INFO-spark任务排查示例
INFO-spark任务排查示例
适用模块
数据传输、sql节点spark引擎、spark节点等具体说明
spark 任务异常排查使用示例
场景一、通过Spark UI 定位任务
通过在SparkUI查看Spark程序运行的详细信息(各阶段耗时等),从而进行任务针对性调优等操作
1、点击猛犸平台日志中的app_id,跳转至SparkUI或Yarn,可以查看完整的日志信息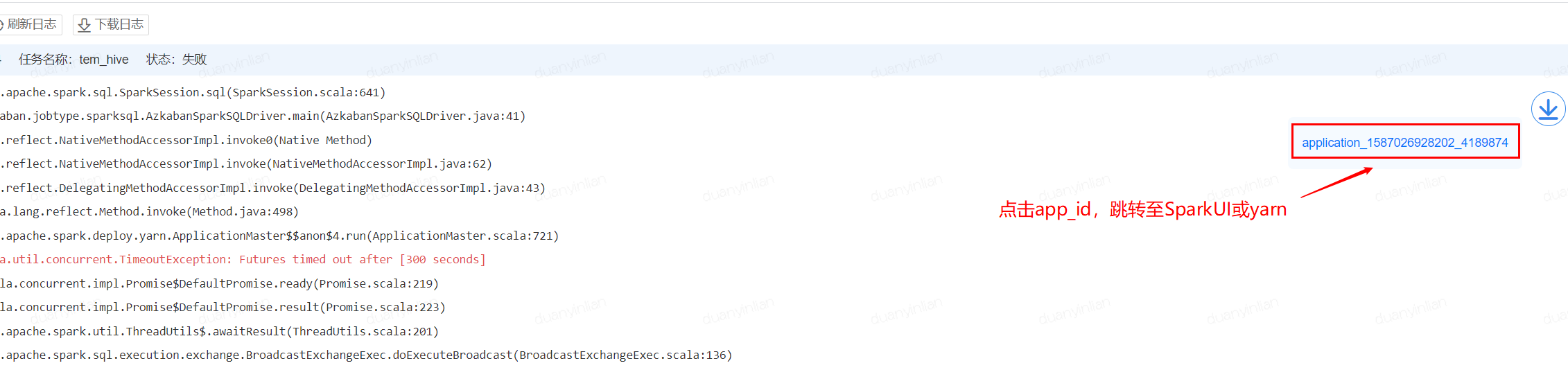
若无跳转按钮可在日志找到application id 通过konx跳转
找到具体app点开
2、跳转至Yarn界面: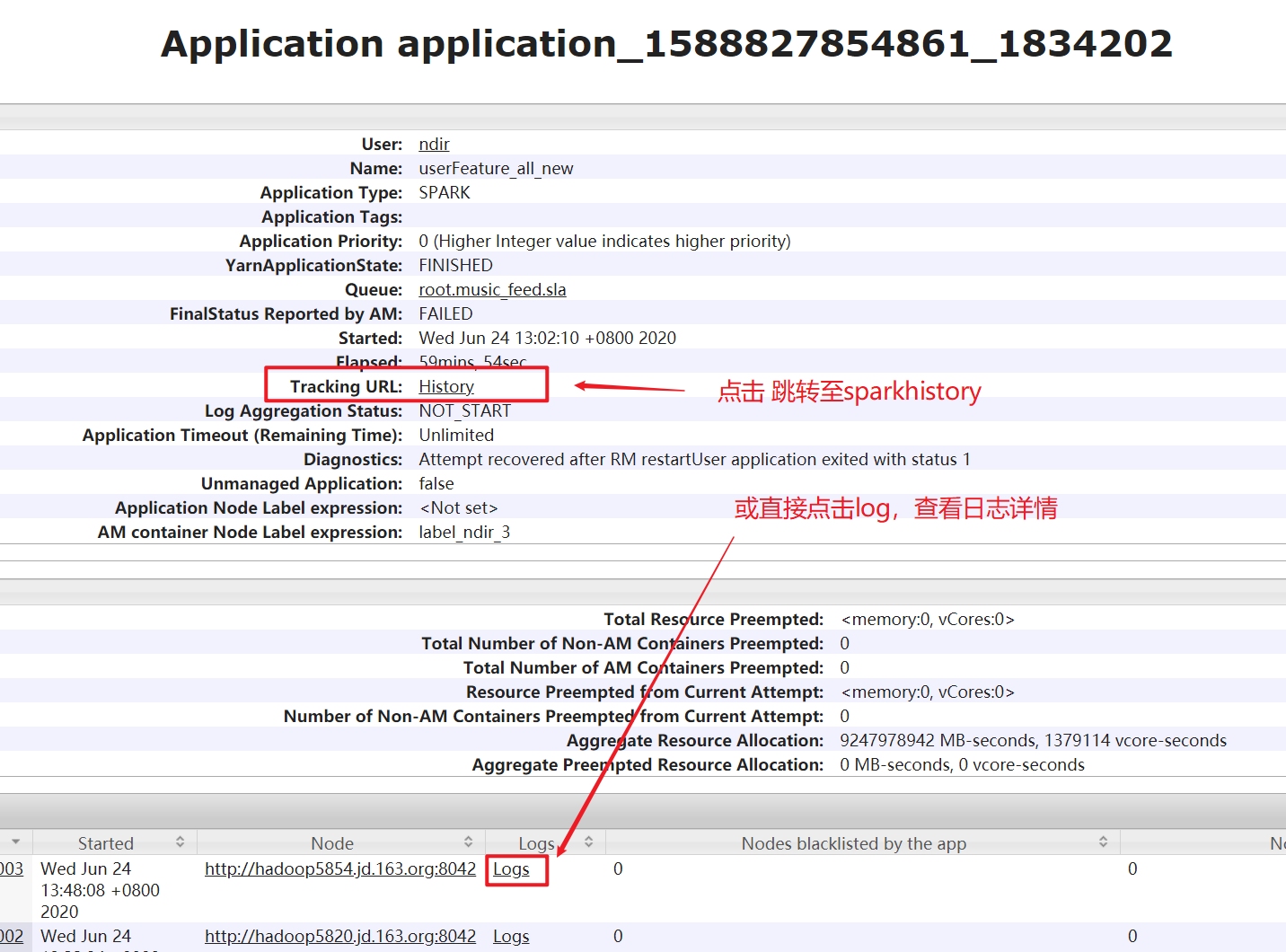
3、在SparkUI页面排错
