Oracle
更新时间: 2025-05-20 15:47:20
离线同步任务支持Oracle,支持该数据源的抽取(Reader)和导入(Writer),当前支持的版本为:11g、12c、19c。
使用前提
在使用之前需要在项目中心(新)完成MySQL数据源的登记并测试通过。
数据源登记过程中,需要填写如下信息:
- 源系统账号鉴权:源系统账号鉴权开关,仅在首次登记数据源时可配置生效,保存后不可修改。对于开启的数据源,保存后会自动进入该数据源的详情页。在数据源的详情页可以编辑该数据源,添加本平台账号和源系统账号的映射关系(可参考源系统账号映射)
- 数据源名称:Oracle数据源的名称
- 数据源标识:仅允许包含英文小写、数字、下划线,只允许英文小写开头,最大长度为64个字符。平台内唯一,保存数据源后数据标识不可修改
- 归属项目:由于元数据中心是项目组级别,因此此处支持选择项目组下的项目,默认为当前项目名称
- 负责人:默认为当前创建人员
- 协助管理员:同负责人,有该数据源的管理权限,包括编辑、设置“源系统账号映射”。可在安全中心为自己或其他人设置该数据源的使用权限
- 版本:支持选择“>= 11g”、“11g”、“12g”、“19c”。需要注意的是数据源管理中登记的版本并不代表数据传输支持的版本,数据传输使用时请根据支持的版本进行选择
- 数据源连接:根据jdbc:oracle:thin:@ServerIP:Port:SID或jdbc:oracle:thin:@//ServerIP:Port/service_name格式进行填写
- 用户名:填写访问数据源的用户名
- 密码:填写用户名所对应的密码
- 自定义属性:支持添加数据源的其它配置
|
唯一性校验规则: 1)如果未开启源系统账号鉴权,则基于数据源连接+用户名+schema进行校验; 2)如果开启源系统账号鉴权,则基于数据源连接进行校验。 |
数据源配置完成后,需点击测试连接按钮进行测试,测试通过后才可使用。
除了数据源需要准备之外,进行离线同步任务创建和数据源的使用都需要在安全中心-功能权限中添加相应的权限(可参考数据传输权限、元数据中心权限)。
Oracle作为数据来源
以Oracle to Hive为例,在数据来源端选择Oracle数据源类型及数据源名称,选择需要进行读取的schema和表。
Oracle数据源支持库表选择、正则匹配和同义词。
