基于物理数据源的离线同步任务
功能入口
在数据传输页面,单击左侧菜单栏中离线同步任务,进入任务管理页面。在该页面中,单击新建任务进行离线同步任务配置。
填写基本信息
在基本信息中完成任务名称、负责人、任务类型、引用参数组、描述的填写。
| 基本信息 | 说明 |
|---|---|
| 任务名称 | 必填项,中英文开头,支持连字符(-)或下划线(_),长度不超过128个字符 |
| 负责人 | 默认为创建任务的用户,可选择本项目下任一用户为任务负责人 |
| 任务模式 | 必填项,选项为向导模式和SQL模式。SQL模式支持编写SQL语言读取数据源数据。 |
| 引用参数组 | 引用参数组后,当前任务可使用参数组内参数 |
| 描述 | 输入同步任务描述,最长不超过128个字符 |
|
说明: 1、离线同步任务引用多个参数组内相同参数项时,系统取排在前面的参数组的参数值; 2、离线同步任务和离线开发任务引用的参数组内有相同的参数项时,取离线开发任务的参数组的参数值; 3、参数组可在“离线开发 - 公共资源”中进行查看和配置; 4、通过ndi.param-set.transfer-first 参数可以调整离线同步任务和离线开发任务的参数优先级(默认值为false:即离线同步任务的参数优先级低于离线开发任务的参数优先级)。 |
配置数据来源与去向
完成基本信息填写后,首先需要在数据来源配置离线同步任务节点的读取端数据源,以及需要同步的表等信息。
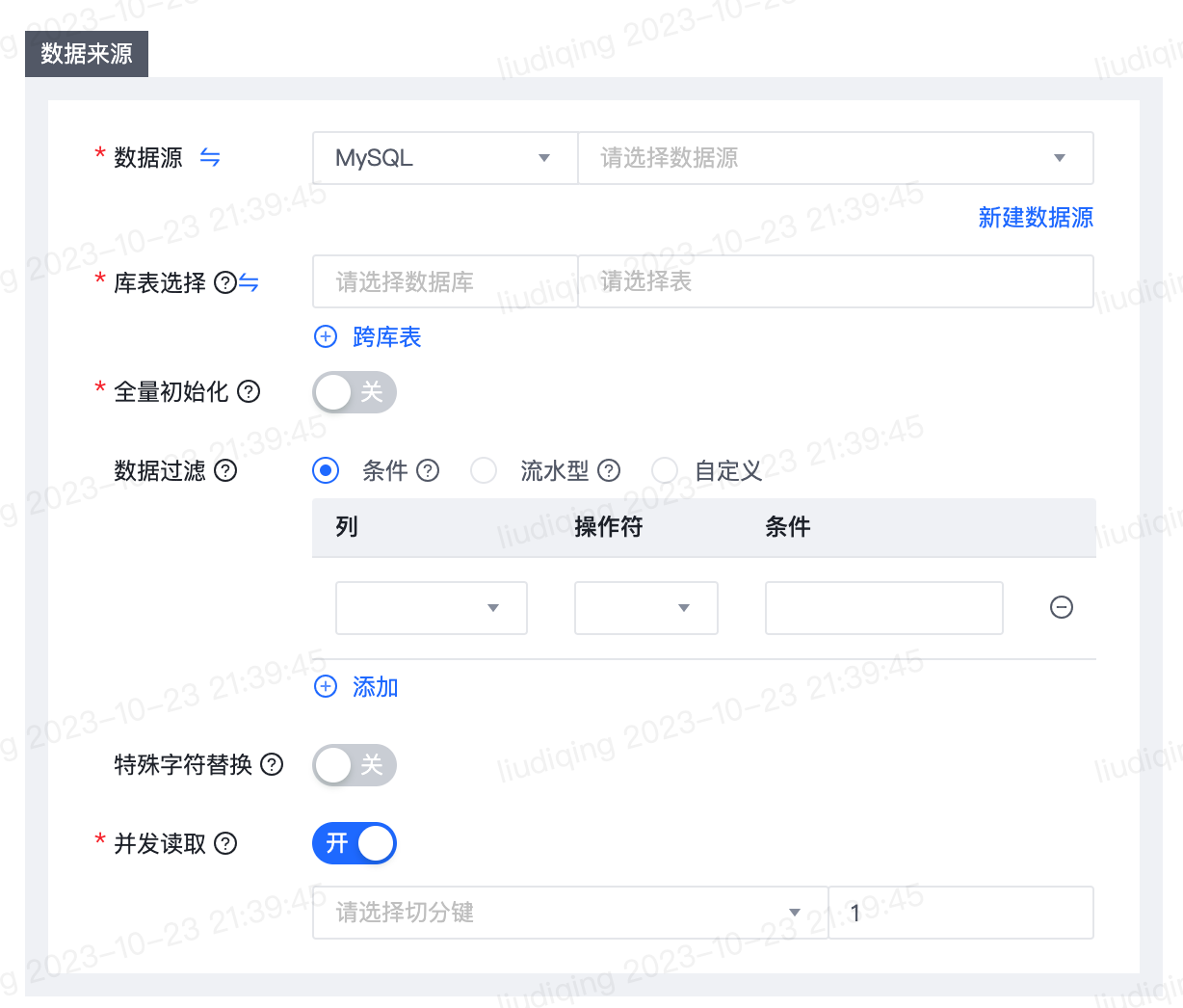
- 数据来源
| 基本信息 | 说明 |
|---|---|
| 数据源 | 必填项,选择数据源类型及数据源名称 |
| 查找方式 | 必填项,选项为库表选择和正则匹配,默认为库表选择: 库表选择:支持搜索或直接选择数据库表 正则匹配:通过正则表达式来匹配数据表 |
| 特殊字符替换 | 选择是否开启及替换内容 |
| 并发读取 | 选择是否开启并发读取。读取的数据将会根据切分键,按照并发度切分成指定的份数。 支持选择字符型字段作为切分键,支持的字段类型:VARCHAR、LONGNVARCHAR、NVARCHAR、NCHAR,建议使用带索引的字符型字段。 |