在task失败信息中查看 job -- stage -- task
3.1、进入失败的job中,查看各个stage的详情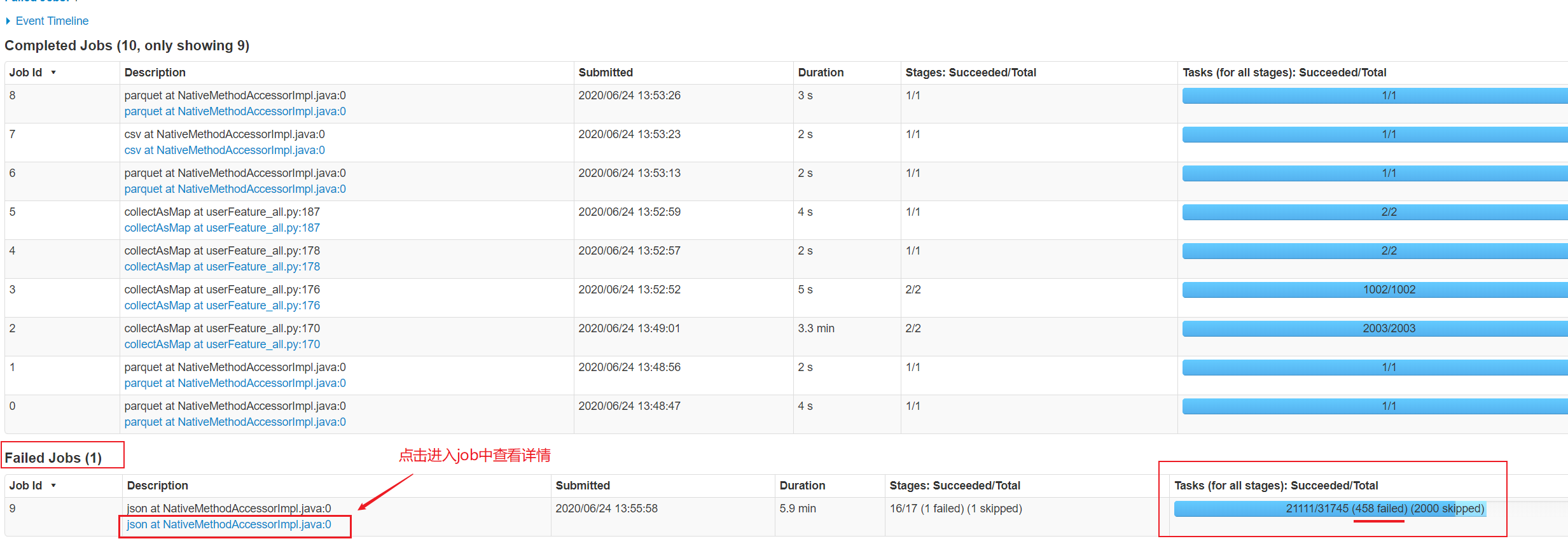
3.2、 进入失败的stage中查看各个task详情,也可在旁边直接预览失败信息
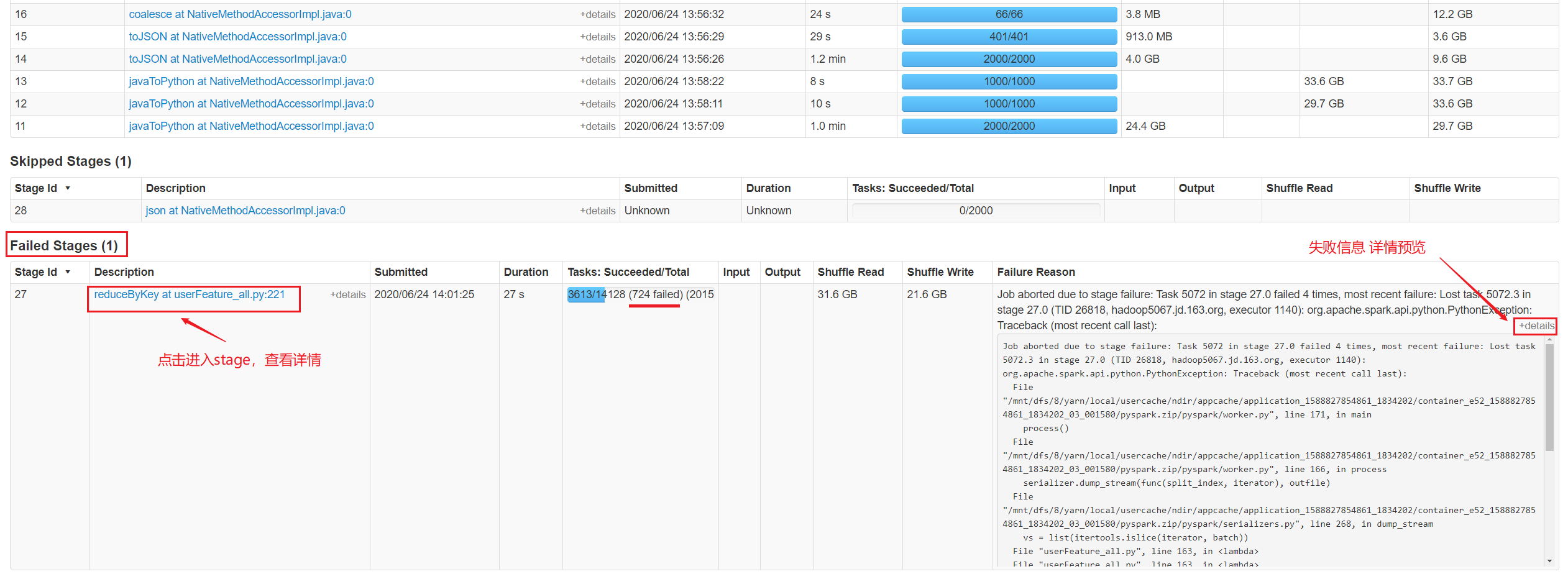
3.3、 查看task详情

若task失败的信息不够详细,可以查看driver、executor的日志
4、 直接查看失败的task所在的executor的详细日志

5、 查看driver、executors的详细日志

场景二、离线开发sql节点
例如用户反馈spark代码写了overwrite一个分区文件。但最终文件目录为空。: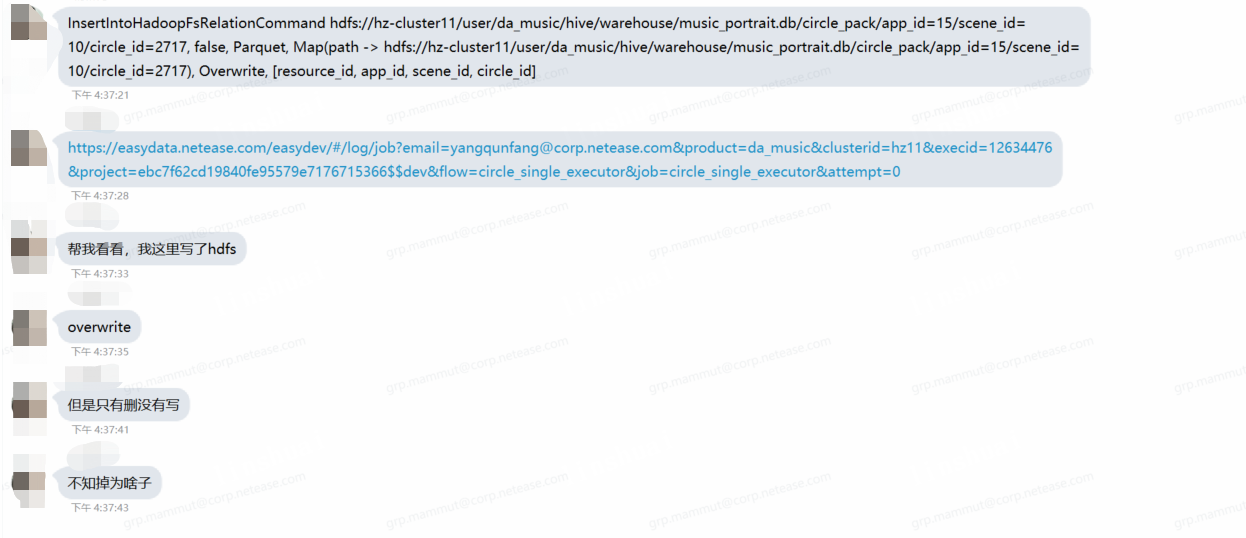
