服务编排
在实际业务使用过程中,有较多场景需要对API进行业务逻辑加工,或异构数据源实现表的关联查询等复杂场景,仅仅通过向导或脚本模式新建API已不能满足需求,服务编排正好能够解决这样的问题。
服务编排支持构建串行、并行的工作流,通过开始节点、结束节点、API节点、Python节点和条件节点满足更加复杂的加工逻辑处理。
服务编排功能支持用户使用托拉拽配置的方式定义一个查询工作流,支持异构数据源查询,条件取数等复杂数据服务API的场景。工作流中用户可以引入API节点(查询原子API),脚本节点(支持Python2.7,用于数据处理),条件节点(支持Python2.7,用于工作流分支控制),UDF节点(支持java UDF,用于数据处理),其中开始节点和结束节点默认存在。
服务编排功能使用前提
权限相关
使用服务编排功能之前,需前往安全中心 - 功能权限,由项目负责人或管理员设置API的新建、查看、导出下载、编辑、删除、复制等权限。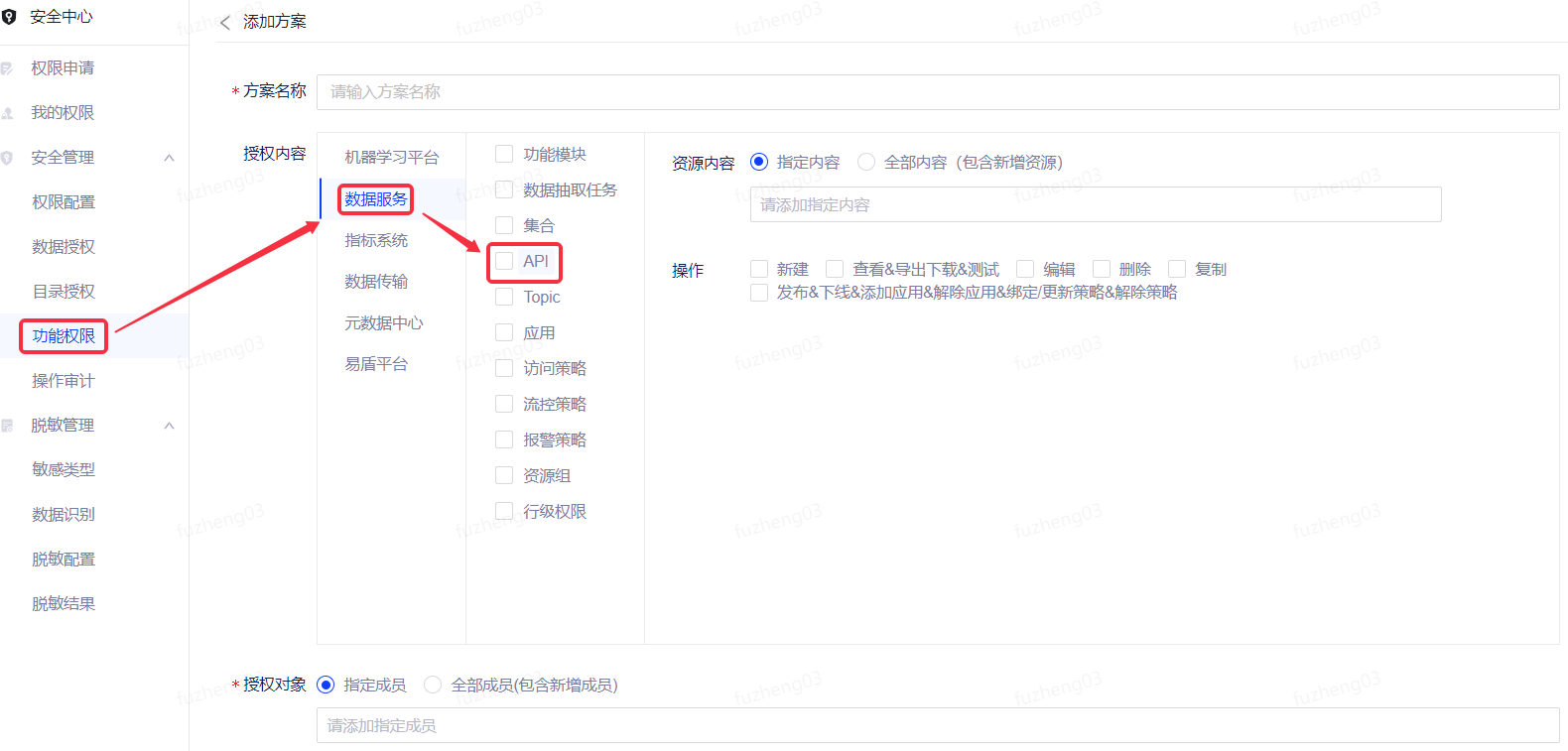
服务编排资源组
除了权限之外,还需在配置管理 - 资源组管理页面完成服务编排资源组的创建或直接使用系统预置的服务编排资源组。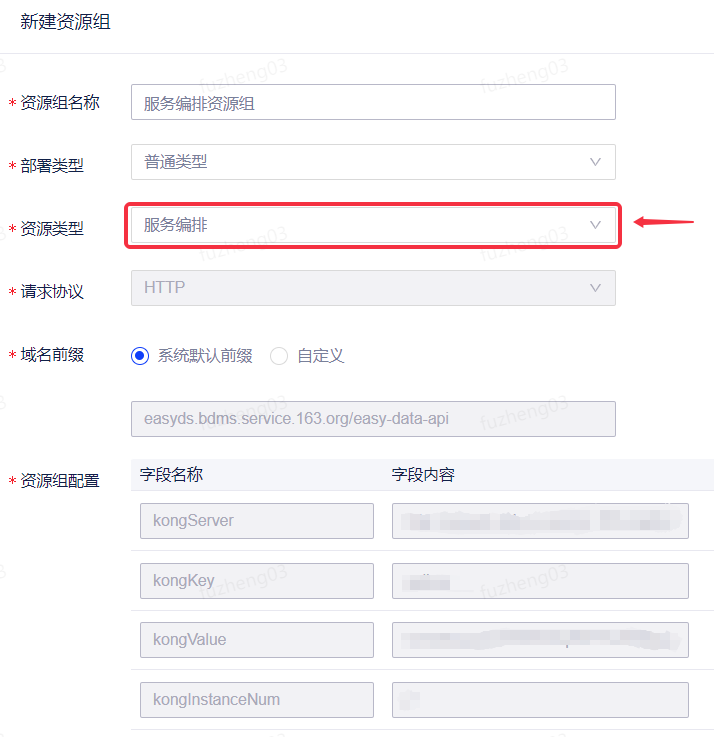
功能入口
在数据服务页面,点击新建按钮,下拉选择"服务编排"即可进入新建服务编排页面。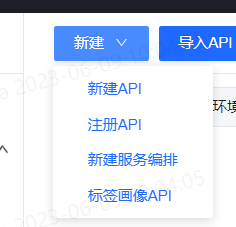