| 数据过滤项说明: 1. 条件:按列设置过滤规则,可添加一或多组条件,条件默认为AND关系; 2、流水型:从选择字段的起始值开始读取数据,读取到最新记录位置,下次从上次的最新记录读取至当前的最新记录; 3、自定义:填写where过滤语句(不含where关键字),通常用作增量同步,支持调度时间参数。时间参数用法详见时间参数用法详解。 具体说明如下:增量同步在实际业务场景中,往往会选择当天的数据进行同步,通常需要编写where条件语句,需先确认表中描述增量字段(时间戳)为哪一个。如表增量的字段为create_time,则填写create_time>需要的日期 ,如果需要日期动态变化,可以填写如create_time>${azkaban.flow.1.days.ago} and create_time<${azkaban.flow.current.date}。 |
完成数据来源的配置后,可以在右侧配置数据去向的数据源,以及需要写入的表信息等。
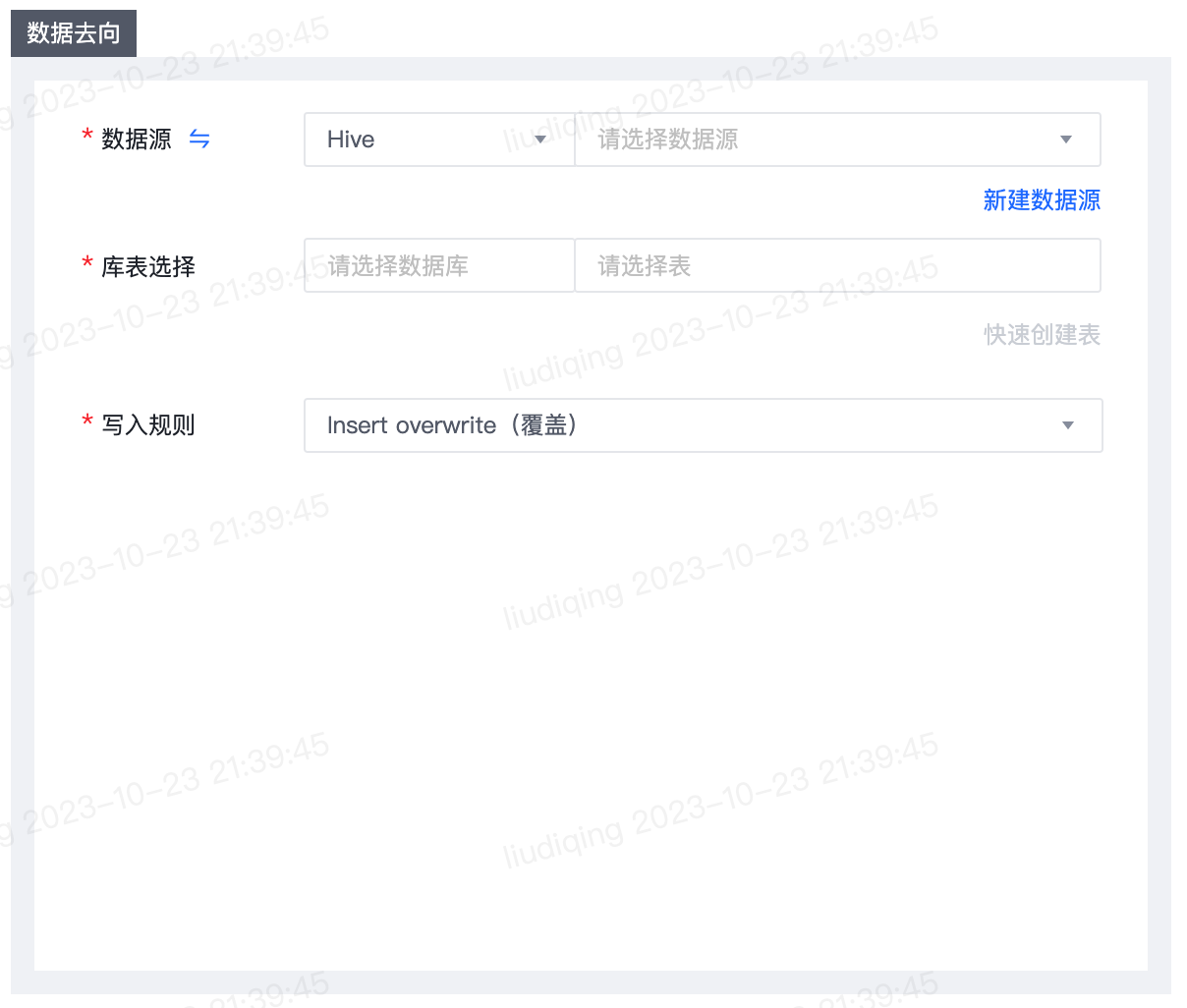
- 数据去向
此处以Hive为例:
| 基本信息 | 说明 |
|---|---|
| 数据源 | 必填项,选择数据源类型及数据源名称 |
| 库表选择 | 必填项,选择数据库及表 |
| 分区 | 当去向表为分区表时,支持配置分区模式,当前分区模式包括静态分区和动态分区。静态分区分区信息为azkaban参数,动态分区信息为来源字段的值或来源数据库的系统函数。 |
| 写入规则 | 写入规则默认为Insert overwrite,说明如下: Insert overwrite:覆盖数据,即先删除原表的数据,再执行写入操作 Insert into:以追加的方式向原表尾部追加数据 |
配置字段映射
在完成数据来源和数据去向的配置后,需要指定数据来源端和去向端的映射关系。支持获取最新表结构、同名映射、同行映射、清空映射、不导入以及自定义表达式。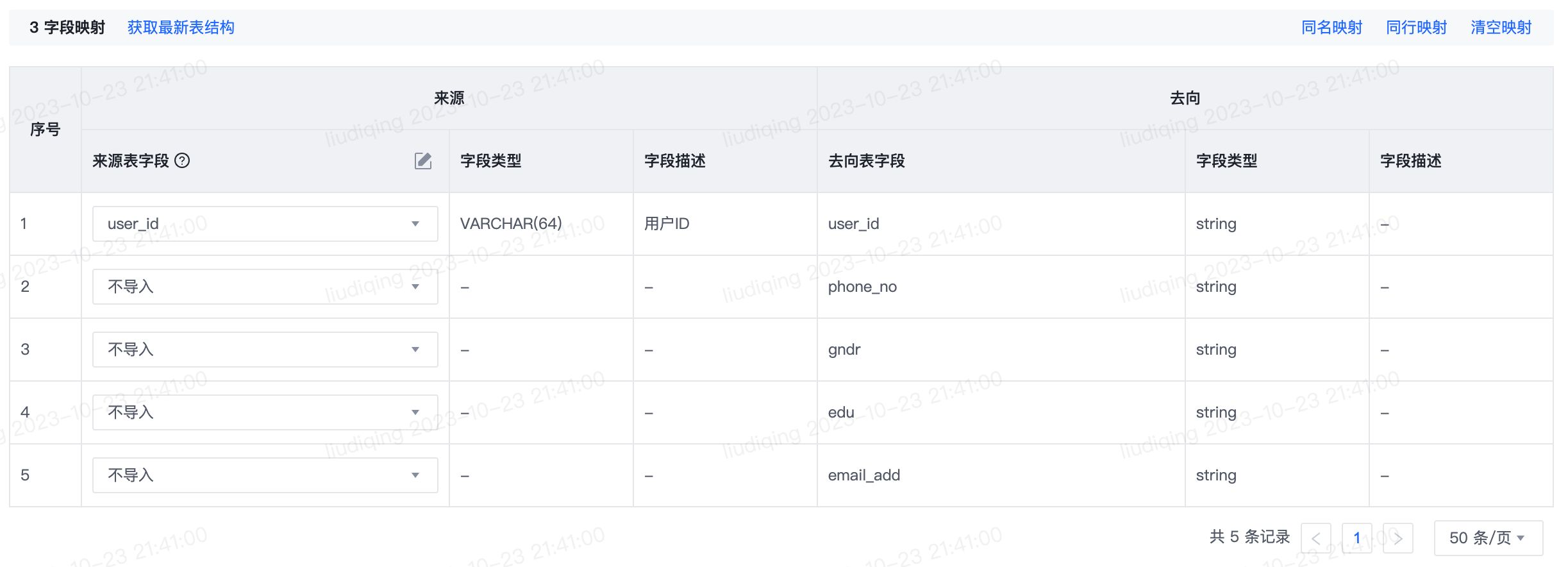
| 来源表字段信息 | 说明 |
