普通用户入门
普通成员访问本平台,有2种方式,一种是用户访问本平台后,可以主动申请加入项目,第二种是由项目负责人或管理员将自己的账号添加到项目中。否则,用户除了访问平台首页或个人中心外,访问具体的产品都会报错提示没有权限,需要申请加入项目。
用户可以在页面上点击“申请加入项目”,跳转到申请加入项目的页面,或者直接在个人中心申请加入项目。
用户主动加入的入口如下,在页面右上角用户中心:
普通用户可在用户中心申请申请加入已有的项目,或者也支持创建新项目。
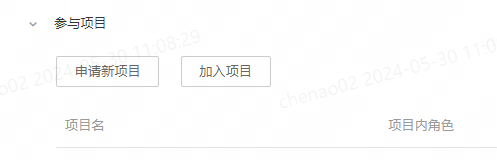
申请加入项目时,需要一并选择自己在该项目中的角色,并且可选择是否申请项目组角色:
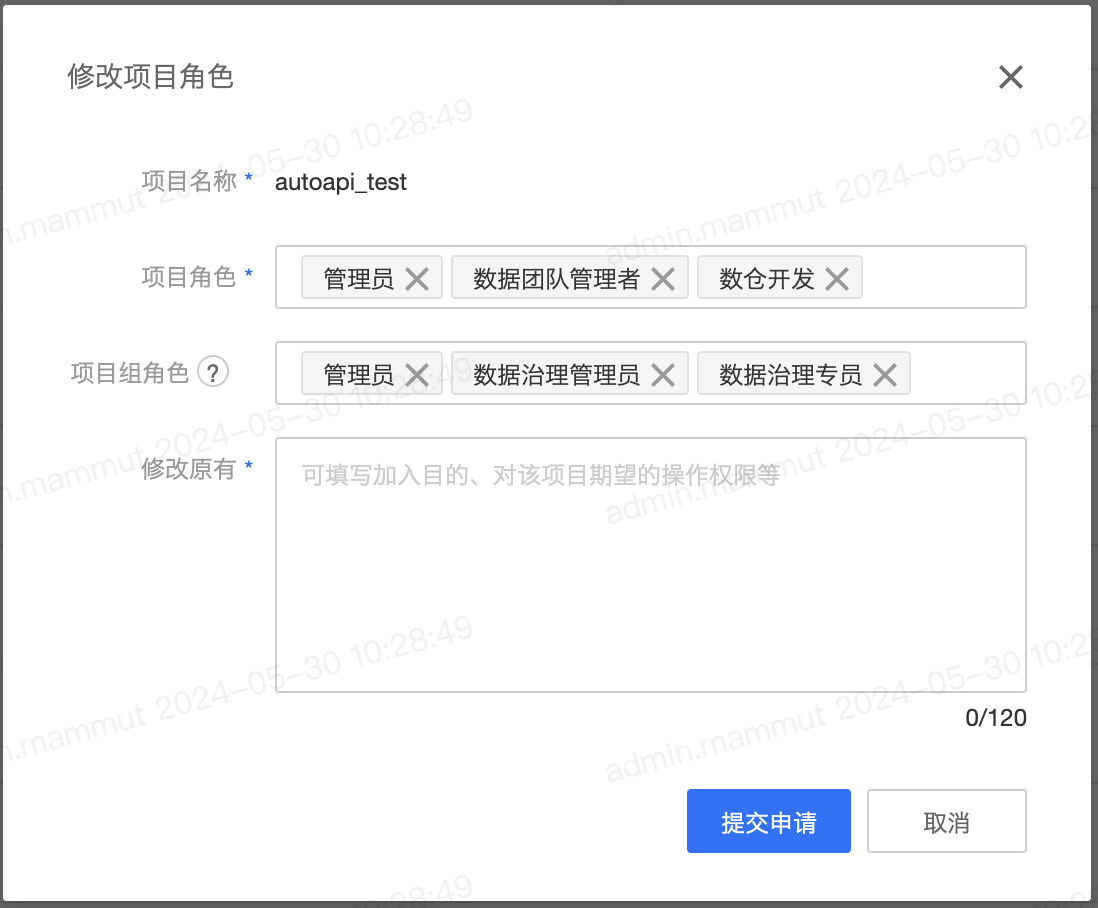
注:在Easydata 8.0-update03及之后的版本中,当用户加入项目后,还支持在用户中心申请修改或新增所在的项目角色。申请后,会生成审批工单,项目负责人或管理员等审批通过后,成员角色会自动修改。

离线开发案例演示
本文将从一个很小的案例来说明如何在本平台上完成一个离线开发任务的开发,来帮助普通用户快速上手。