新建服务编排
新建服务编排共包含两个步骤:基础信息和工作流配置。在基础信息配置页面主要完成名称、协议、请求方式、描述等信息的填写;工作流配置页面通过不同节点的组合完成复杂的加工逻辑。
基础信息
服务编排的基础信息配置页面同新建API的页面类似,如下:

| 基本信息 | 描述 |
|---|---|
| 服务编排名称 | 必填。格式要求:1~64个字符,需以中文、字母开头,仅支持中文、字母、数字、"-"、"_"。 |
| API集合 | 选择已创建的API集合,如果未创建,可点击右侧创建集合按钮进行创建。 |
| 服务编排path | 通过集合path和服务编排path生成唯一的请求地址path。 |
| 协议 | 支持HTTP和HTTPS两种协议。 支持HTTPS协议要完成SSL证书配置,为避免无法调用,在使用之前需进行如下准备: 1. 拥有一个HTTPS可控域名且申请SSL证书; 2. 具备可接受外网请求的Nginx服务; 3. 配置SSL证书。 |
| 请求方式 | 支持GET和POST。 1. 若选择GET方式,入参位置为QUERY; 2. 若选择POST方式,入参位置为BODY。 |
| 返回类型 | JSON或者XML |
| 超时时间 | 默认10000ms。支持自定义设置。 |
| 描述 | 服务编排的描述。 |
| API标签 | 可选择或输入标签,最多关联5个标签。 |
| API协助管理者 | 可指定当前API的协助管理者,等同于创建人,拥有对API的所有操作权限。 |