|---|---|
| 同名映射 | 1. 系统默认匹配方式,可根据名称建立相应的映射关系。 2. 如果列名无法匹配,则该列来源字段显示为不导入,支持手动修改匹配列。 |
| 同行映射 | 系统根据同行建立映射关系,需注意匹配数据类型。 |
| 清空映射 | 数据去向为Hive、Doris、StarRocks、Maxcompute时,来源表字段均置为自定义表达式;其余数据去向时,来源表字段均置为不导入。 |
| 不导入 | 目标表中的这个字段将不会导入任何数据,如果目标表字段为非空,会导致任务报错。 |
| 自定义表达式 | 通过自定义表达式的方式导入数据,自定义表达式格式为:${表达式} as ${去向表列名}。 |
| 获取最新表结构 | 当来源表结构发生变化时,需要重新配置映射关系,通过该功能可以获得最新的来源表结构。 |
|
自定义表达式说明: 1、如果输入a,那么这个字段会导入字符串a; 2、输入源端数据库支持的SQL表达式比如current_timestamp as last_modify_time,将任务运行时间导入目标表的last_modify_time字段。 |
字段映射支持批量转换来源表字段的数据类型,如果字段映射列表中存在来源表字段类型和去向表字段类型满足指定条件的组合,支持将相应的来源表字段类型进行批量转换。点击批量转换数据类型按钮可进行批量转换数据类型设置。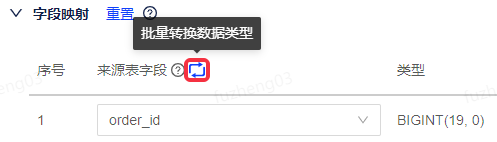
在批量转换数据类型页面中支持通过设置来源表字段类型、去向表字段类型以及数据类型转换表达式完成批量转换规则的配置。
此处的转换逻辑是,将来源表字段类型通过数据类型转换表达式进行转换,去向表字段类型作为转换范围的约束条件,例如当前来源表字段类型为int,默认转化为去向表字段类型中既有int又有string,现在希望将int->int的映射关系全部变为int->string,需要在来源表字段类型处选择int,去向表字段类型处选择int,数据类型转换表达式处填写int转化为string的表达式(表达式写法取决于来源表类型)。
|