1、确认文件是否不存在: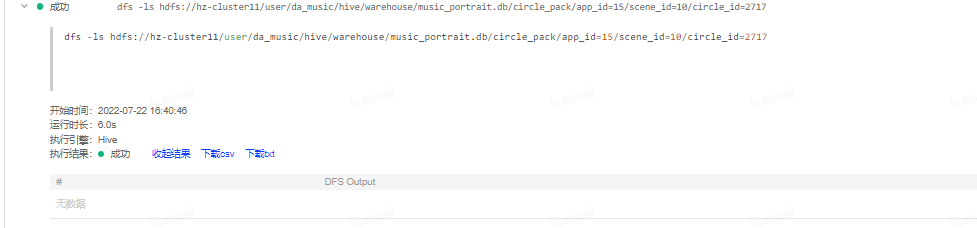
2、根据用户提供的spark日志链接进入sparkui
点击sql tab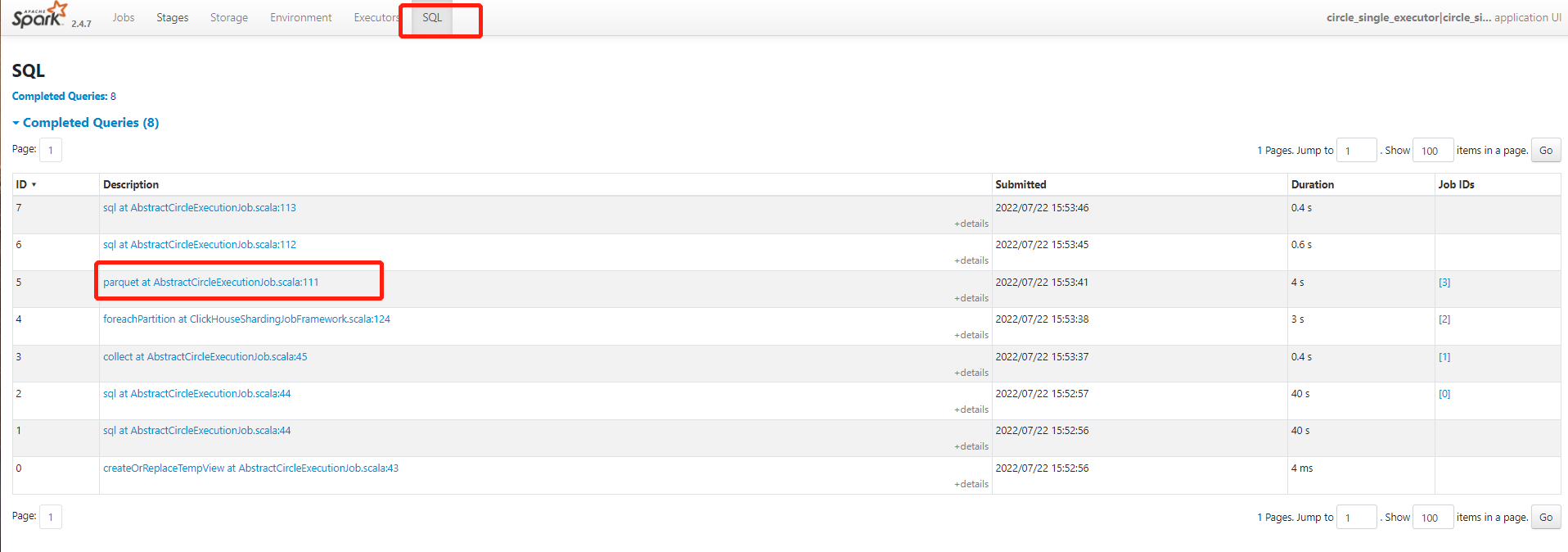
查看parquet这里,结合用户的反馈,可以知道这里是在写数据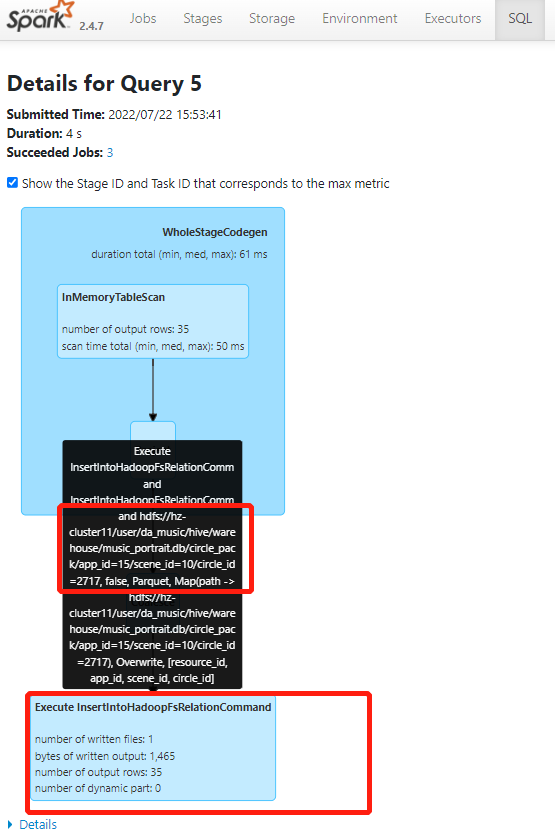
如图可知,最终给用户反馈的这个hdfs分区路径,写入了35条数据。
3、所以推测,数据是写入的。可能后续的一些操作。删除掉了
继续看这个操作的后两个query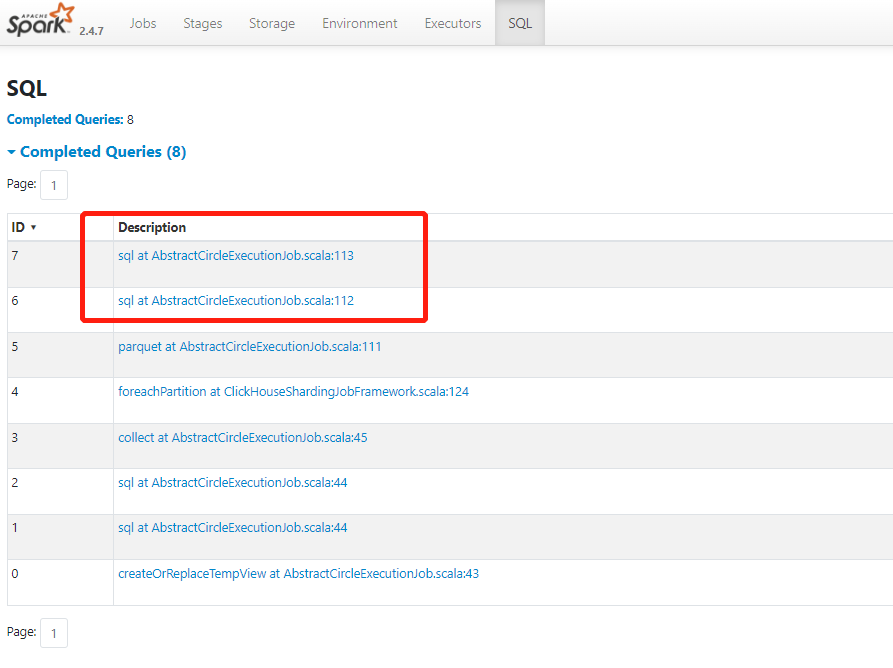
点击倒数第二个,查看执行计划。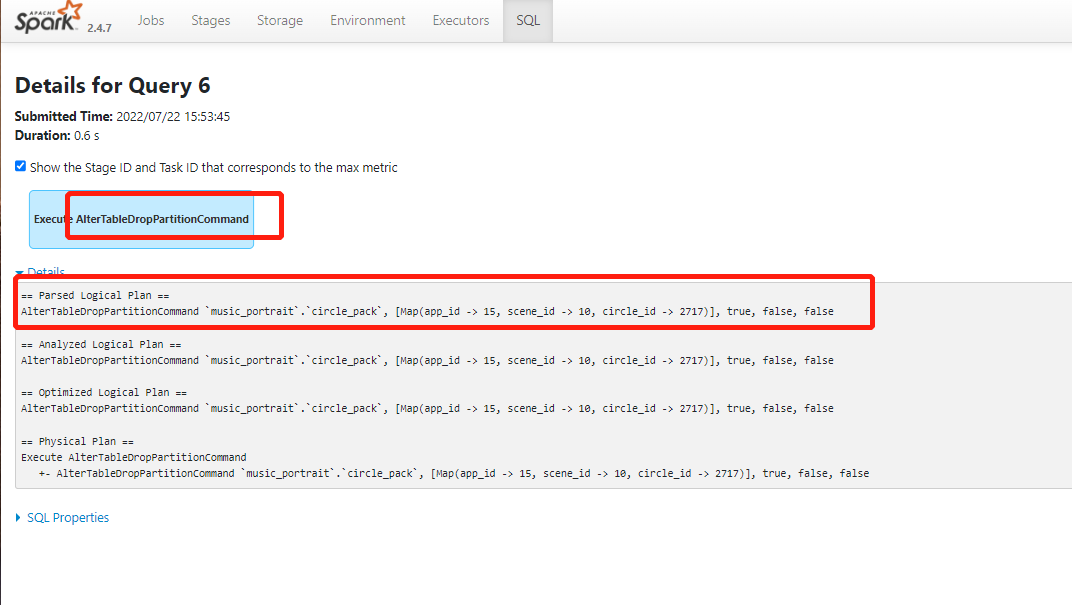