| 传输加密 | 可选择是否开启传输加密,支持SM2+AES加密算法 |
| apiToken鉴权 | API调用支持apiToken和应用两种鉴权方式。如果打开,可通过apiToken调用API,只需要在header中添加字段apiToken、appKey和version即可,适用于报表、数据大屏等安全性要求不高的使用场景。具体使用方法可参考SDK下载中示例说明文件。 |
| 选择资源组 | 服务编排运行时使用的查询服务资源组,需事先在配置管理页面创建服务编排资源组。 |
工作流配置
在工作流配置页面可通过拖动左侧节点至画布上进行开发逻辑的编辑。画布默认节点为开始节点和结束节点,左侧节点有三种分别是:Python节点、API节点、条件节点和UDF节点。
- 开始节点
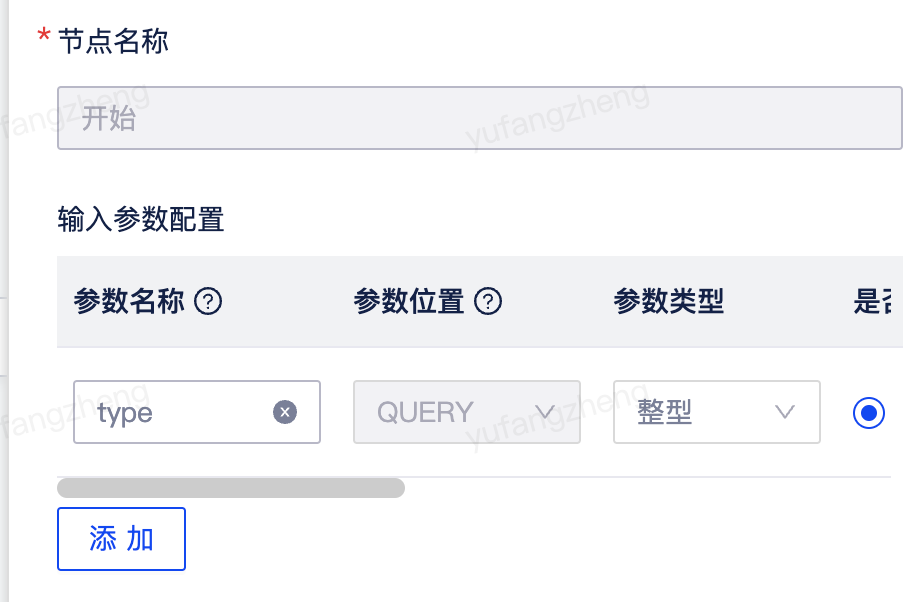
右键点击开始节点,选择编辑按钮可对开始节点进行编辑。节点配置包括node ID、节点名称以及参数输入配置。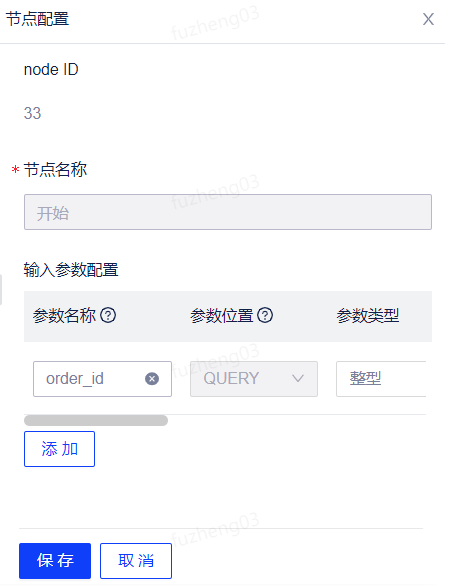
|
说明: 1.node ID需要在执行运行后自动生成,每个节点的node ID唯一; 2.节点名称默认为开始,在开始节点中不允许修改; 3.输入参数配置根据下游节点的输入参数进行配置。 |
结束节点
右键结束节点,选择编辑按钮可对结束节点进行编辑。节点配置包括node ID、节点名称以及输出参数配置。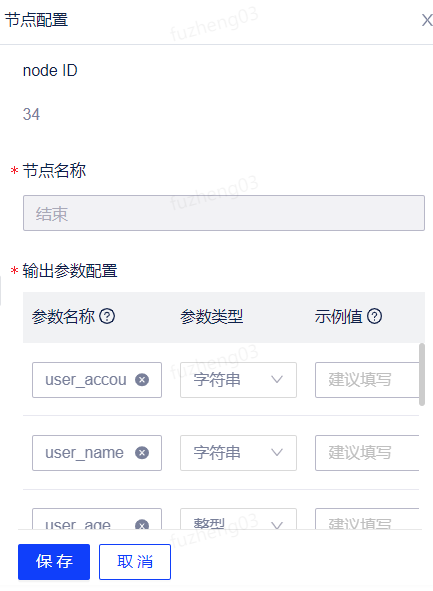