说明: 1、若去向表字段类型为空时,将所有字段类型为指定类型的来源表字段进行批量转换; 2、如果添加了重复的来源表字段类型和去向表字段类型,则取表格靠上行的数据类型转换表达式进行转换; 3、若数据来源为:Hbase、FTP、HDFS、MongoDB或数据去向为:FTP、HDFS、MongoDB、Redis时,不支持批量转换数据类型。 |
关于数据类型转换表达式格式为{表达式} as {列名},其中{表达式}为填写的数据类型转换表达式, {列名}为填写的转换后来源表字段名称。
- 支持填写常量、系统内置参数、参数组参数、函数表达式(若数据来源为关系型数据库,支持填写来源数据库的系统函数和自定义函数;若数据来源为其他数据源类型,支持填写Spark函数)。(这部分功能继承了上面的自定义表达式功能)
- 填写格式中的{列名}建议填写为${target_column},即去向表字段名称。如果需要填写为${source_column},需要保证来源表字段名称中没有空格,否则任务会报错。
最后,通过一个示例介绍下该功能的用法。以MySQL to Kudu为例,选择的来源表字段类型为date,去向表字段类型为string,数据类型转换表达式为:date_format(${source_column}, '%Y-%m-%d') as ${target_column},如果命中的来源表字段名称为age,去向表字段名称为Age,则在字段映射列表中会将来源表字段age切换为自定义表达式:date_format(age,'%Y-%m-%d') as Age。
高级配置
对于传输任务根据不同的场景有时候还需要进行高级项的配置,比如流量控制、来源表结构变化策略、脏数据管理、数据脱敏、任务参数等。
流量控制
流量控制支持不限速和限速两种模式,当选择限速时,支持条/s和MB/s。
来源表结构变化策略
当数据来源表(仅限关系型数据库)新增字段时,支持配置来源表结构变化策略,具体如下:
- 当数据来源为ClickHouse、DB2、DDB(DBI)、DDB(QS)、DM、HANA、Maxcompute、MySQL、Oracle、Phoenix、PostgreSQL、SQLServer、TiDB、Vertica时,针对来源表新增字段的情况,支持配置任务策略:忽略新增字段、任务报错。
