Hive
离线同步任务支持Hive数据源,支持该数据源的抽取(Reader)和导入(Writer),当前支持的版本为:EasyData hive 2.1 - hadoop 2.9.2、神策Hadoop2.6.0 - CDH5.12.1(只支持Reader)、星环TDH5.2.2(只支持Reader)、Sensors Data-Impala 3.2.18.6(只支持Reader)、1.1.0-CDH5.14.0(支持Reader和Writer)。
当前平台支持Hive2Hive跨集群传输场景,即当用户存在物理隔离、网络互通的数开生产集群和数开测试集群时,可通过Hive2Hive功能实现跨集群的Hive数据传输。在使用过程中,需要注意如下情况:
- Hive作为数据来源端时,支持选择本集群下的Hive数据源、版本为神策Hadoop2.6.0 - CDH5.12.1、星环TDH5.2.2、Sensors Data-Impala 3.2.18.6、1.1.0-CDH5.14.0的Hive数据源。
- Hive作为数据去向端时,支持选择本集群下的Hive数据源、版本为EasyData hive 2.1 - hadoop 2.9.2的Hive数据源、1.1.0-CDH5.14.0的Hive数据源。
|
说明:当前支持Hive2Hive的spark版本为2.3.2。当数据来源选择的Hive数据源为Sensors Data-Impala 3.2.18.6时,读取方式支持基于Impala JDBC读取Hive数据。 |
使用前提
在使用之前需要在项目中心(新)完成Hive数据源的登记并测试通过。
Hive各版本配置的内容稍有不同,下面分开介绍。
EasyData hive 2.1 - hadoop 2.9.2版本Hive数据源登记过程中,需要填写如下信息:
- 数据源名称:Hive数据源的名称
- 数据源标识:仅允许包含英文小写、数字、下划线,只允许英文小写开头,最大长度为64个字符。平台内唯一,保存数据源后数据标识不可修改
- 归属项目:由于元数据中心是项目组级别,因此此处支持选择项目组下的项目,默认为当前项目名称
- 负责人:默认为当前创建人员
- 管理员:同负责人,有该数据源的管理权限,包括编辑、设置“源系统账号映射”。可在安全中心为自己或其他人设置该数据源的使用权限
- 版本:此处选择EasyData hive 2.1 - hadoop 2.9.2
- 连接方式:基于HiveMetaStore连接数据
- 数据源连接:根据jdbc:hive2://host:port/database 格式进行填写
- 认证方式:支持用户密码认证、Simple认证和Kerberos认证三种认证方式
- 选择用户密码认证则需要填写用户名和密码:
- 用户名:填写访问数据源的用户名
- 密码:填写用户名所对应的密码
- 选择Simple认证则只需要填写用户名:
- 用户名:选填,填写访问数据源的用户名
- 选择Kerberos认证则需要上传keytab、krb5.conf文件以及填写Principal:
- keytab:上传.keytab文件
- krb5.conf:上传.conf文件
- Principal:填写Kerberos主体
- 选择用户密码认证则需要填写用户名和密码:
扩展参数:Hive扩展参数配置,比如namenode的principal、配置高可用参数等,根据实际情况进行配置,示例如下:
{"fs.defaultFS":"hdfs://bdms-test","hadoop.security.authentication":"kerberos","hadoop.security.authorization":true,"dfs.nameservices":"bdms-test","dfs.namenode.rpc-address.bdms-test.nn1":"hzadg-bdms-3.server.163.org:8020","dfs.namenode.rpc-address.bdms-test.nn2":"hzadg-bdms-4.server.163.org:8020","dfs.namenode.rpc-address.bdms-test.nn3":"hzadg-bdms-5.server.163