高级功能
公共流表
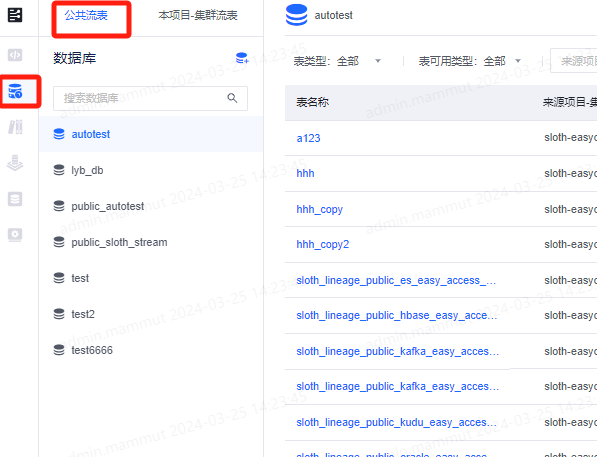
直接进入表管理-公共流表tab创建流表库和流表即可,其余与正常流表一致,但是公开范围在项目组范围内。
| 注意:如选择指定项目-集群公开,当前所在的项目-集群必须在指定公开范围内,否则流表将无法再次编辑。 |

- 功能使用注意事项:
- 公共流表使用时需按三元组方式使用。
- 公共流表的使用权限通过数据源使用权限控制,即如需使用已公开的公共流表,则该项目需具备该流表实际对应的数据源的使用权限。
- 公共流表的编辑权限归属于创建流表时所在的项目-集群的项目负责人、管理员、实时管理员、实时开发、实时运维。其他项目-集群即使在流表公开范围内也无法对流表进行编辑、删除操作。
从数据库获取方式说明
为了提升填写字段效率,针对mysql、oracle、es、habse、kudo等数据源支持直接从数据源字段信息,并自动映射成flink字段。此方式需用户选择流表对应的物理表的源、库、表等信息后方可使用,点击此功能按钮后,平台将连接数据源获取对应表的元数据信息(包含字段名称、字段类型、是否为主键),并填充至流表字段信息列表中。获取到的字段类型与流表字段类型的映射关系详见各数据源类型流表介绍页面。
1、选择对应的数据源库表信息。
2、点击从数据库中获取。
数据解析说明
针对kafka数据源并且序列化方式是json的数据,数据解析从kafka消费数据。
消费支持指定group-id和随机group-id消费。
对于解析到的json数据可以点击解析可直接将json中的字段直接解析出来到flink字段信息。
注:用户可将json数据复制编辑后解析。
仅支持自动解析序列化方式为 json、canal-json、debezium-json、maxwell-json、ogg-json 的数据,具体说明规则如下:
canal-json 和 maxwell-json 数据仅解析 data 字段中的内容。
{ "data":[ { "id":22, "name":"opt", "age":123, "address":"北京市" } ], "type":"INSERT" }以上样例数据, 解析结果为4个字段
id、name、age、address,data、type字段不展示。debezium-json 数据根据 op 字段不同解析不同字段中的内容。
op 字段为“c” 时,解析 after 字段中的内容,如样例数据:
{ "before":null, "after":{ "id":22, "name":"opt1", "age":null }, "op":"c" }解析结果为3个字段
id、name、age,before、after、op字段均不展示。op 字段为“d”时,解析 before 字段中的内容,如样例数据:
{ "before":{ "id":22, "name":"opt1", "age":null }, "after":null, "op":"d" }解析结果为3个字段
id、name、age,before、after、op字段均不展示。op 字段为“u”时,解析 after 字段中的内容,如样例数据:
{ "before":{ "id":22, "name":"opt1", "age":null }, "after":{ "id":22, "name":"opt1", "age":11 }, "op":"u" "ts_ms": 1589362330904, "transaction": null }解析结果为3个字段
id、name、age,before、after、op、ts_ms、transaction字段均不展示。