结束节点支持系统填充返回参数功能,且仅支持填充上游为API类型的节点数据。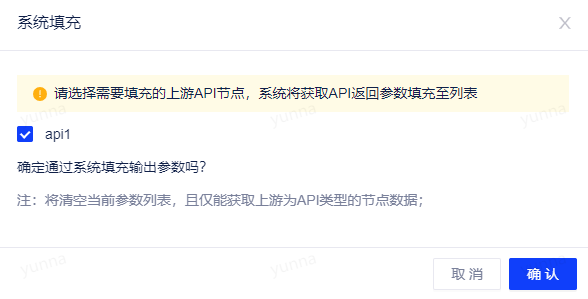
说明:
1.节点名称默认为结束,在结束节点中不允许修改;
2.输出参数配置根据最后想要的输出结果进行配置。Python节点
将Python节点拖入至画布,右键节点选择编辑按钮可对节点进行编辑。节点配置包括node ID、节点名称、描述以及代码编辑区。
此处,节点名称支持自定义,可根据实际情况填写。代码编辑区默认代码如下:import json,time,random,pickle,re,math def handle(inputJson): # 入参字典 input = json.loads(inputJson) # 统一用output字典封装返回结果 output = {} #自定义代码区 #XXXXXXX #XXXXXXX #XXXXXXX return json.dumps(output)从代码可知,对于Python节点的要求输入和输出都是json格式。
此外,Python节点支持测试功能,在编辑页面点击测试节点按钮,输入样例,即可进行代码测试,也可右键节点选择测试功能进行测试。
API节点
将API节点拖入至画布,右键节点选择编辑按钮可对节点进行编辑。节点配置包括node ID、节点名称、选择API、描述以及参数信息。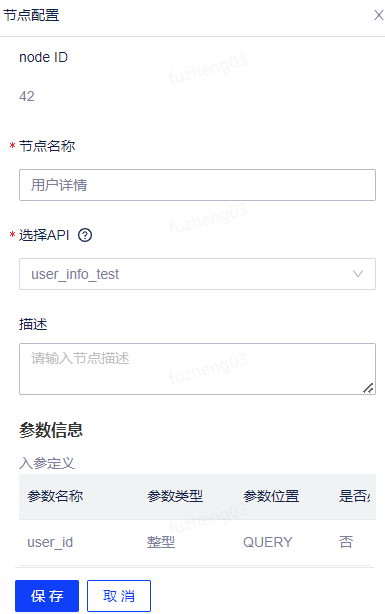