可以看出,用户的代码中又执行了对这个分区的drop partition操作,推测用户可能是内部表,所以hdfs文件随着用户的drop partition操作一并删掉了。从这里拿到表名。自行查看。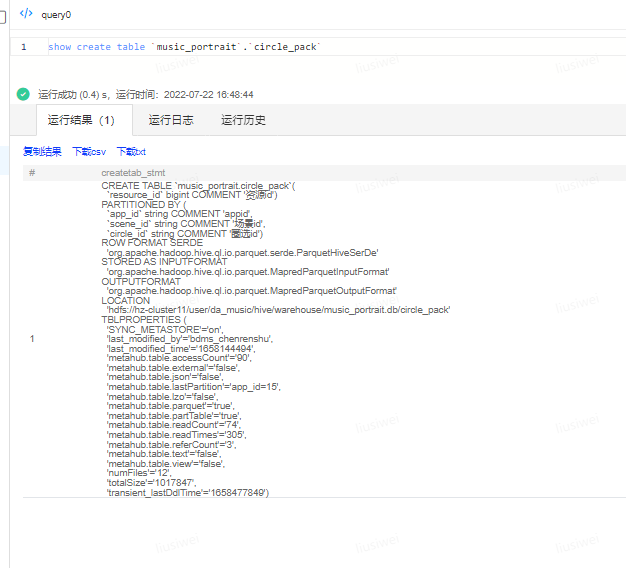
确认是内部表,用户确实执行了drop partition 最后又执行了add partition。用户这里是把内部表当成外部表了。故出现了这个问题。
场景三、数据传输
1、通过运行结果找到运行记录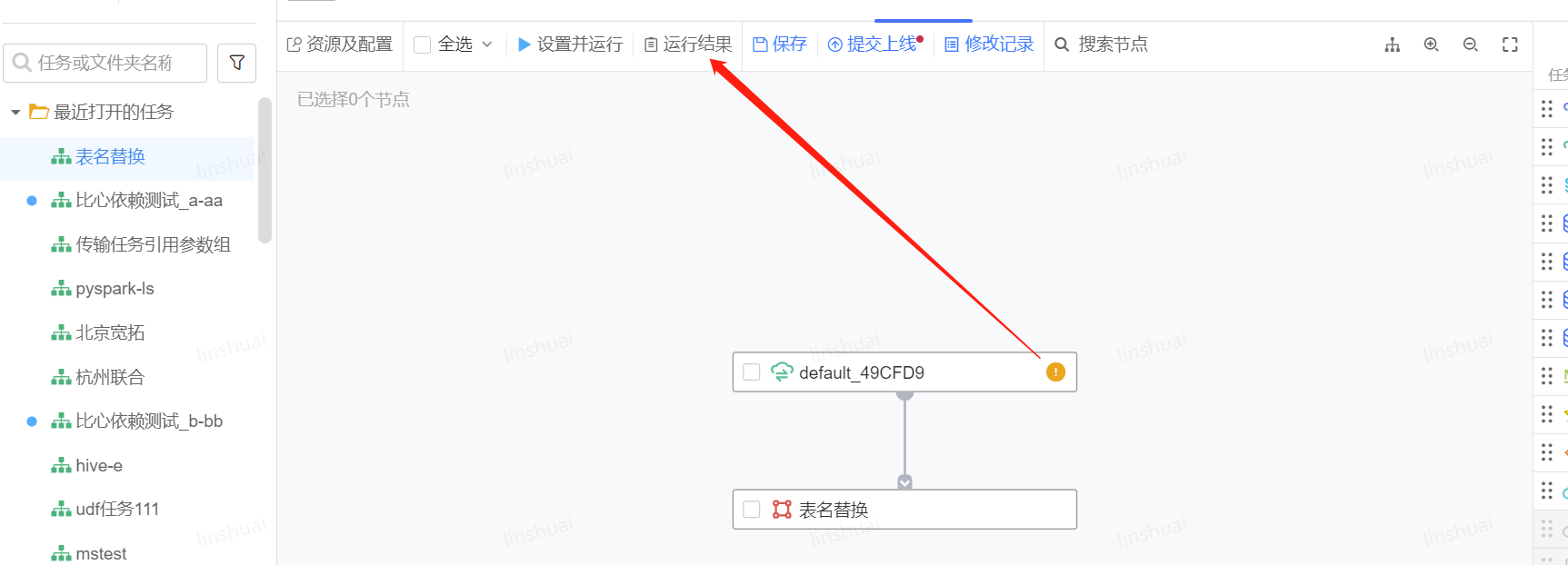
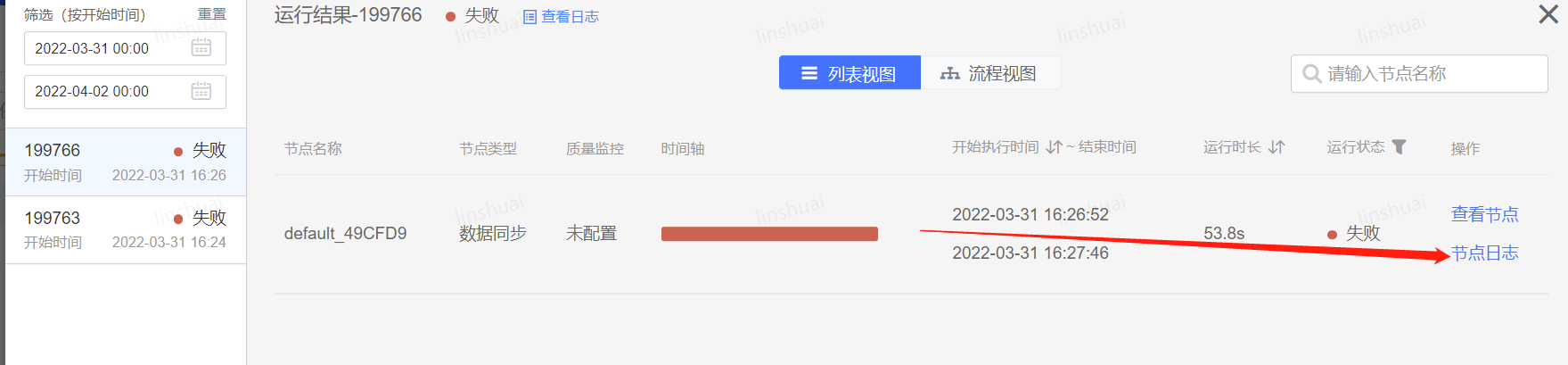
2、查看节点日志
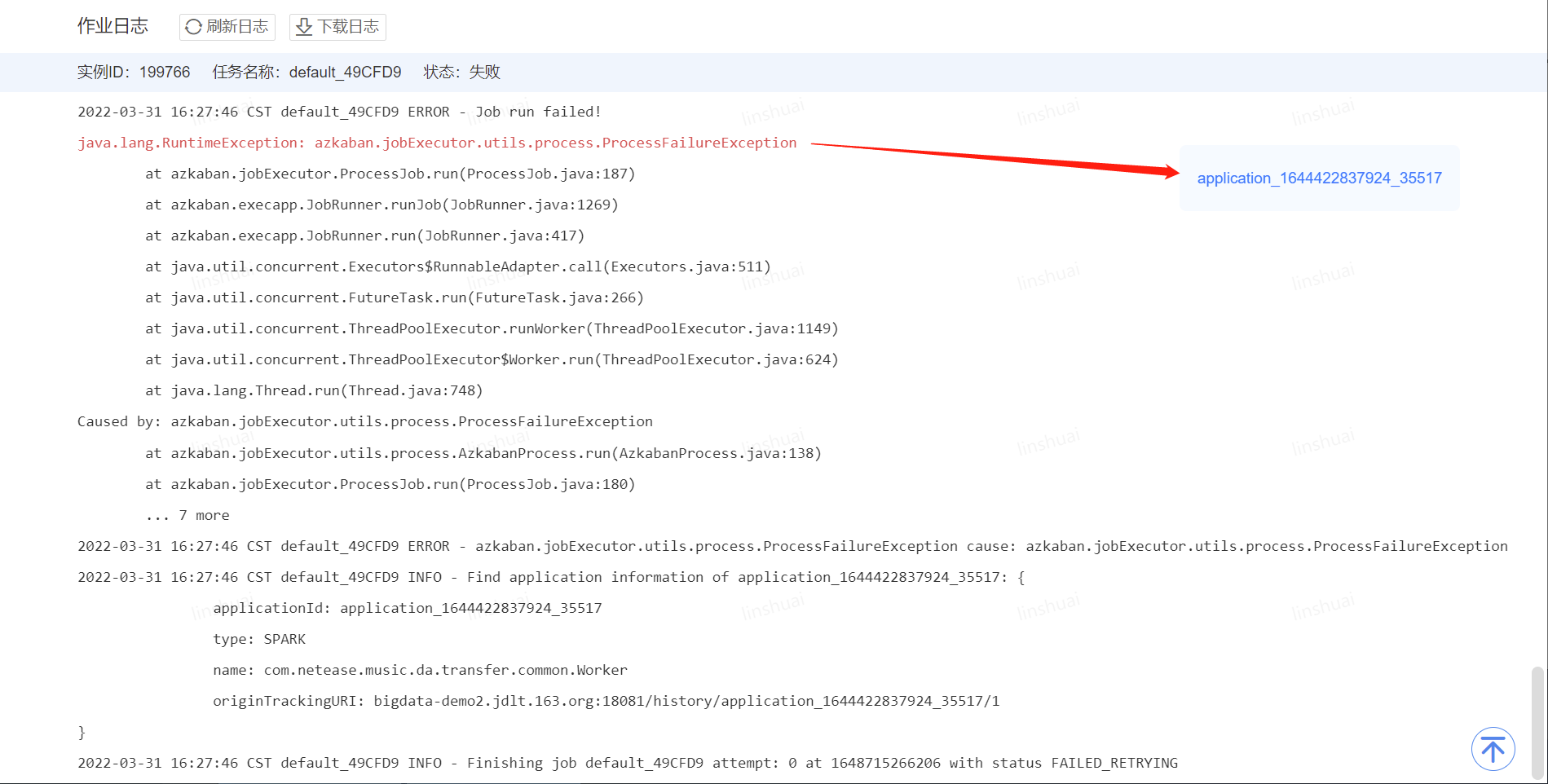