- 库表选择:支持搜索或直接选择数据库表。支持跨库表配置,跨库表必须是相同数据源类型。
- 正则匹配:支持通过正则表达式来匹配数据表。
- 同义词:支持通过同义词读取同义词对应的表。
Oracle数据源支持全量初始化:
- 全量初始化开关开启时,任务提交上线后首次调度时会忽略数据过滤条件,进行全量同步。
- 全量初始化开关开启时,如果任务重新提交上线,则重新提交上线后的首次调度仍会进行全量同步。
- 如果多个数据同步节点引用同一离线同步任务,则每个节点提交上线后的首次调度执行全量初始化操作。
数据过滤支持条件、流水型及自定义。
- 条件型:按列设置过滤规则,可添加一或多组条件,条件默认为AND关系。
- 流水型:从选择字段的起始值开始读取数据,读取到最新记录位置,下次从上次的最新记录读取至当前的最新记录。流水型数据过滤方式生效满足以下条件:1. 选取的字段是单调递增的;2. 离线开发任务提交到线上调度执行。
- 自定义:填写where过滤语句(不含where关键字),通常用作增量同步,支持系统参数和参数组参数。
特殊字符替换、并发读取、流量控制根据实际情况进行填写。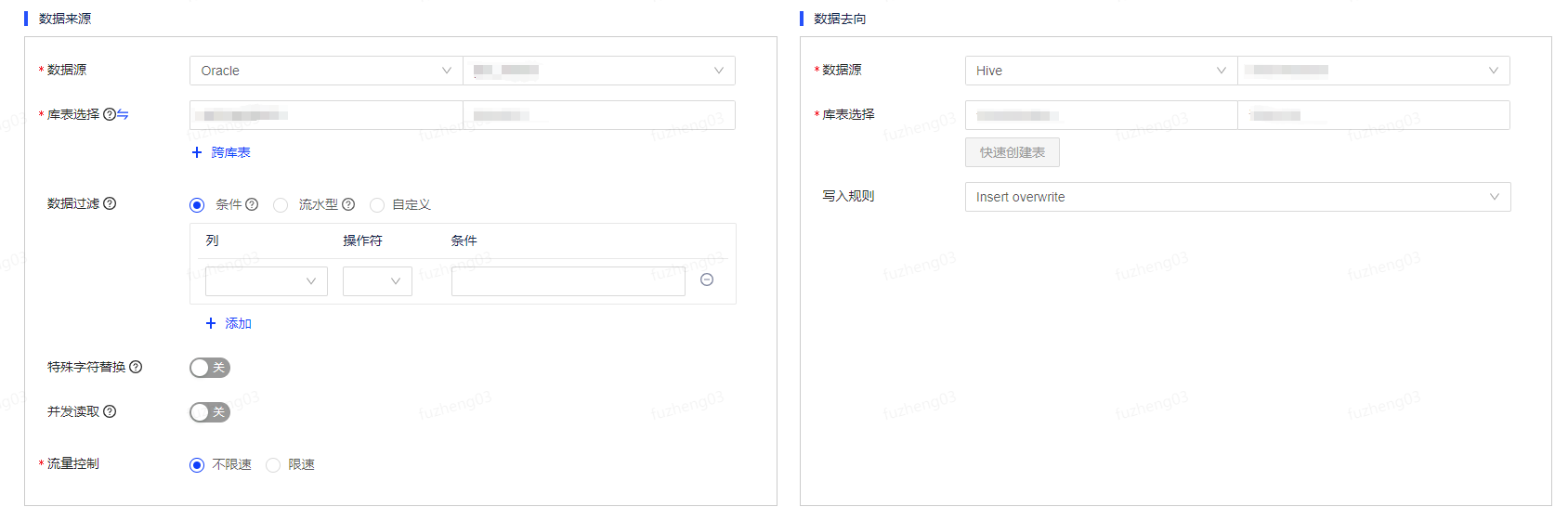
Oracle作为逻辑数据源
Oracle支持按照逻辑数据源模式匹配库表,用于同构异ip数据源批量抽取。配置步骤如下:
第一步,在数据来源中将数据源切换成逻辑数据源。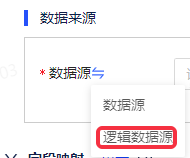
第二步,选择数据源类型及逻辑数据源,在库名和表名中分别填写正则表达式进行匹配。
第三步,点击解析,查看匹配结果。完成数据来源为逻辑数据源的配置步骤。
Oracle作为数据去向
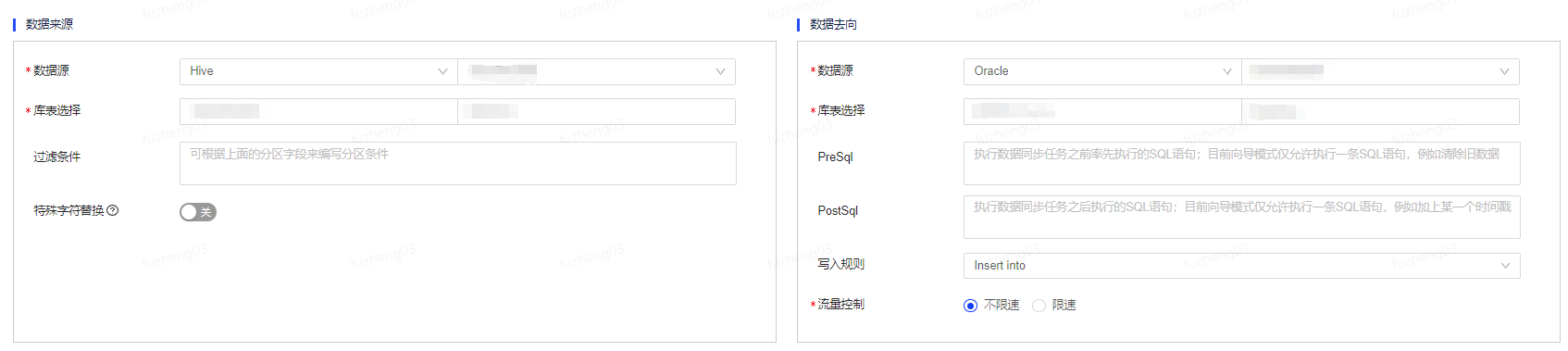
以Hive to Oracle为例,当Oracle作为数据去向时,除了需要填写数据源类型、数据源等基础信息之外,还可以填写PreSql和PostSql。
- PreSql:执行数据同步任务之前率先执行的SQL语句;目前向导模式仅允许执行一条SQL语句,例如清除旧数据。
- PostSql:执行数据同步任务之后执行的SQL语句;目前向导模式仅允许执行一条SQL语句,例如加上某一个时间戳。
Oracle当前只支持INSERT INTO写入规则。流量控制可根据实际情况进行填写。