- 当数据来源为ClickHouse、DB2、DDB(DBI)、DDB(QS)、DM、HANA、Maxcompute、MySQL、Oracle、Phoenix、PostgreSQL、SQLServer、TiDB、Vertica,且数据去向为本项目本集群的Hive数据源时,针对来源表新增字段的情况,支持配置任务策略:忽略新增字段、任务报错、去向表字段新增该字段,建立映射并同步数据。
- 去向表字段新增该字段、建立映射并同步数据使用项目keytab执行SQL语句。
- 若此处不配置任务策略,默认忽略新增字段。
| 说明:使用过程中需要事先配置策略。配置策略后源端新增字段,相应的目标端才会生效。 |
脏数据管理
当数据去向为Hive(集群内Hive,不支持外部登记的Hive数据源)时,支持脏数据管理功能。此处可识别的脏数据为来源端和去向端的数据类型不匹配且不支持转换的数据,这些数据会被赋值为null,从而被认定为脏数据。
脏数据管理支持脏数据保存和脏数据容忍两个功能。脏数据保存支持用户设置脏数据的保存位置,当前支持存入Hive表或MySQL表。如果当前创建离线同步任务的用户有对应数据库的建表权限,则可在页面一键生成脏数据表。
- 脏数据存放在Hive当中时,其表结构如下:
字段名称 字段类型 字段内容 含义 flow_node string 引用任务的离线开发任务名称和离线同步节点名称 引用该传输任务的离线开发任务名称(azkaban.flow.alias.flowid)和离线同步节点名称(job.id),任务名称和节点名称之间以“:”分割,如:flowname:nodename。如在传输试运行任务,则分区值为:trial operation record string 错误记录 展示该运行记录即可,按照json格式,如:{"ID":"2018903","Name":"张三"} category string 错误分类 分类项:空指针、主键或唯一键冲突、类型转换失败、其他 msg string 错误信息 系统错误信息 一级分区:time string 任务执行时间 任务执行时间,格式如:2021-08-01 01:01:01 二级分区:execid int 实例ID 任务实例的id(execid) - 脏数据存放在MySQL当中时,其表结构如下:
字段名称 字段类型 字段内容 含义 execid int 实例ID 任务实例的id(execid) flow_job string 引用任务的离线开发任务名称和离线同步节点名称 引用该传输任务的离线开发任务名称(azkaban.flow.alias.flowid)和离线同步节点名称(job.id),任务名称和节点名称之间以“:”分割,如:flowname:nodename。如在传输试运行任务,则分区值为:trial operation time string 任务执行时间 任务执行时间,格式:YYYY-MM-DD HH:MM:SS,如:2021-08-01 01:01:01 record string 错误记录 展示该运行记录即可,按照json格式,如:{"ID":"2018903","Name":"张三"} category string 错误分类 分类项:空指针、主键或唯一键冲突、类型转换失败、其他 msg string 错误信息 系统错误信息
当关闭脏数据容忍时,支持用户配置脏数据容忍条数以及脏数据占比,当脏数据超过设定条数或脏数据占比大于设定值(占比统计在任务执行结束后)时,任务报错并置为失败;当数值设置为0时,表示不允许存在脏数据。当数据去向为Hive时,默认允许脏数据。
在运行日志中可查看脏数据条数:
数据脱敏
数据传输支持静态脱敏,支持敏感字段自动识别,也支持手动添加敏感字段(脱敏规则详情请见脱敏管理)。
- 扫描配置
如果不确定表的敏感字段有哪些,支持通过扫描来源表确定来源表的敏感字段。支持选择脱敏规则,输入扫描条数、扫描匹配率,并选择扫描执行队列。脱敏规则选取脱敏规则后,扫描来源表字段时将基于脱敏规则对应的敏感类型进行扫描。扫描条数指的是根据指定的扫描条数抽取来源表字段进行扫描,如果填写的扫描条数>数据来源端读取总条数,则扫描条数取数据来源端读取总条数。识别对象为字段内容等,在进行数据扫描时,如果字段的内容被识别为敏感类型的比率≥扫描匹配率,则该字段被识别为敏感字段。执行队列为扫描任务执行使用的队列资源。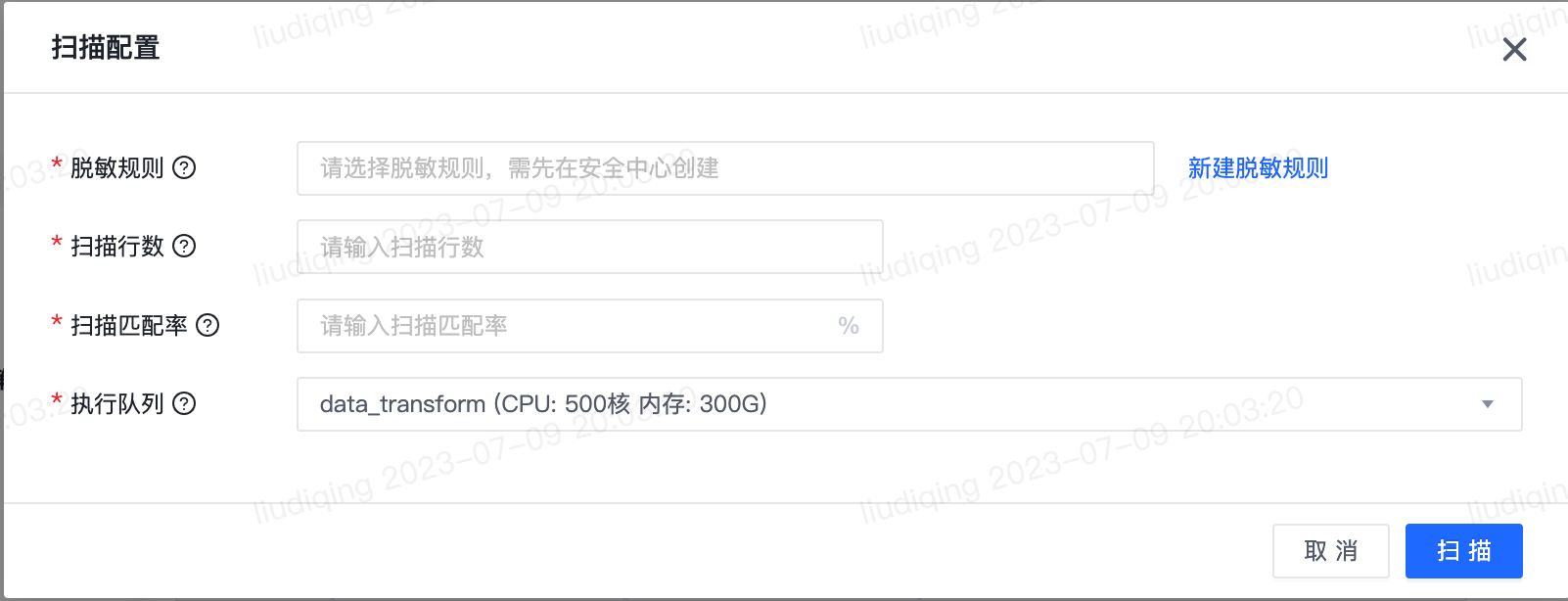