3、如下展开Executors或者NetEase Executors
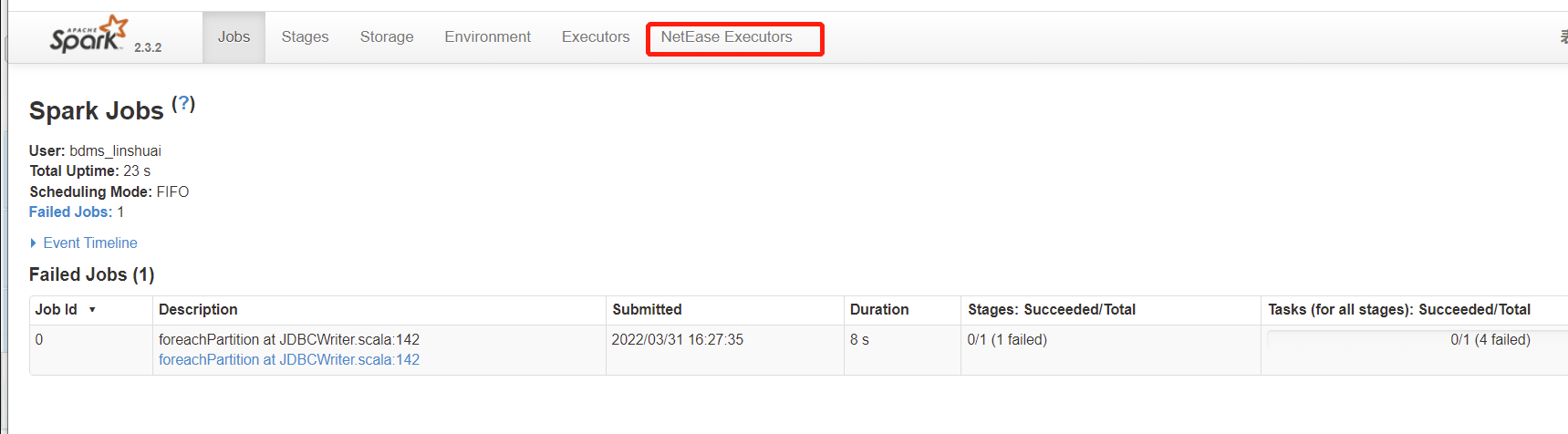
优先查看异常项,若无明显异常项可查看driver 与executor日志
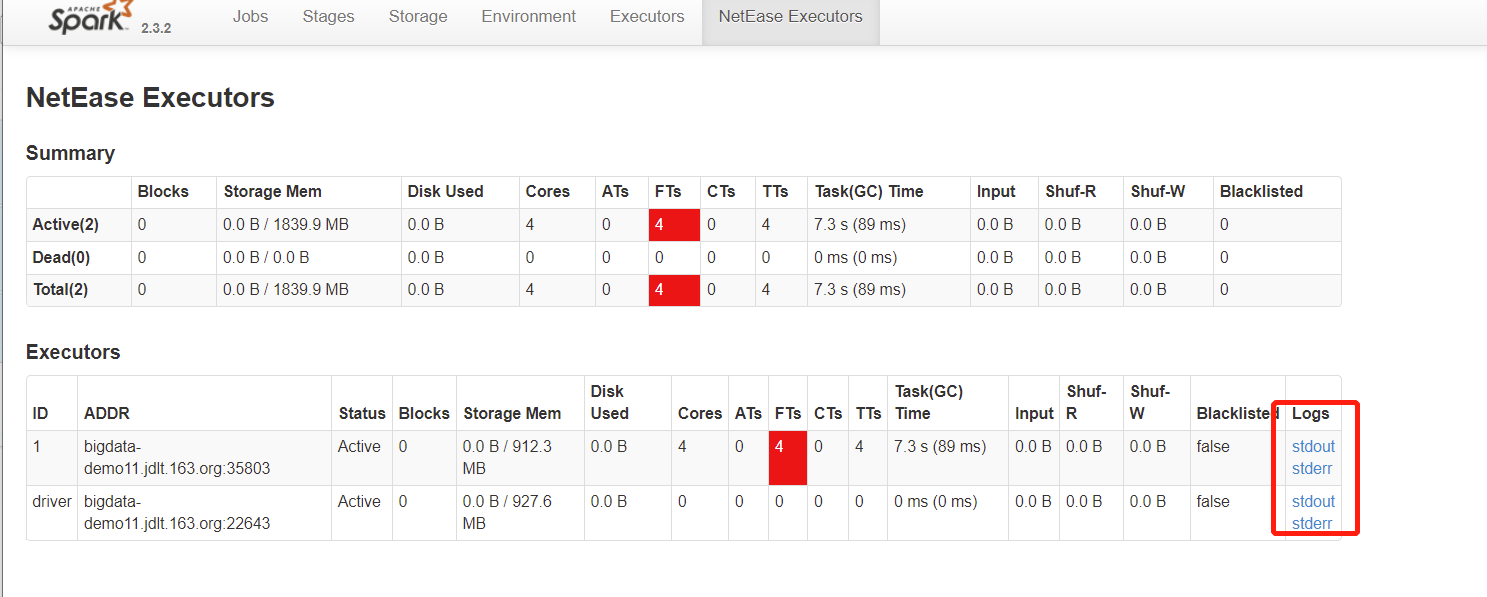
如下图,报错原因为表不存在(注:如遇到xxx.xxx.xxx.xxx:6080的报错可忽略)

场景四、数据质量(DQC)
目前数据质量中心通过用户配置的逻辑生成相应的sparksql,然后通过spark计算引擎产生相应结果,在配置和试跑的过程中如果遇到问题,可参考如何排查问题的项目示例,个别情况具体问题还需要具体分析。
使用示例
1、通过数据质量中心-执行实例-日志