这里,假设当前用户已经由项目负责人添加到一个项目中,并授予相关的功能权限、数据权限、队列权限。权限相关操作可以参考平台管理、项目中心和安全中心。
- 功能权限表示当前用户可以访问哪些页面的访问或部分功能的操作权限。
- 数据权限表示当前用户可以在哪些Hive库建表、读写哪些表等。
- 队列权限表示操作Hive库表时,可使用哪些队列的CPU和内存在完成代码运算。
当前案例描述:
- 创建Hive表t1,并通过上传文件方式,完成该表的数据录入;
- 创建Hive表t2,再通过线上调度任务,完成t1表到t2表数据的定时写入。
涉及产品:
- 自助分析
- 离线开发
- 数据地图
- 任务运维中心
上述产品,都可在页面左上角导航入口,点击的侧边弹框中查看(因不同客户购买的产品有差异,具体以购买的为准)。
步骤演示(共13步):
1)在【自助分析】创建第一个Hive表
对于新用户,进入自助分析时,需要先新建Query。Query用于用户来编辑SQL代码,并运行SQL。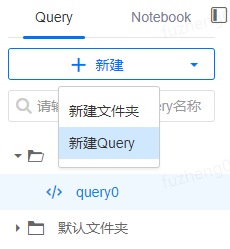
输入Query名称,选择保存位置。
完成Query创建后,在Query中写入建表语句。本案例的代码如下,表示在poc_ods库,创建一个表ods_employee_info_upload,textfile格式,用逗号分隔。
