实时数据写入Hive表
Flink SQL 写 Hive 表实践
作业运行于flink1.12引擎
| 由于有数开发平台集成了kerberos 做集群的安全认证,在数据写出到hive 的过程中,需要为任务配置相应的keytab 并配置用户权限,保证其有权限对数据目录及表进行操作。 目前hadoop 官方并不支持多用户认证(参考说明:https://issues.apache.org/jira/browse/HADOOP-16122?focusedCommentId=16772628&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-16772628) 所以作业使用的keytab 需要和平台使用的保持一致。如若使用的不是同一个keytab,作业在运行一段时间后会触发failover,但数据不受影响。 |
keytab 配置说明
步骤一 对sloth 产品账号授予 Hive 目标表或者目标库的相应权限
此操作需要项目管理员账号,一般由管理员授权,可咨询平台管理员。在安全中心-> 数据授权找到需要授权的数据库或者数据表,单击新增授权,选择sloth 产品账号用户即可, 如下图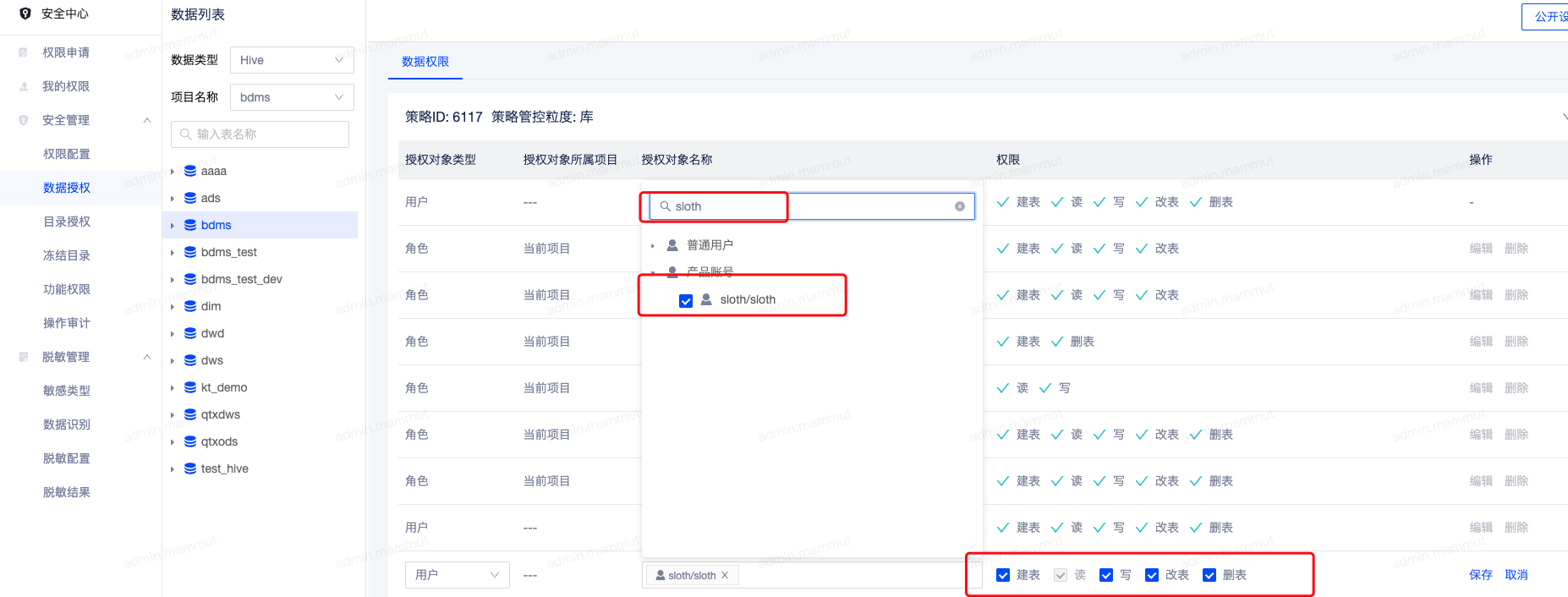
步骤二 上传平台keytab到实时开发对应项目的资源目录下
登录sloth server 部署所在服务器,在/etc/security/ketabs/sloth/ 目录下找到sloth.keytab 下载到本地,再上传到开发平台资源管理目录下,在任务中通过文件依赖引用即可。此操作可咨询平台管理员获取,或在已有的项目内获取即可
上传位置: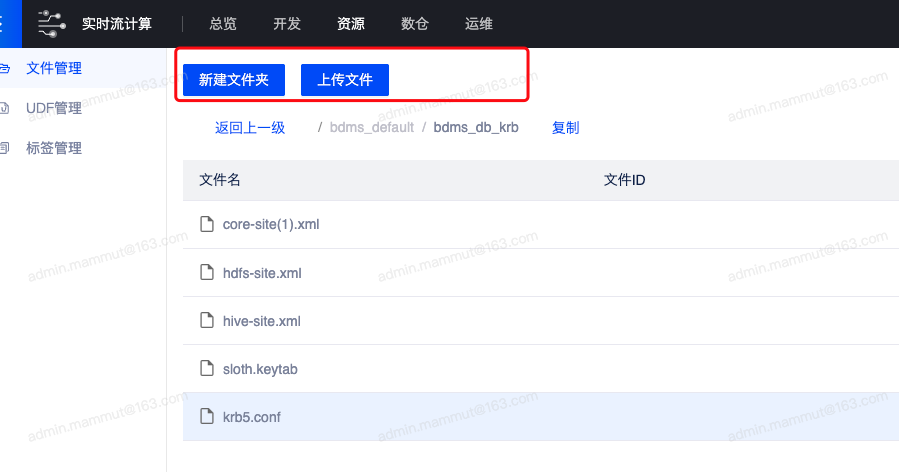
任务依赖配置: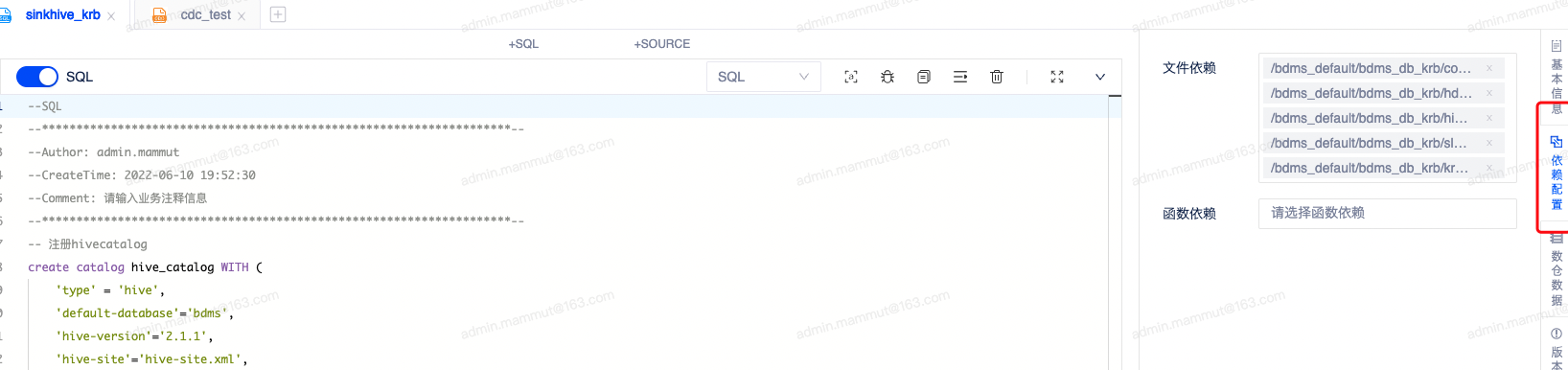
步骤三 创建Hive catalog 参考如下配置
create catalog hive_catalog WITH (
'type' = 'hive',
'default-database'='bdms',
'hive-version'='2.1.1',
'hive-site'='hive-site.xml',
'hdfs-site'='hdfs-site.xml',
'core-site'='core-site.xml',
'krb.keytab'='sloth.keytab',
'krb.conf'='krb5.conf',
'krb.principal'='sloth/dev@BDMS.163.COM',
'auth.method'='using_env_kerberos' -- 使用同一个keytab 配置该参数
);详细配置可参考hive connector
需要注意的是,除keytab 外,作业还需要上传hive 相应的配置文件hive-site.xml、hdfs-site.xml、core-site.xml、以及krb5.conf ,这些配置文件可以找平台管理员获取,并在平台上传后,在作业的依赖管理处进行引用
案例
sql 语句如下:
--SQL
--********************************************************************--
--Author: 苏文文
--CreateTime: 2021-12-16 11:47:08
--Comment: 请输入业务注释信息
--********************************************************************--
-- 注册hivecatalog