.org:8020","dfs.namenode.rpc-address.bdms-test.nn4":"hzadg-bdms-6.server.163.org:8020","dfs.ha.namenodes.bdms-test":"nn1,nn2,nn3,nn4","dfs.namenode.kerberos.principal":"nn/_HOST@BDMS.163.COM","dfs.client.failover.proxy.provider.bdms-test":"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"}metastoreUris:根据thrift://ip1:port1,thrift://ip2:port2 格式进行填写
- defaultFS:根据hdfs://ip:port 格式进行填写
- metastoreDB连接:根据jdbc:mysql://ServerIP:Port/Database 格式进行填写
- DB连接用户名:存储Hive metastore的数据库用户名,当前默认该数据库类型为MySQL,此处为连接MySQL的用户名
- DB连接密码:连接MySQL的用户名所对应的密码
- 自定义属性:支持添加数据源的其它配置
神策Hadoop2.6.0 - CDH5.12.1、星环TDH5.2.2版本Hive数据源登记过程中,需要填写如下信息:
- 数据源名称:Hive数据源的名称
- 数据源标识:仅允许包含英文小写、数字、下划线,只允许英文小写开头,最大长度为64个字符。平台内唯一,保存数据源后数据标识不可修改
- 归属项目:由于元数据中心是项目组级别,因此此处支持选择项目组下的项目,默认为当前项目名称
- 负责人:默认为当前创建人员
- 管理员:同负责人,有该数据源的管理权限,包括编辑、设置“源系统账号映射”。可在安全中心为自己或其他人设置该数据源的使用权限
- 版本:此处选择Sensors Data-Hadoop2.6.0 - CDH5.12.1或TDH5.2.2
- 连接方式:基于HiveServer2连接数据
- 数据源连接:根据jdbc:hive2://host:port/database 格式进行填写
- defaultFS:根据hdfs://ip:port 格式进行填写
- 认证方式:支持用户密码认证、Simple认证和Kerberos认证三种认证方式
- 选择用户密码认证则需要填写用户名和密码:
- 用户名:填写访问数据源的用户名
- 密码:填写用户名所对应的密码
- 选择Simple认证则只需要填写用户名:
- 用户名:选填,填写访问数据源的用户名
- 选择Kerberos认证则需要上传keytab、krb5.conf文件以及填写Principal:
- keytab:上传.keytab文件
- krb5.conf:上传.conf文件
- Principal:填写Kerberos主体
- 选择用户密码认证则需要填写用户名和密码:
- 自定义属性:支持添加数据源的其它配置
Sensors Data-Impala 3.2.18.6版本Hive数据源登记过程中,需要填写如下信息:
- 数据源名称:Hive数据源的名称
- 数据源标识:仅允许包含英文小写、数字、下划线,只允许英文小写开头,最大长度为64个字符。平台内唯一,保存数据源后数据标识不可修改
- 归属项目:由于元数据中心是项目组级别,因此此处支持选择项目组下的项目,默认为当前项目名称
- 负责人:默认为当前创建人员
- 管理员:同负责人,有该数据源的管理权限,包括编辑、设置“源系统账号映射”。可在安全中心为自己或其他人设置该数据源的使用权限
- 版本:此处选择Sensors Data-Impala 3.2.18.6
- 连接方式:基于Impala JBDC连接数据
- 数据源连接:根据jdbc:hive2://host:port/database 格式进行填写
- 认证方式:当前Sensors Data-Impala 3.2.18.6只支持Simple认证,填写访问数据源的用户名即可
- 自定义属性:支持添加数据源的其它配置
1.1.0-CDH5.14.0版本Hive数据源登记过程中,需要填写如下信息:
- 数据源名称:Hive数据源的名称
- 数据源标识:仅允许包含英文小写、数字、下划线,只允许英文小写开头,最大长度为64个字符。平台内唯一,保存数据源后数据标识不可修改
- 归属项目:由于元数据中心是项目组级别,因此此处支持选择项目组下的项目,默认为当前项目名称
- 负责人:默认为当前创建人员
- 管理员:同负责人,有该数据源的管理权限,包括编辑、设置“源系统账号映射”。可在安全中心为自己或其他人设置该数据源的使用权限
- 版本:此处选择1.1.0-CDH5.14.0
- 连接方式:基于HiveServer2连接数据
- 数据源连接:根据jdbc:hive2://host:port/database 格式进行填写
- 传输协议:支持HDFS协议、WebHDFS协议
- defaultFS:根据hdfs://ip:port 格式进行填写
- 扩展参数:Hive扩展参数配置,例如高可用配置参数,高可用配置参数格式可参考模板,模版可在产品页面上查看
- 认证方式:支持用户密码认证、Simple认证和Kerberos认证三种认证方式
- 选择用户密码认证则需要填写用户名和密码:
- 用户名:填写访问数据源的用户名
- 密码:填写用户名所对应的密码
- 选择Simple认证则只需要填写用户名:
- 用户名:选填,填写访问数据源的用户名
- 选择Kerberos认证则需要上传keytab、krb5.conf文件以及填写Principal:
- keytab:上传.keytab文件
- krb5.conf:上传.conf文件
- Principal:填写Kerberos主体
- 选择用户密码认证则需要填写用户名和密码:
- 用户名:存储Hive metastore的数据库用户名,当前默认该数据库类型为MySQL,此处为连接MySQL的用户名
- 密码:连接MySQL的用户名所对应的密码
- 自定义属性:支持添加数据源的其它配置
|
唯一性校验规则: 1)若版本为EasyData hive 2.1 - hadoop 2.9.2,则以metastoreDB连接作为唯一性校验; 2)若为其余版本,则以metastoreDB连接作为唯一性校验。 |
数据源配置完成后,需点击测试连接按钮进行测试,测试通过后才可使用。
除了数据源需要准备之外,进行离线同步任务创建和数据源的使用都需要在安全中心-功能权限中添加相应的权限(可参考数据传输权限、元数据中心权限)。
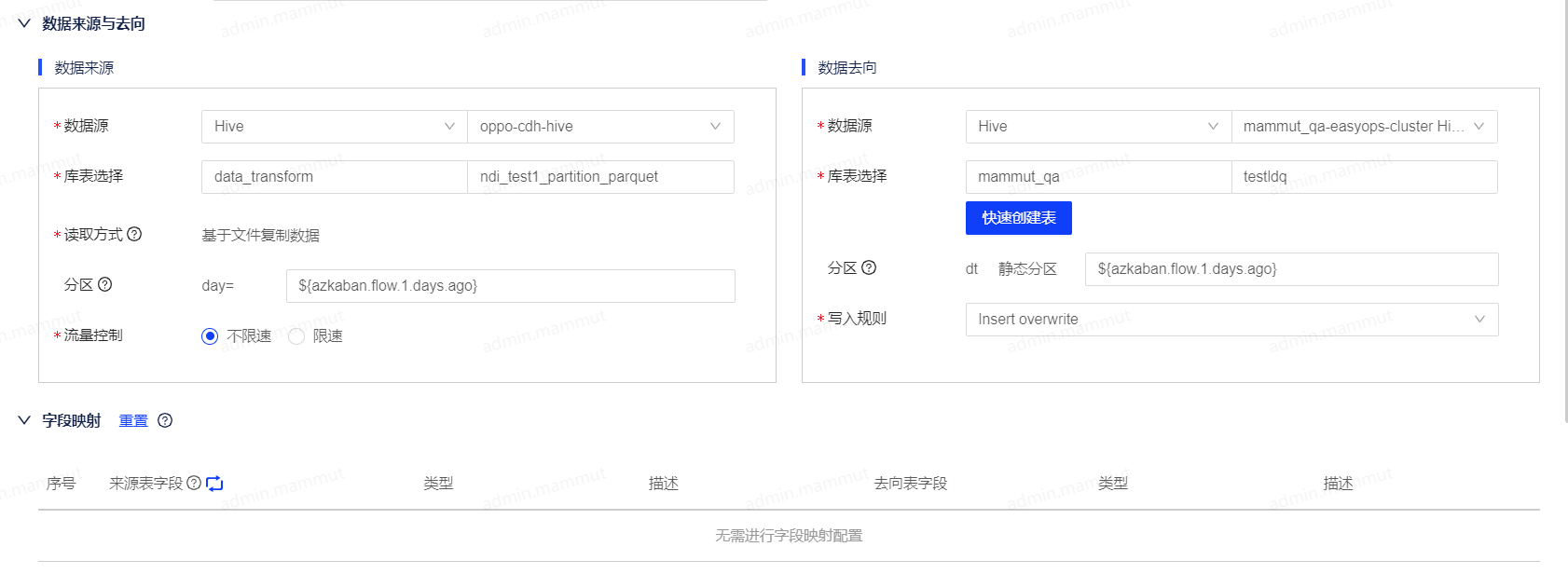
Hive作为数据来源&数据去向
以Hive2Hive场景为例,在数据来源端选择本地Hive或者版本为神策Hadoop2.6.0 - CDH5.12.1、星环TDH5.2.2的Hive数据源,并选择需要进行读取的schema和表。
- 过滤条件支持填写where过滤语句(不含where关键字),通常用作增量同步,支持系统参数和参数组参数。特殊字符替换根据实际情况进行填写。
在数据去向端选择本地Hive或者版本为EasyData hive 2.1 - hadoop 2.9.2的Hive数据源,并选择需要导入的schema和表。
- 写入规则:支持INSERT INTO和INSERT OVERWRITE两种。
- INSERT INTO:增加数据。
- INSERT OVERWRITE:先删除原有数据再新增数据。

当数据源选择版本为1.1.0-CDH5.14.0的Hive数据源时,默认读取方式为基于文件复制数据。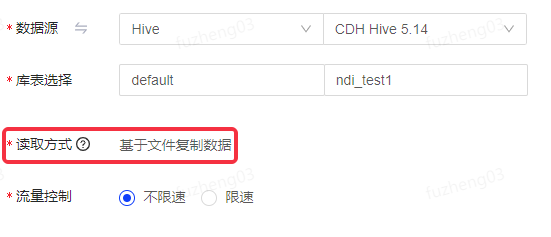
关于读取方式:
- 基于Hive JDBC读取数据、基于Spark读取数据和基于Impala JDBC读取数据支持数据过滤,配置字段映射和数据脱敏等策略。
- 基于文件复制数据不支持数据过滤,仅能读取全表或表的整个分区数据,不支持配置字段映射和数据脱敏等策略。
- 如果读取方式为基于文件复制数据时,数据来源端和去向端的Hive表表结构须保持一致,且读取和写入的Hive分区级别须相等。
如果选中的Hive表为非分区表,则不展示分区配置项,默认读取全表;如果选中的Hive表为分区表,填写说明如下:
- 若分区值为空,则读取整表;若填写分区值,则读取指定分区的数据。
- 支持填写参数组参数和Azkaban参数。