|
注意: 当前用户需要需要根据自己所在项目,把代码中的poc_ods替换为自己有建表权限的库。此外,表名有可能已经存在,因此可在表名后增加一些字母或数字等。 |
CREATE TABLE poc_ods.ods_employee_info_upload(
`employee_id` string comment '员工工号',
`employee_name` string comment '员工名称')
COMMENT '员工信息表'
row format delimited fields terminated by ',' stored as textfile完成SQL之后,点击如下图中的红框的运行,完成表的新建。该表用于后续通过文件上传方式将数据导入进去。
2)用户本地构造一个csv格式的文件
如下图,按照上一步骤中表的表结构,在csv文件中,构造2条记录:
3)在【数据管理】-【个人文件】上传csv文件
如下图,为将本地的csv文件,上传到HDFS集群上个人的文件目录下: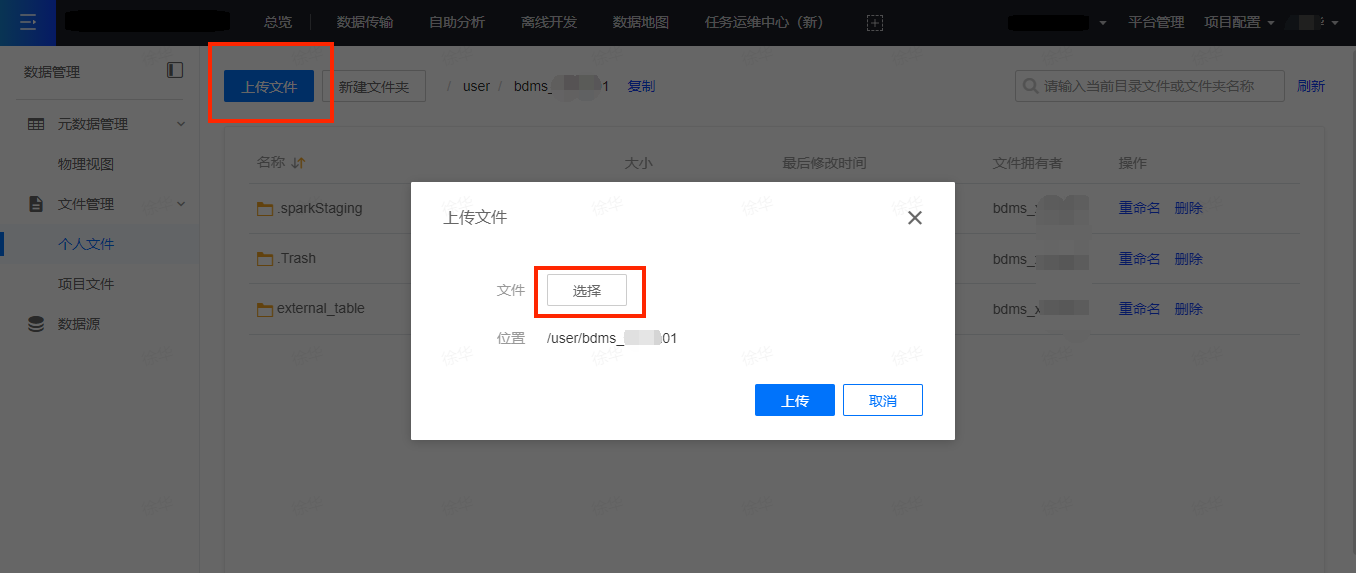
4)在【自助分析】将csv文件移动到第一个Hive表的目录下