create catalog hive_catalog WITH (
'type' = 'hive',
'default-database'='sloth',
'hive-version'='2.1.1',
'hive-site'='hive-site.xml',
'hdfs-site'='hdfs-site.xml',
'core-site'='core-site.xml',
'warehouse'='hdfs://bdms-test/user/sloth/hive_db',
'krb.keytab'='sloth.keytab',
'krb.conf'='krb5.conf',
'krb.principal'='sloth/ALL@BDMS.163.COM',
'auth.method'='using_env_kerberos',
'sys.db.url'='',
'sys.db.user'='',
'sys.db.password'=''
);
--切换hive 语法,构建hive 表
SET 'table.sql-dialect'='hive';
CREATE TABLE if not exists hive_catalog.sloth.orders (
order_id int,
order_date string,
customer_name string,
price decimal(10,3),
product_id int,
order_status boolean
) PARTITIONED BY (dt STRING)
stored as parquet;
--切换回flink sql 语法
SET 'table.sql-dialect'='default';
--创建数据源表
create table source_kafka(
order_id int,
order_date varchar,
customer_name varchar,
price decimal(10,3),
product_id int,
order_status boolean
)with(
'connector' = 'kafka',
'topic' = 'topn_char1',
'properties.bootstrap.servers' = 'ip:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
--使用datagen 构建源表数据
create table datagen_source
with( 'connector' = 'datagen') like source_kafka(EXCLUDING OPTIONS);
--插入数据至hive 表
insert into hive_catalog.sloth.orders
/*+ OPTIONS(
'sink.partition-commit.trigger'='process-time',
'sink.partition-commit.policy.kind'='metastore,success-file',
'sink.rolling-policy.file-size'='128MB',
'sink.rolling-policy.rollover-interval'='3min',
'sink.rolling-policy.check-interval'='1min',
'auto-compaction'='true',
'compaction.file-size'='128MB'
) */
select * , date_format(now(),'yyyy-MM-dd') as dt from datagen_source;数据查询