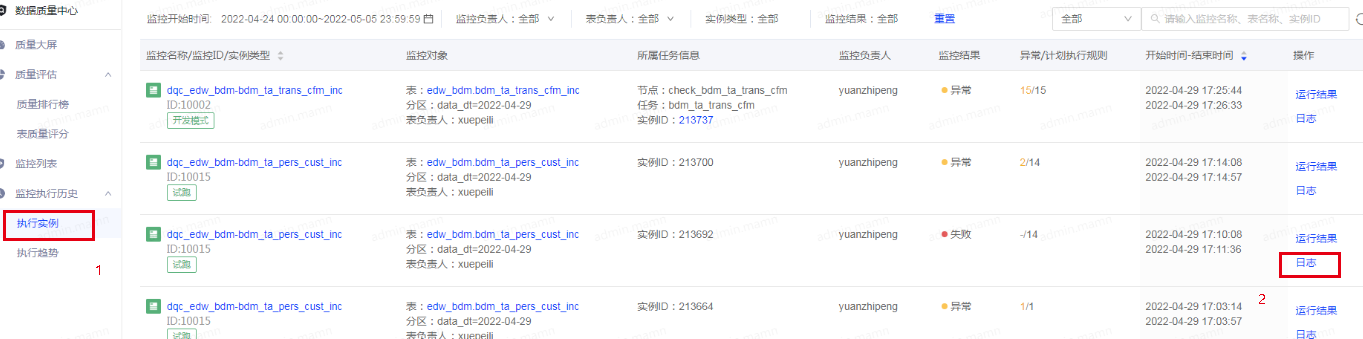
2、找到application的id号,或者直接把日志拉到最下方可找到applicationid

3、到yarn ui-点击applications(1)-到search搜索栏输入之前找到id号(2)-点击application-xxxx(3)
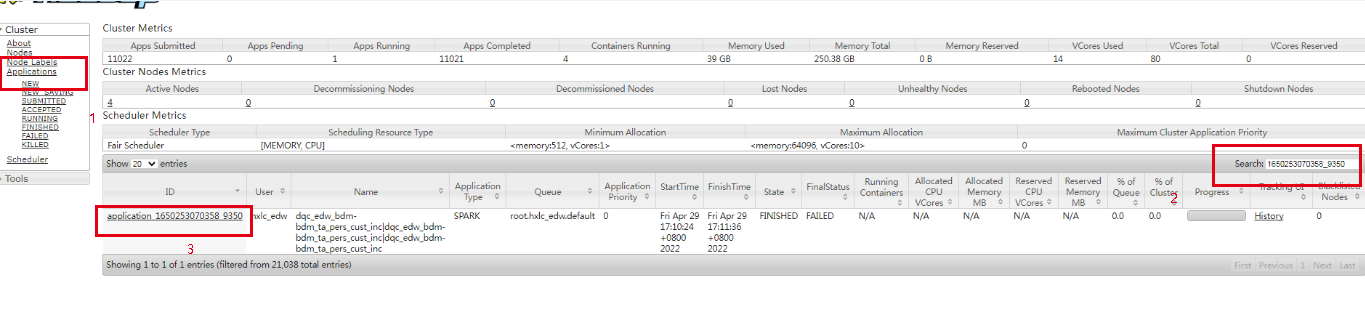
4、可在Diagnostics看日志或者进入history直接看spark日志
spark日志可参考:
https://study.sf.163.com/documents/read/service_support/dsc-p-a-0009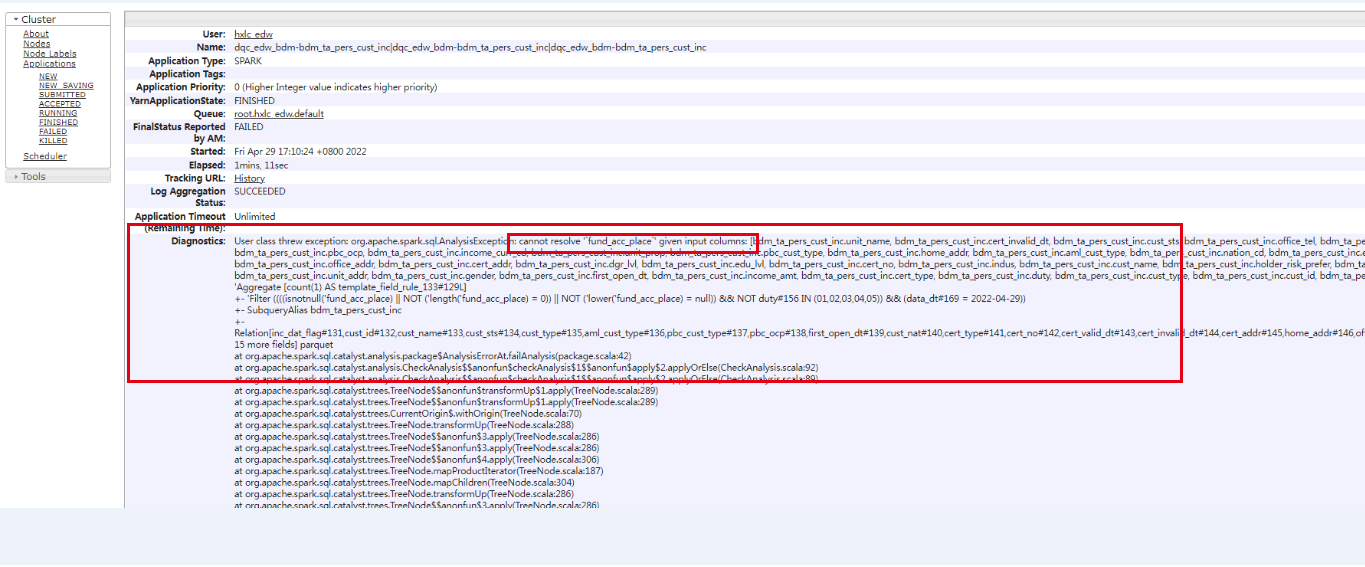
场景五、spark任务跑完后数据不一致