在自助分析的Query下,在Query中写入将HDFS文件移动到Hive表的目录下的代码。本案例的代码如下,其中的'/user/bdms_xuhua01/1.csv',表示上一步中上传的csv文件的路径。
| 注意: 当前用户实际在操作中,可在【数据管理】-【个人文件】中查看自己的路径。 |
load data inpath '/user/bdms_xuhua01/1.csv'
overwrite into table poc_ods.ods_employee_info_upload;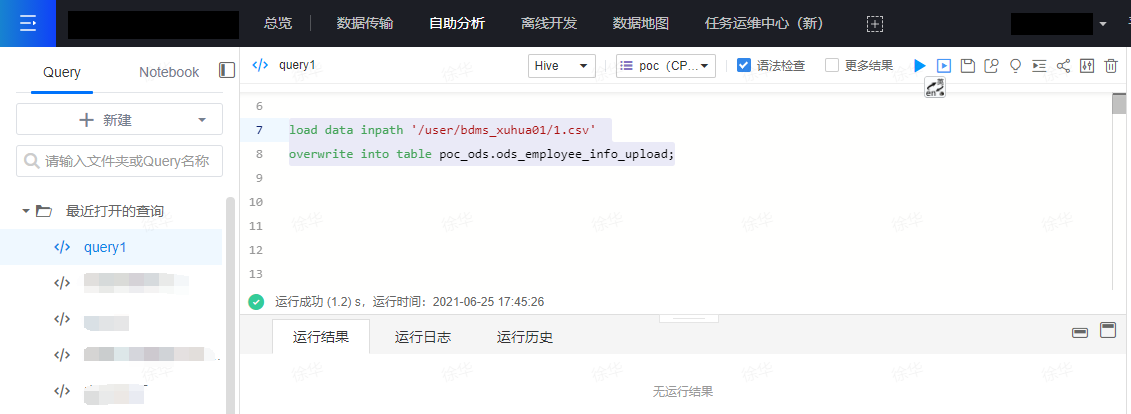
下图为用户自行查看自己的文件地址: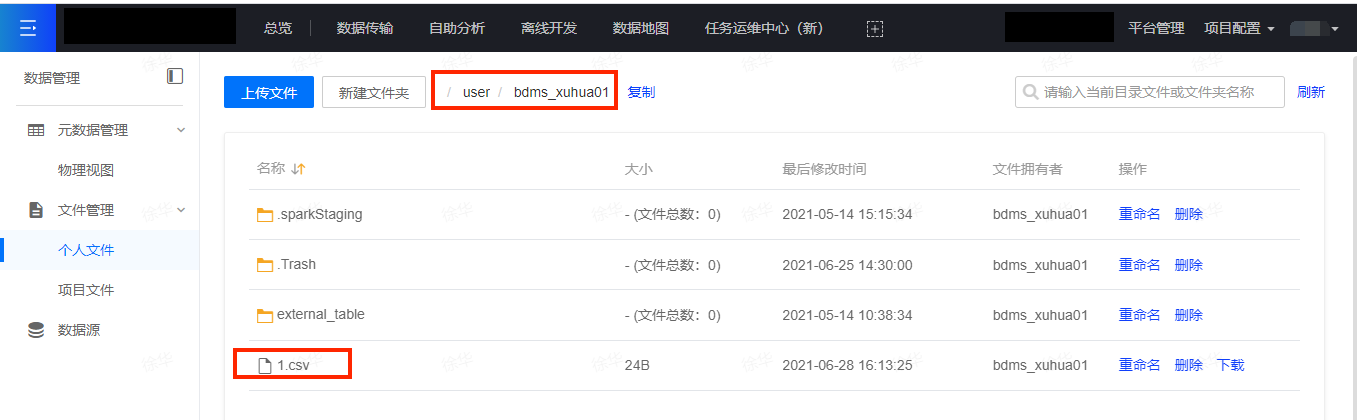
5)在【数据地图】预览数据
下图为在数据地图搜索ods_employee_info_upload表: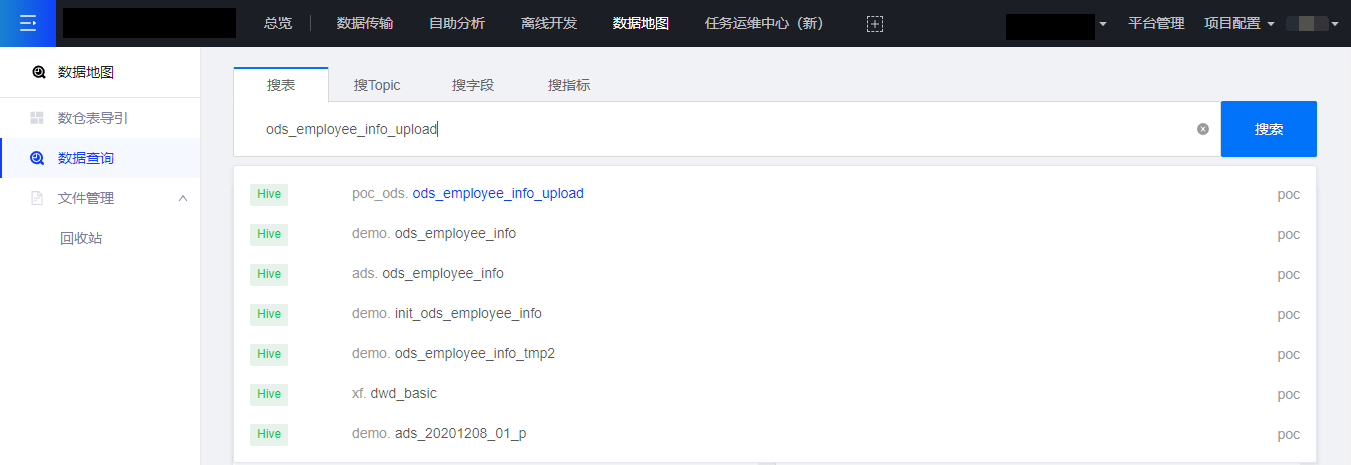
下图为在数据地图表详情中预览数据,显示数据已经导入: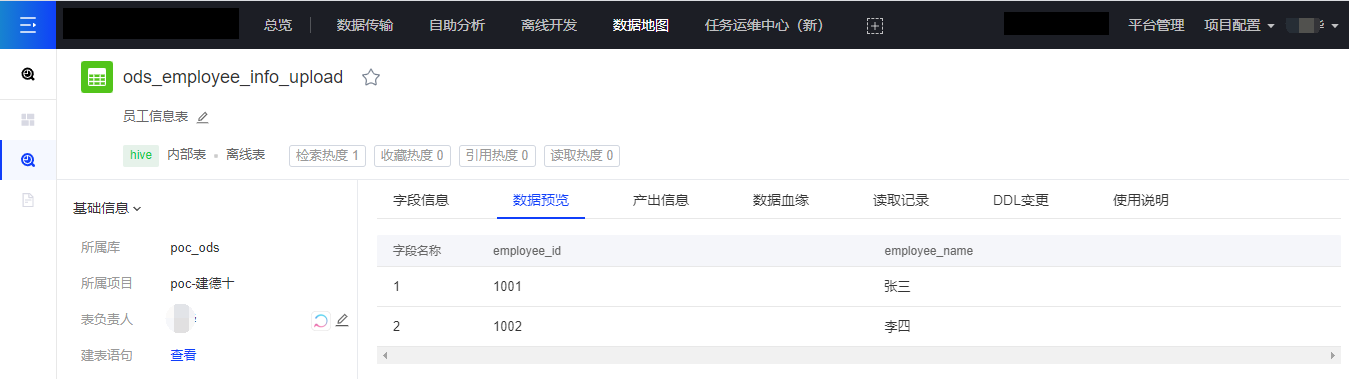
6)在【离线开发】创建第二个Hive表