ogg-json 数据根据 op_type 字段不同解析不同字段中的内容。
op_type 字段为“I”时,解析 after 字段中的内容,如样例数据:
{ "after":{ "id": 111, "name": "op1", "weight": 5.15 }, "op_type": "I" }解析结果为3个字段
id、name、weight,after、op_type字段均不展示。op_type 字段为“D”时,解析 before 字段中的内容,如样例数据:
{ "before":{ "id": 111, "name": "op1", "weight": 5.18 }, "op_type": "D" }解析结果为3个字段
id、name、weight,before、op_type字段均不展示。op_type 字段为“U”时,解析 after 字段中的内容,如样例数据:
{ "before":{ "id": 111, "name": "op1", "weight": 5.18 }, "after":{ "id": 111, "name": "op1", "weight": 5.15 }, "op_type": "U" }
解析结果为3个字段 id、name、weight,before、after、op_type 字段均不展示。
数据解析时字段的映射规则如下:
| 原字段类型 | 解析后的字段类型 |
|---|---|
| string | string |
| int、bigint、tinyint、smallint | bigint |
| float、double、decimal | decimal(默认精度标度为(10, 0)) |
| boolean | boolean |
| row、map | row |
| array | array |
| time、timestamp、date、byte、varbinary 无法解析 | 统一定义成string |
DDL解析说明
在创建流表时,支持用户输入 Flink Table 的 DDL 语句,平台通过语句解析获取字段和配置信息,来快速创建流表。 在流表登记的表单中已包含 DDL 中的部分参数,且部分特别参数如 group id 不适合在流表登记时统一配置,故下列参数在 DDL 解析时不会被解析到配置列表中,如需登记请手动配置。
| DDL解析忽略的配置项 | 含义 |
|---|---|
| connector | Flink 所连接的外部系统的类型。 |
| properties.bootstrap.servers | Kafka 消费者/生产者的启动服务器列表。 |
| properties.group.id | Kafka 消费者群组的唯一标识符。 |
| topic | Kafka 消息队列的主题名称。 |
| format | 外部系统的数据格式。 |
| name.server.address | 消息队列服务器的地址。 |
| group | 消费者群组的唯一标识符。 |
| service-url | 服务 URL。 |
| admin-url | 管理 URL。 |
| url | Flink 所连接的外部系统的 URL。 |
| table-name | 数据库中的表名。 |
| username | 连接外部系统时使用的用户名。 |
| password | 连接外部系统时使用的密码。 |
| hosts | 集群中节点的主机名或 IP 地址列表。 |
| index | Elasticsearch 中的索引名称。 |
| zookeeper.quorum | HBase 集群的 ZooKeeper 地址。 |
| zookeeper.znode.parent | HBase 在 ZooKeeper 中的父节点路径。 |