作业hints 参数说明
分区上报策略
'sink.partition-commit.trigger'='process-time',
分区提交触发器,单选,可选值为partition-time、process-time(默认), 其中==partition-time需要根据当前数据的watermark来判断分区是否需要提交,当watermark + delay大于等于分区上的时间时就会提交该分区元数据==;process-time的话根据当前系统处理时间来判断分区是否需要提交,当系统处理时间大于等于分区上的时间就会提交该分区元数据
'sink.partition-commit.delay'='10 min', 使用process-time, 该参数不生效
表示watermark允许event time的最大乱序时间,使用partition-time触发器时可以使用,默认为0s
'sink.partition-commit.policy.kind'='metastore,success-file'
分区提交方式,多选,可选值为metastore、success-file、custom,metastore表示写入元数据库,success-file表示往hdfs分区目录写入一个标志文件,custom表示使用自定义提交方式,通常使用metastore,success-file组合
文件滚动策略
如果未设置文件滚动的策略,则文件根据checkpoint 时间间隔 + 文件大小128M 策略进行控制
如果设置了文件滚动策略,则根据设置的滚动时间间隔 + 设置的文件大小 策略进行控制
'sink.rolling-policy.file-size' = '128MB', 滚动前文件大小达128mb 生成下一个文件
'sink.rolling-policy.rollover-interval' = '30min', 30分钟滚动生成下一个文件
'sink.rolling-policy.check-interval' = '1min' ,每1分钟做一次检查,看策略是否满足新文件生成
文件合并
在hdfs 系统时不可避免可能生成小文件,flink 提供了合并文件参数,支持对文件进行合并写出
'auto-compaction' = 'true', 开启合并文件
'compaction.file-size'='128MB' 合并目标文件的大小,默认值为文件滚动策略设置的文件大小,由于文件合并策略,可能会生成比目标文件更大的文件。
文件合并时针对单个checkpoint 时间间隔之间产生的文件进行合并,至少会产生和checkpoint数量相同的文件,不建议将checkpoint 时间设置过短
如果业务允许,可以设置30分钟,设置过短,可能无法达到文件合并的目的;需要注意的是,文件合并完成之前,文件是不可见的
如果合并文件的时间周期过长,会对作业产生反压
在文件合并的过程中,作业需要清除以前产生的旧临时文件,启动作业的用户或者请求hdfs的用户需要对hdfs 的表目录有删除权限
性能提升
set 'table.exec.hive.fallback-mapred-write'='false';
默认为true,使用hadoop mapred record 去写parquet 和orc 文件
改为false 使用flink 的writer 去写parquet 和orc 文件,能显著提升性能
Sink 并行度
flink 1.13版本及以后,支持通过table 选项指定写文件的并行度,默认情况下,该并行度和上一个上游的算子的并行度一样,当配置和上一个算子的并行度不同是,会使用指定的并行度。
set 'sink.parallelism' ='3' 该参数设置必须大于0,否则会抛出异常