在前面几步中,已经完成第一个Hive表的创建和数据导入。从这一步开始,会再创建第二个Hive表,并通过线上调度任务,定时从第一个Hive表导入到第二个Hive表。
下图为离线开发的新建离线表入口:
在新建离线表中,选择数据库demo,新建dim_employee_info表,表结构如下图:
| 注意: 当前用户在操作时,需要选择自己有权限的库。此外,表名有可能已经存在,可能执行新建时会失败,因此可在表名后增加一些字母或数字等。 |
7)在【离线开发】创建多节点任务
在离线开发页面,左侧为任务列表,当前用户可在默认文件夹下新建任务,在弹框中创建自己的第一个任务。任务的命名,建议和上一步创建的第二个Hive表同名。
下图为默认文件夹右键选择新建任务: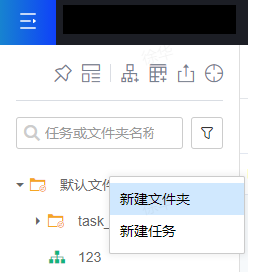
下图为创建一个任务名称为dim_employee_info**的多节点任务:
8)在多节点任务中拖入一个SQL节点
完成任务创建后,会进入到任务的开发模式的画布中,默认仅包含一个和任务同名的虚拟节点。
在右侧节点列表中,将SQL节点拖入中间画布区域,并重命名节点。命名建议按照dml_开头,并追加上多节点任务的名称。