用户反馈补完数据没有数据
1、首先排查sparkui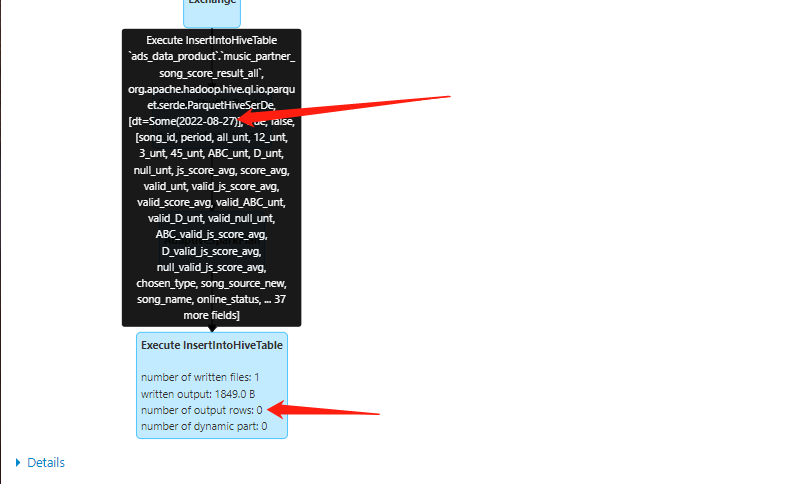
2、确实目标表没有插入数据,0rows。接着排查源表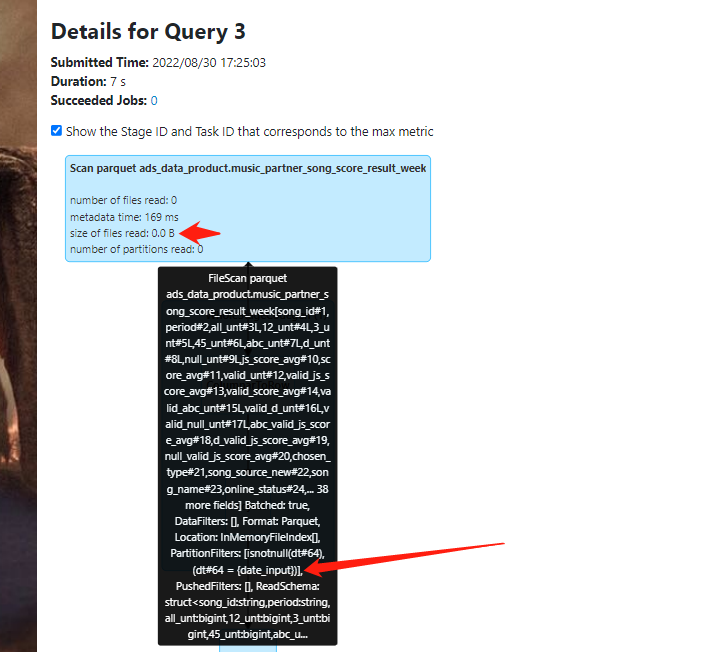
然后发现源表在scan时候 files也是0,怀疑分区写错了。仔细查看,分区是变量名而不是具体日期,这里高度怀疑。sql中分区写错了。接着检查。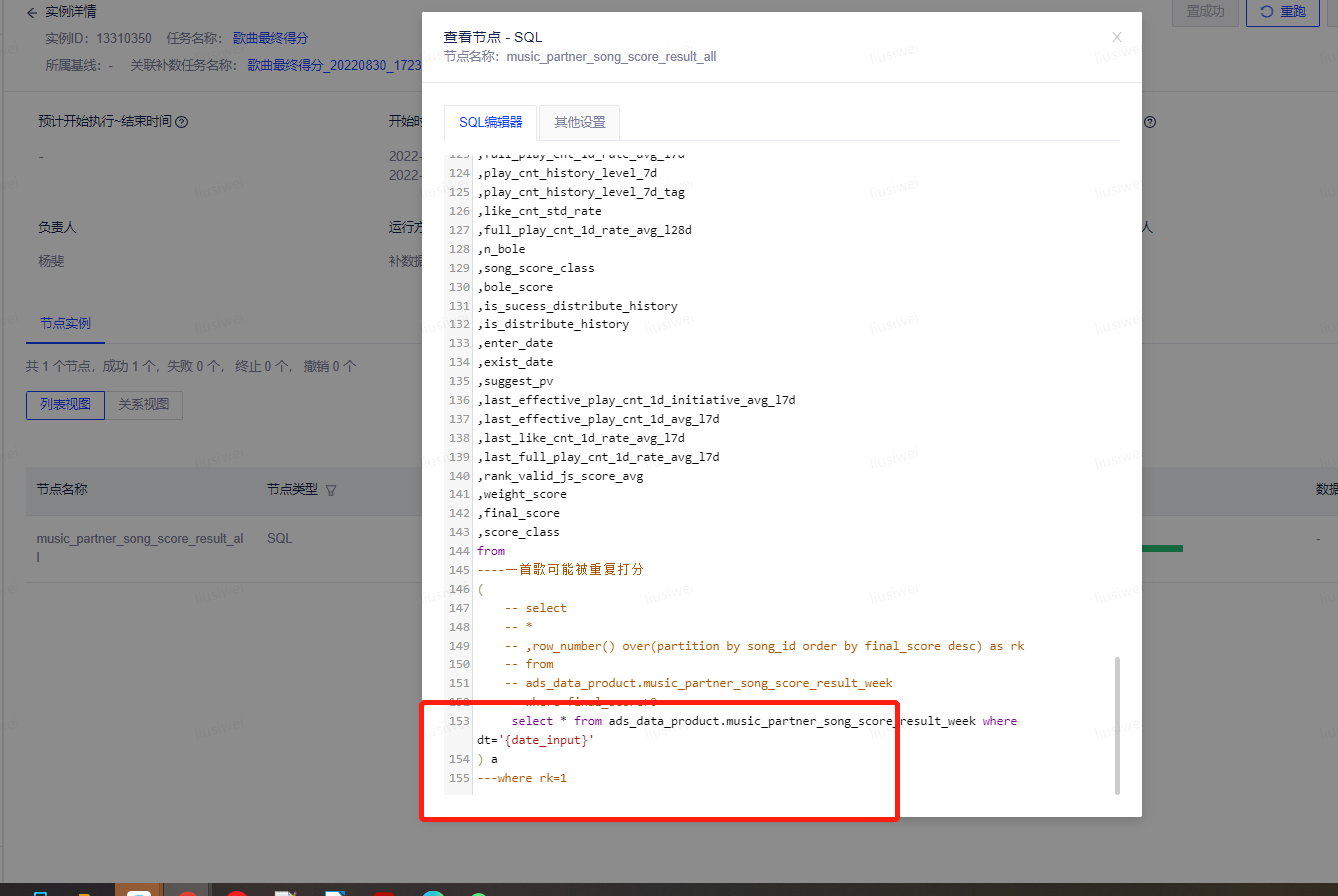
果然这里少了$,导致分区变量没传进去。该问题原因明确。
场景六、逻辑一样,结果不一样
用户反馈这两段逻辑一样的union sql,结果跑完不一样,需要分析原因。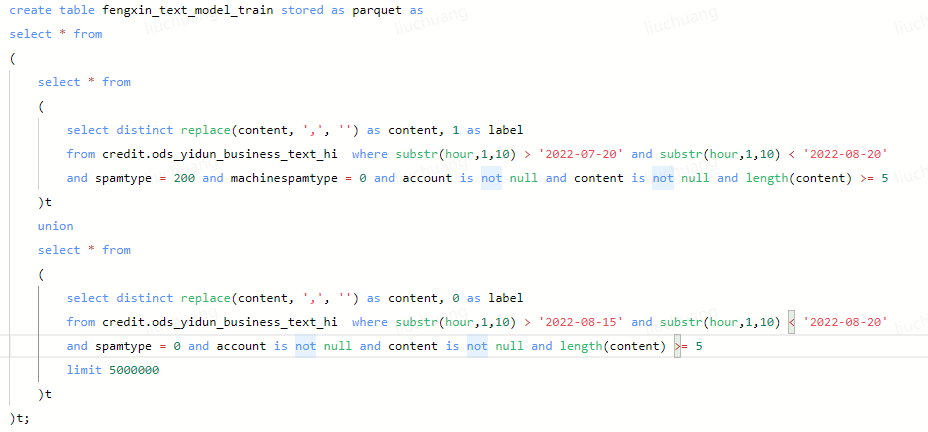
