格式的字符串。写入数据时,stream load导入方式下支持使用csv或json的序列化格式写入数据,默认序列化格式为csv。如果需要用json格式,则需要在高级配置的任务参数中自定义参数target.loadFormat:json。
使用说明
当前版本支持Doris新版Spark Connector,可在控制台或任务当中添加高级配置参数。
在控制台登记Doris时,高级配置添加:transfer.version=1.1.0
在任务中添加高级配置:transfer.version=1.1.0、ndi.spark.forbid-set-stream-handler-factory=false

为了避免在控制台添加版本号后,影响所有使用该数据源的任务,因此建议在任务中添加高级配置。驱动优先级:任务高级配置 > 数据源高级配置 > 数据源版本。