下图为在任务中增加了一个名称为dml_dim_employee_info的SQL节点。
接着,将鼠标移动到SQL节点,会出现连接点,点击后移动到虚拟节点,也会出现连接点,松开鼠标,完成节点上下游依赖关系构建。
9)在SQL节点内写入加工SQL
完成SQL节点新建后,可双击SQL节点,在弹框中编写HiveSQL,完成从本案例第一个Hive表到第二个Hive表的数据加工逻辑。
示例代码如下,当前用户请根据实际自己创建的两个表,做相应修改。
其中的'${azkaban.flow.1.days.ago}'表示azkaban的参数,表示昨天,格式如:2021-06-01。该例子表示,将每天加工的数据,写入到昨天的日期分区下,完成数据归档。
INSERT OVERWRITE TABLE demo.dim_employee_info
PARTITION (ds='${azkaban.flow.1.days.ago}')
select
employee_id,
employee_name
from
poc_ods.ods_employee_info_upload;如下图,为SQL节点内写入实例代码,之后点击右上角临时保存。临时保存后,会回到当前任务的开发模式,再次进行任务的保存。如果不进行任务的保存,关闭当前任务或浏览器后,节点的内容还会保持上一次任务保存时的内容。
10)测试节点
完成数据开发后,可在开发模式运行SQL节点,以验证SQL逻辑的正确性。
选中需要运行的节点,再点击设置并运行,即可开始节点运行。
如下图,为点击设置并运行后的弹窗,点击运行即可。
运行结束会有浮框提示运行结果,可点击开发模式画布顶部的运行结果,查看运行结果。
如下图,为节点的运行结果页面:
运行结束,则可以在自助分析执行查询语句,查看结果表的数据。也可以在数据地图中找到产出表,通过预览查看数据。
11)任务提交上线
完成测试后,则可以将任务提交上线。
下图为提交上线入口。任务上线后,状态会从未上线变为未调度。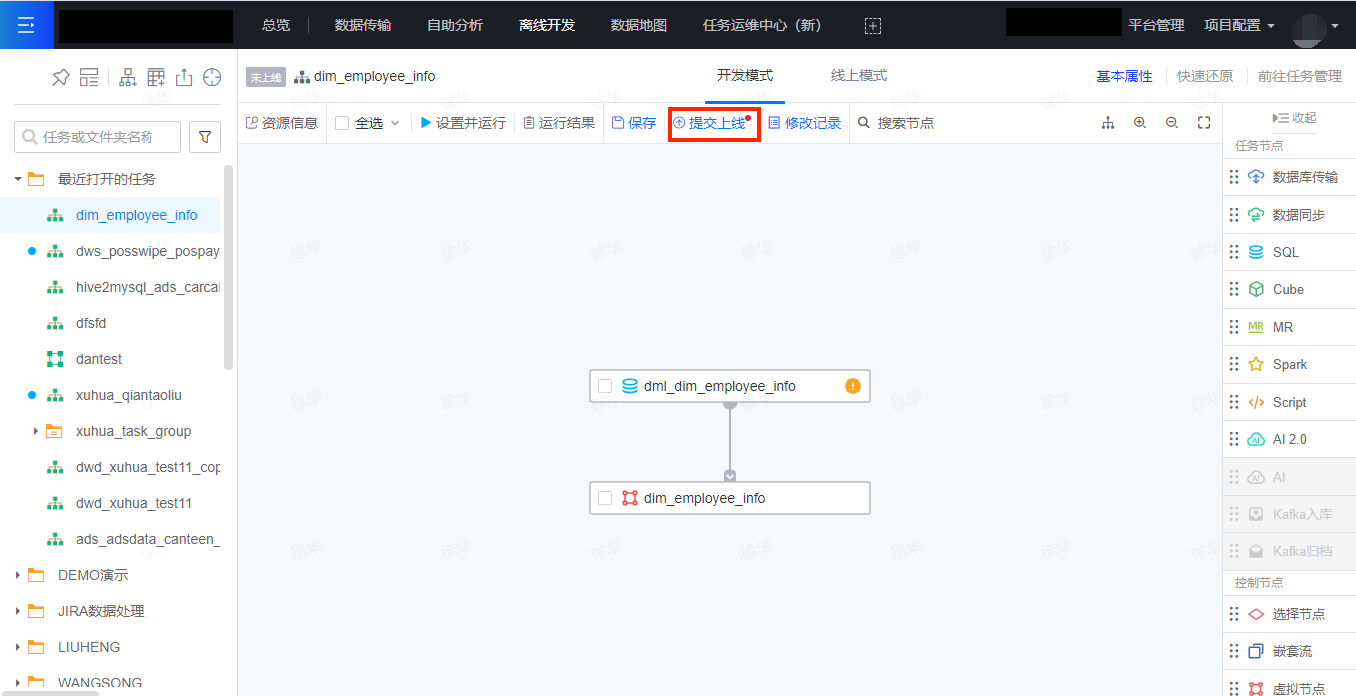
12)任务编辑调度
任务上线后,还不会定时调度,需要对任务配置调度,才能完成任务定时周期性地执行。请按照下面的指引完成配置。
首先,切换到任务的线上模式,然后点击画布左上角的编辑调度。
然后,在画布左上角,选中全部开启,让线上任务所有节点的启用。接着,点击设置并提交调度。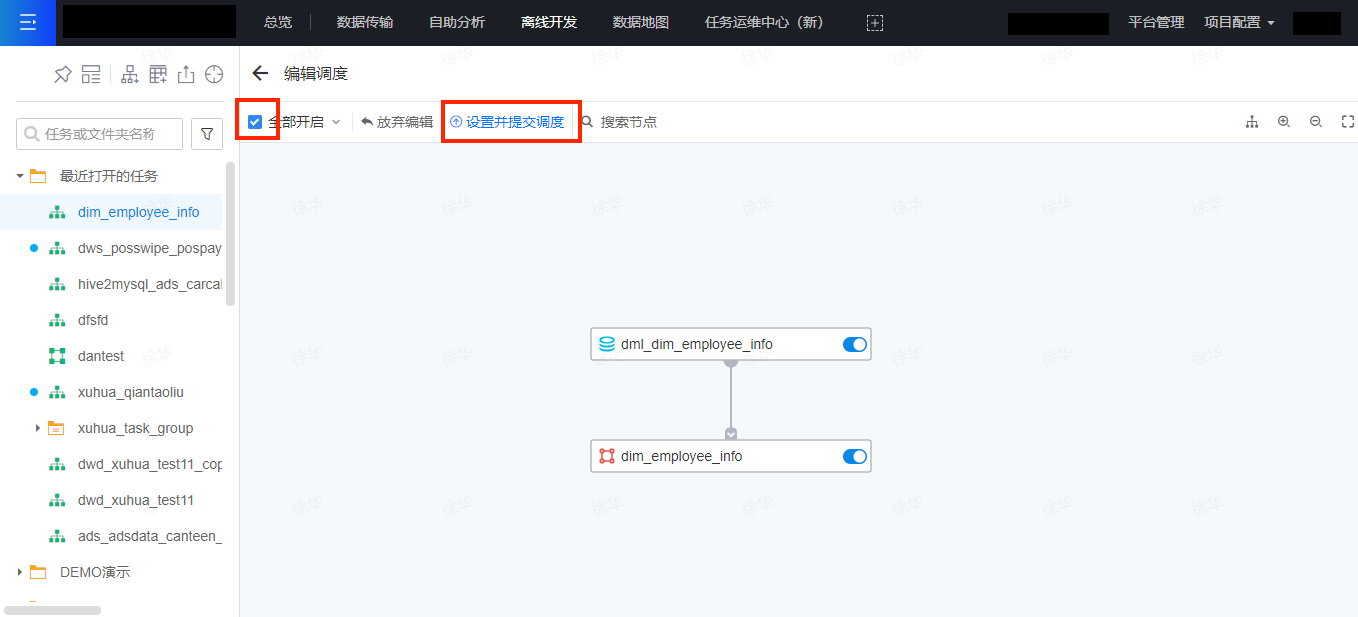
|