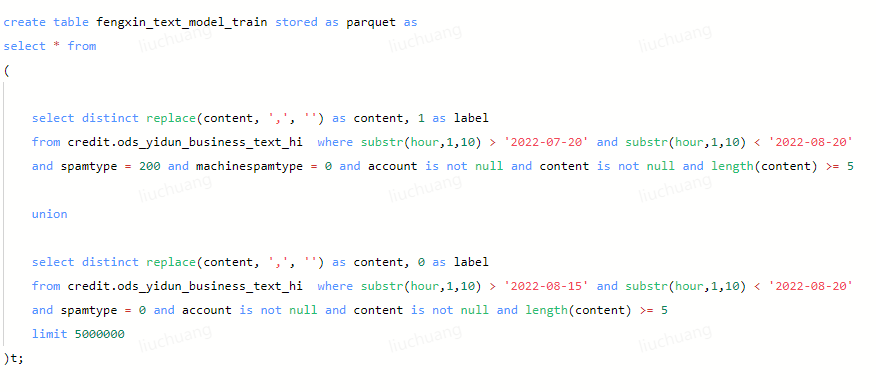
1、如图可以发现,两段其实都是两个子查询一起union,区别是一个直接union,另一个用select包住,理论上来说逻辑是不会变的。
使用spark测试两种方式,查看sparkui。拿select包住的,可以看出。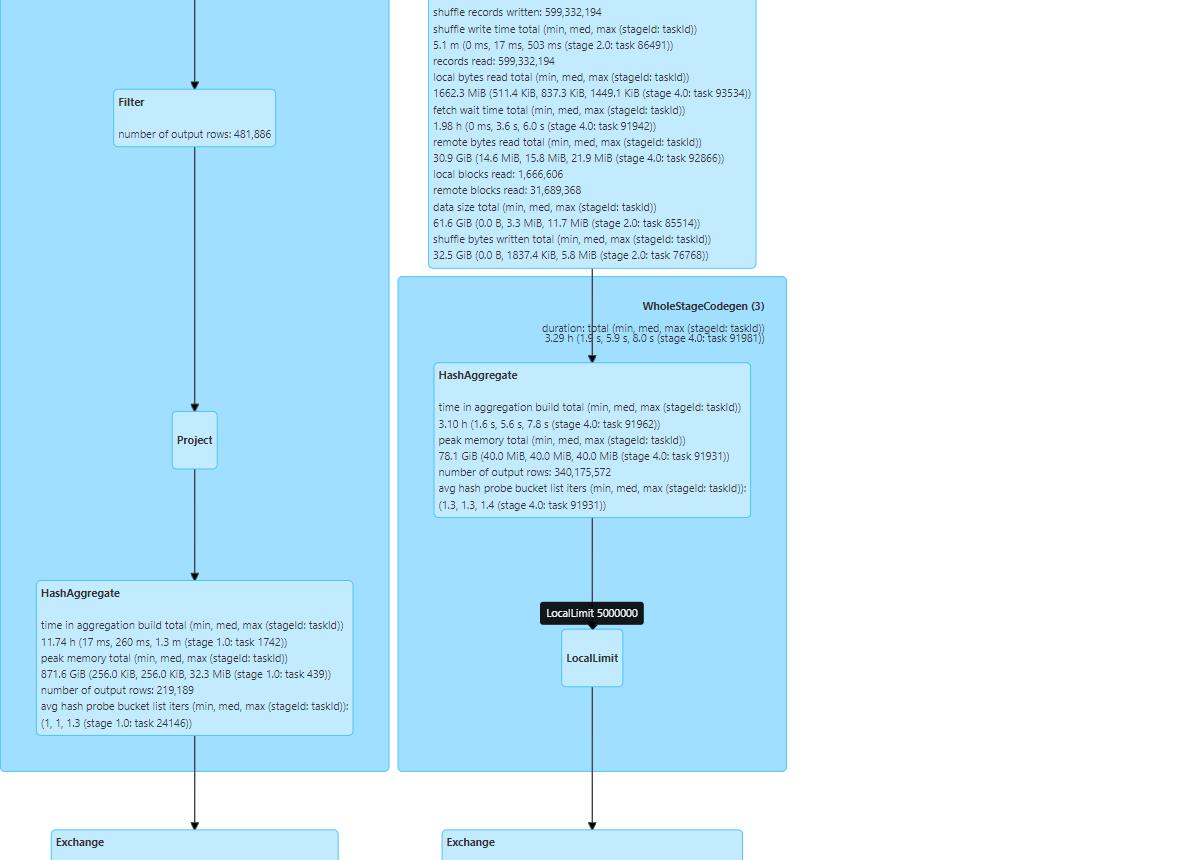
limit在第二个子查询中。union前没有包住的,可以看到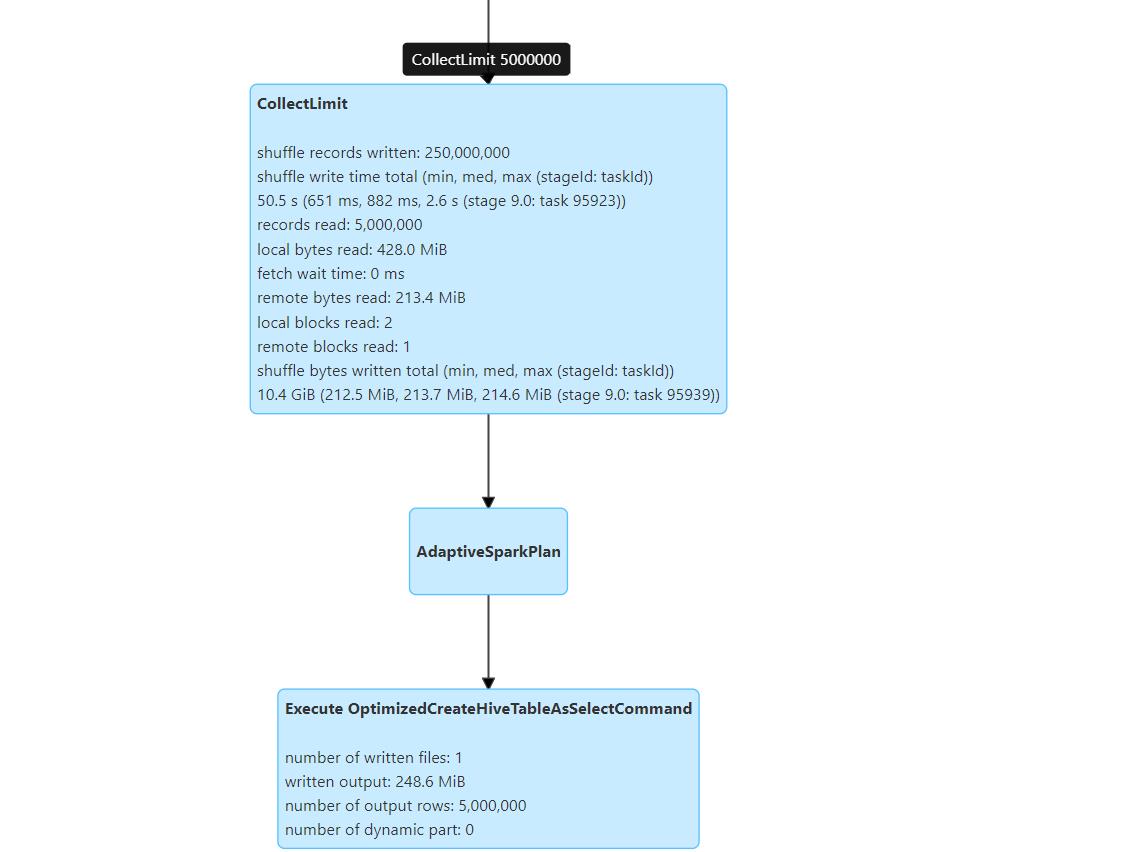
limit在插入表之前,union后,截至这里得出结论。两次limit的位置不一样,一种是union后整体limit,一种是先对第二个子查询limit后再union,导致结果不同,问题明确。用户的sql写法需要改正。
作者:林帅