| masters | 集群的主节点列表。 |
| primary.keys | 表的主键。 |
流表支持的字段类型
| 字段类型 | 备注 |
|---|---|
| string | - |
| int | - |
| bigint | - |
| tinyint | - |
| smallint | - |
| float | - |
| double | - |
| decimal | 支持配置精度和标度,默认值为(10,0) |
| boolean | - |
| row | 部分数据源类型流表不支持此字段类型,详见各数据源类型流表说明 |
| map | value不支持row、map、array、varbinary 部分数据源类型流表不支持此字段类型,详见各数据源类型流表说明 |
| array | 部分数据源类型流表不支持此字段类型,详见各数据源类型流表说明 |
| time | 默认精度为(0),由于社区实现问题,暂不支持变更 |
| timestamp | 支持配置精度,默认值为(3) |
| date | - |
| varbinary | 部分数据源类型流表不支持此字段类型,详见各数据源类型流表说明 |
| metadata | 支持输入metadata字段配置 仅 Kafka 数据源类型流表支持配置此字段 |
| 计算列 | 支持输入计算列配置 |
注:
1)数据源连接信息和库表信息以页面表单选择为准,DDL 中相关内容不做解析。
2)点击解析按钮后字段信息列表和watermark内容将被更新,若 DDL 中包含配置信息,则配置信息也将被更新。
3)不同数据源类型或序列化方式可支持的字段类型不同,解析时不支持的类型将被清空。具体支持类型请参考用户手册。
复制流表时订阅源端表变更
支持用户复制流表时选择订阅源端表变更,当被复制的流表字段信息或配置信息有更新时,在订阅变更的表的详情页有更新提示。
- 功能使用注意事项:
- 仅可在通过复制按钮进入新建流表流程时订阅源端表变更,直接新建流表无此功能。
- 用户复制流表时如未订阅变更或后续取消订阅,不可重新恢复订阅。
- 功能详细使用步骤:
- 订阅变更:在流表管理列表中找到需要复制的流表,点击复制按钮进入新建流表页面,在页面底部勾选订阅源端表变更。
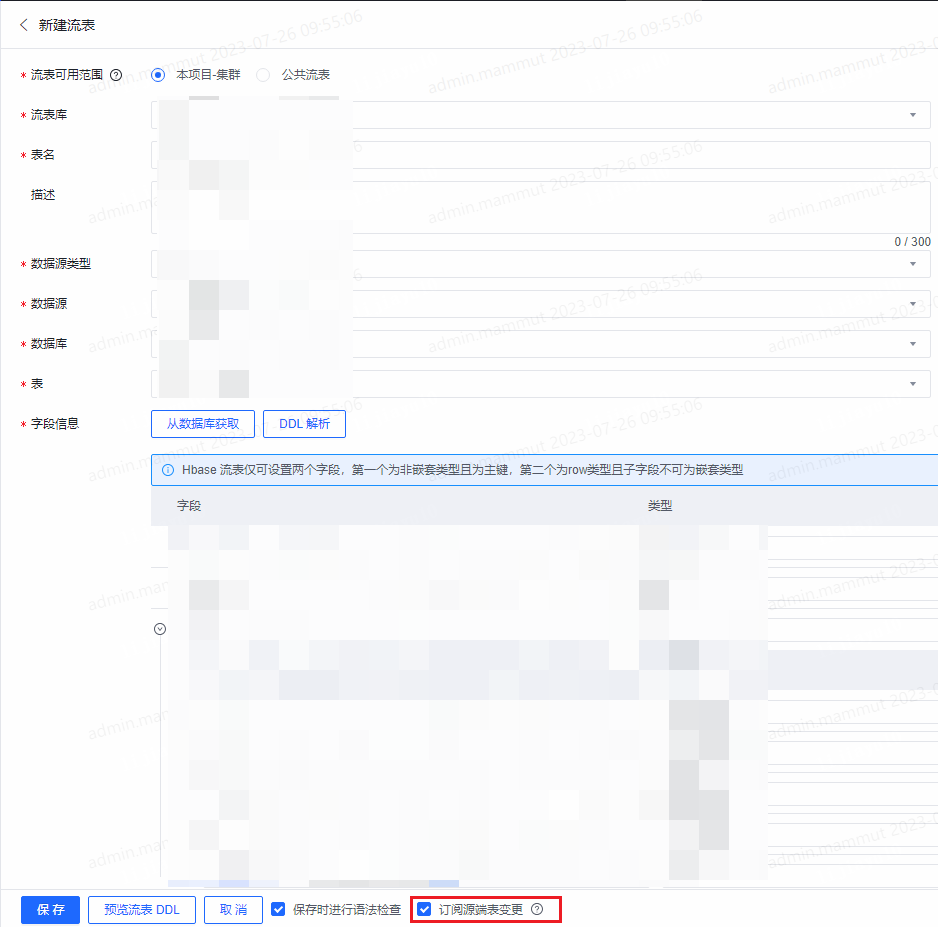
- 查看变更:在复制后的流表详情页里,复制源端表字段将在源端表有变更时展示有更新icon。
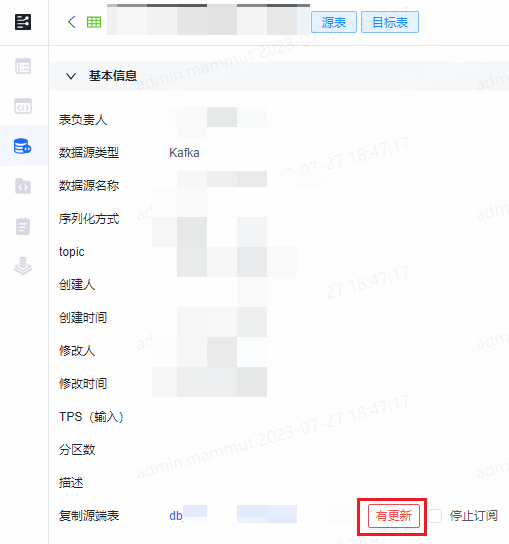
- 接收变更:点击有更新icon,选择接收更新,进入流表编辑页面查看变更后的字段信息和配置信息,可基于变更后的内容修改后保存。保存后有更新提示消失。
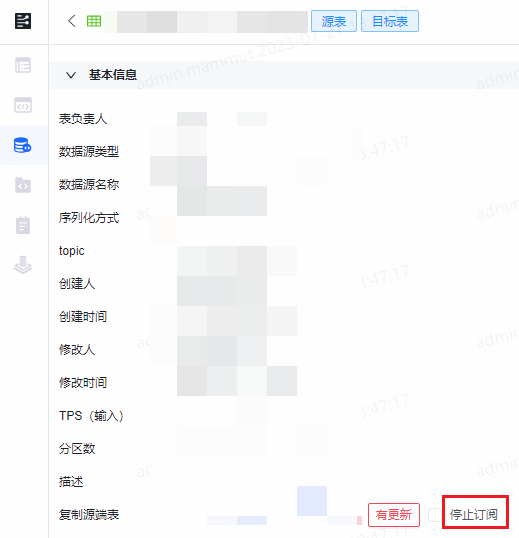
- 取消订阅:在复制流表时可以选择取消订阅源端表变更的勾选。已订阅变更的在对应流表详情页面,复制源端表字段旁可取消订阅。
- 订阅变更:在流表管理列表中找到需要复制的流表,点击复制按钮进入新建流表页面,在页面底部勾选订阅源端表变更。
预览ddl
支持将填写好的流表信息,逆向生成create-table DDL语句
自动下拉获取topic
针对消息队列的数据源类型支持topic从数据源中获取,同时可以直接用户自己输入。
流表支持
目前,实时计算平台支持将Kafka、Pulsar、RocketMQ、MySQL、Oracle、HBASE、ElasticSearch、Kudu、 Iceberg、StarRocks、Hive、Paimon12种数据源类型登记为流表。
数据源具体使用及配置项使用说明请参阅SQL开发文档 。