补充说明: 关于弹框中调度周期和首次执行时间,表示的是,从首次执行时间设置的时间开始,执行第一次线上调度,之后按照调度周期设置的时间周期,进行周期性调度。如下图的案例表示,首次执行将在2021-06-25 18:09,第二次将在2021-06-26 18:09。  |
13)在【任务运维中心】查看任务的实例
完成上一步骤后,可前往任务运维中心(新)查看任务的实例(需在设置的首次执行时间之后才能看到)。
在任务运维中心(新)页面点击周期实例运维菜单,搜索任务名称,点击蓝色的实例ID,进入到实例详情页,查看实例的运行情况。
下图为实例运维中搜索任务名称: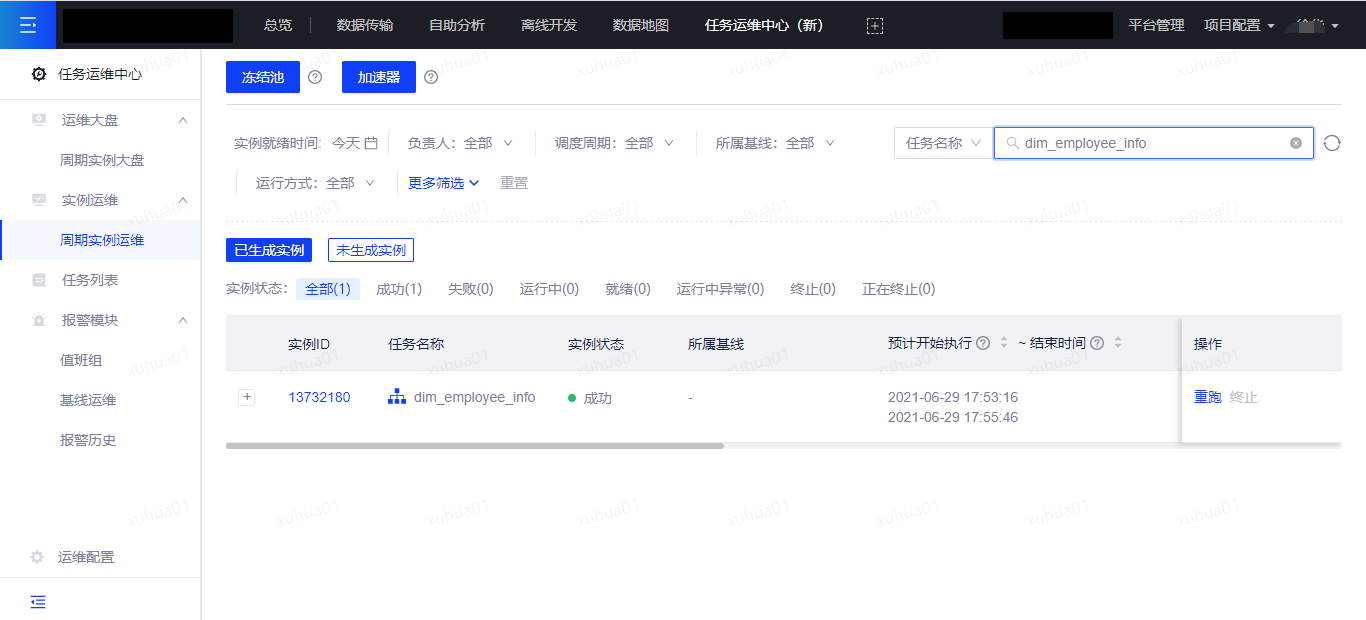
下图为实例详情页: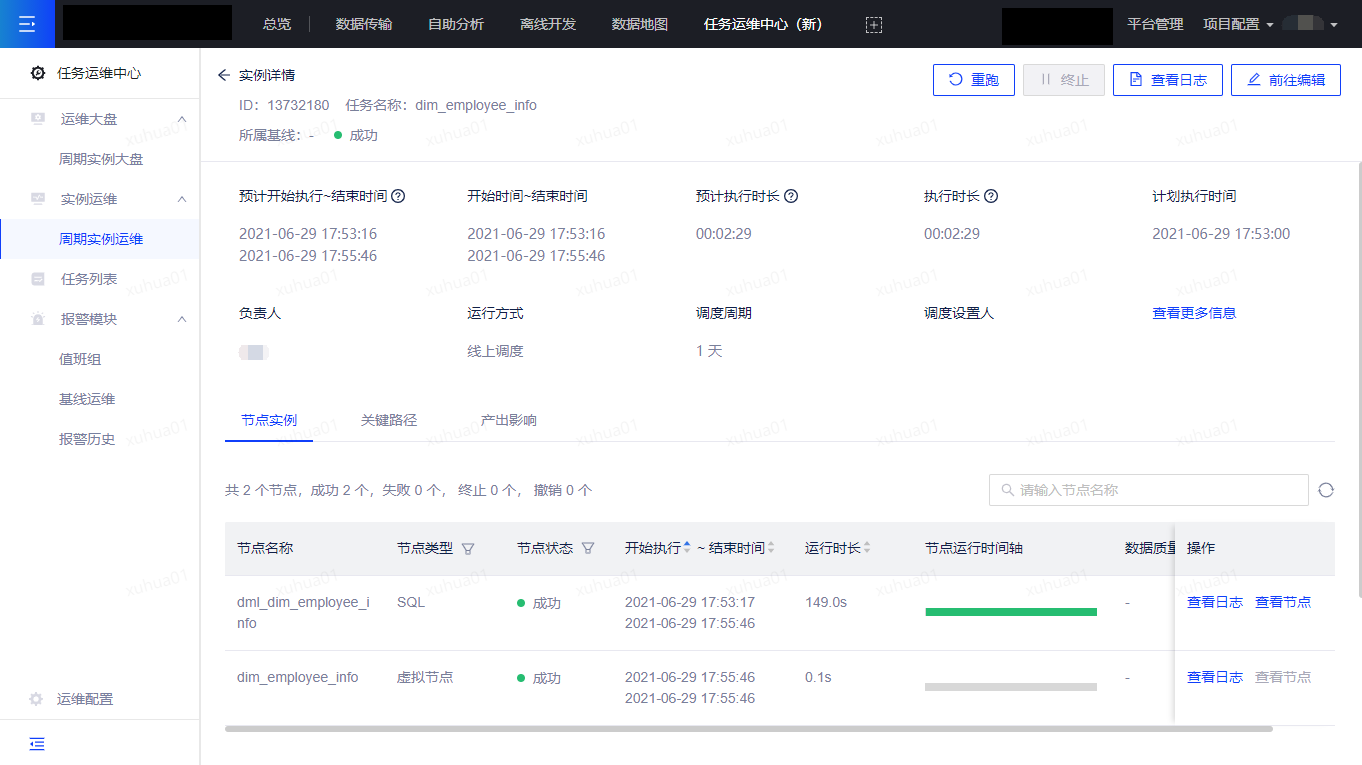
总结
本节从一个极简的例子来说明了如何完成自己的第一个数据开发任务,过程中涉及到了自助分析、离线开发、任务运维、数据地图等子产品的使用。对于这些产品,还有大量的内容和细节没有讲到。对于整个大数据平台,也有诸多别的产品没有涉及。
如需更详细的治理与开发一体化操作流程案例,请查阅数据治理与离线开发一体化全流程案例; 如需查看更多产品细节,请参考产品详细说明与操作指导章节。