|
说明: 1. 选择脱敏规则后,请点击扫描按钮,来识别需要脱敏的来源表字段,扫描完成后方可保存任务。 2. 每次任务运行时,会对脱敏配置栏展示的来源表字段按照脱敏算法处置后写入去向表字段。备注:如果扫描失败,允许保存任务,但任务运行时将不会进行数据脱敏。 3. 如果与数据脱敏相关的任务配置信息(如:数据来源的表名)、安全中心的脱敏规则相关信息、来源表字段名称和字段描述发生变更,请重新扫描,否则任务运行时仍将按照脱敏配置展示项进行数据脱敏,可能出现写入数据不符合预期或实际未脱敏等风险。 |
如果已经知道表中的敏感字段是哪些,可直接通过“添加”按钮进行添加,需要配置“来源表字段”和“脱敏规则名称”。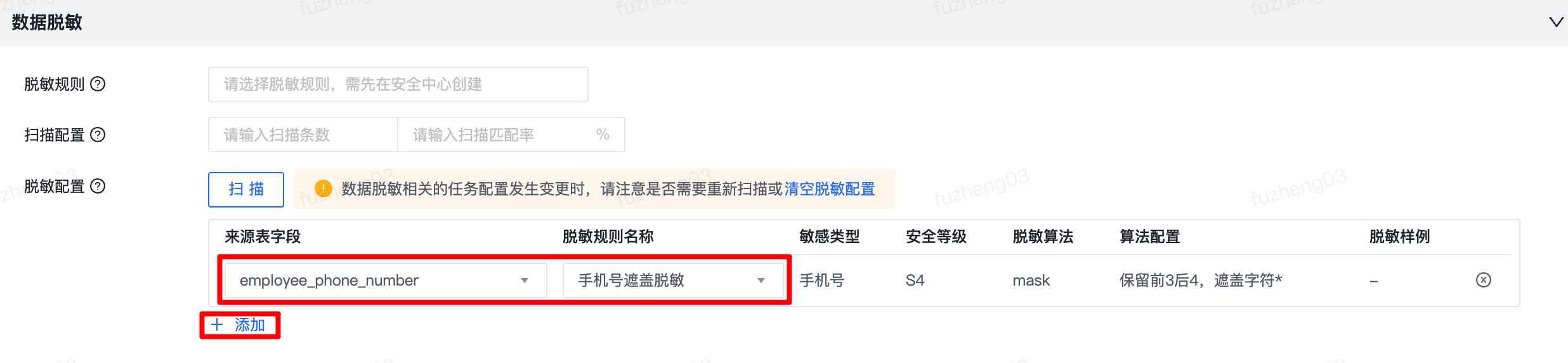
断点续传
断点续传功能支持数据来源为关系型数据库,去向为Hive时的场景。
如果打开断点续传开关,会记录失败实例中执行成功的子任务,重新执行实例时仅重新执行剩余的子任务,不再执行已执行成功的子任务。开关打开后在以下两个场景生效:
1.离线开发任务的数据同步节点如开启自动重试,则节点失败自动重试时会重新执行剩余的子任务,直至实例运行成功或达成指定重试次数为止;
2.针对调度运行失败的实例,重跑实例时会重新执行剩余的子任务。如实例重跑时仍运行失败,则会记录本次成功的子任务,再次重跑实例时仅重新执行剩余的子任务,不再执行历次重跑实例时已执行成功的子任务。
|
注意: 1. 任务如果打开断点续传开关,请勿修改引用任务的数据同步节点名称。 2. 任务如果打开断点续传开关,在节点失败自动重试或实例重跑期间,请勿修改任务使用的数据源的账号和密码。 |
任务参数
此处支持同步条数限制和自定义参数设置。限制同步条数指的是每次运行任务时同步的条数上限,未填写表示没有限制。
包含作业参数、数据来源与数据去向对应的源端参数与目标端参数。具体参数详见高级设置参数。