其中,节点名称支持自定义输入。选择API需要绑定当前服务编排创建者具有发布和下线权限且处于已发布状态的API。选择了需要的API后,会自动在参数信息中填入入参定义和后端返回参数。条件节点
将条件节点拖入至画布,右键节点选择编辑按钮可对节点进行编辑。节点配置包括node ID、节点名称、描述、代码编辑区以及条件配置。条件节点会根据输出结果结合执行条件执行下游节点,例如id>20执行下游节点a,则在节点a对应输入框中填写"id >20"。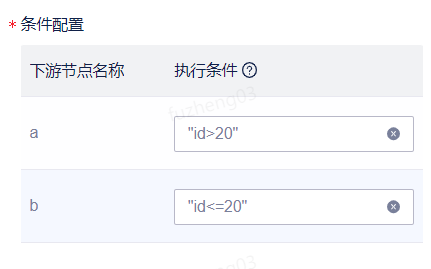
UDF节点
服务编排支持UDF节点,可通过上传jar包或者选择UDF Studio中的函数处理更为复杂的编排业务逻辑。将UDF节点拖入至画布,右键节点选择编辑按钮可对节点进行编辑。节点配置包括节点名称、描述以及上传Jar包。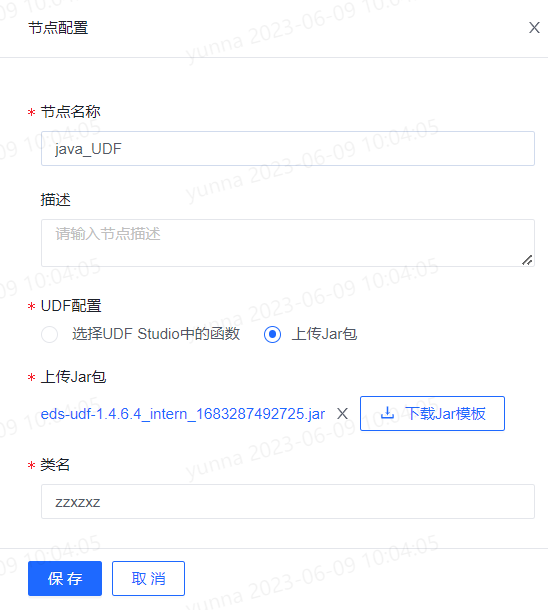
当所有节点配置完成后,可点击画布上方的 全流程运行按钮,进行服务编排的测试,测试通过后点击完成并退出按钮,即可完成配置。
全流程运行按钮,进行服务编排的测试,测试通过后点击完成并退出按钮,即可完成配置。
编排API的其它功能
同API一样,服务编排也支持发布、下线、测试、复制、锁定、编排升级以及版本历史操作。点击右侧更多,可选择查看相应的功能。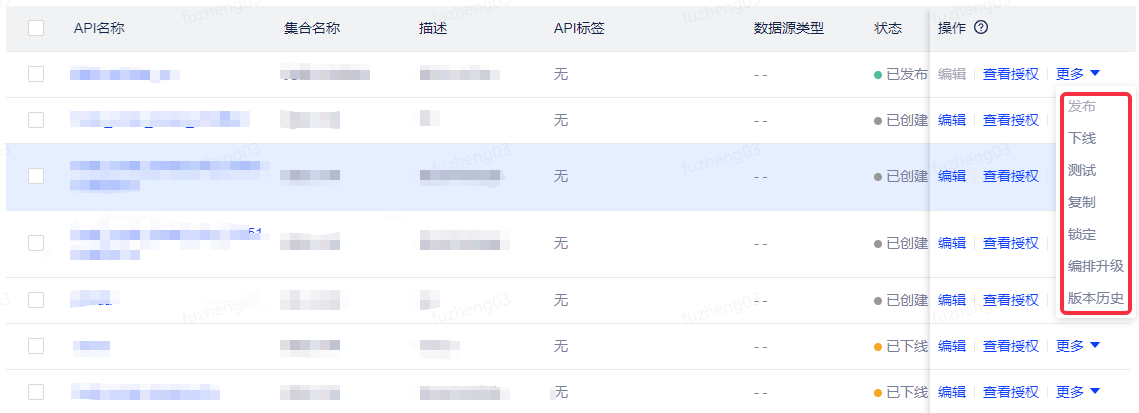
复制
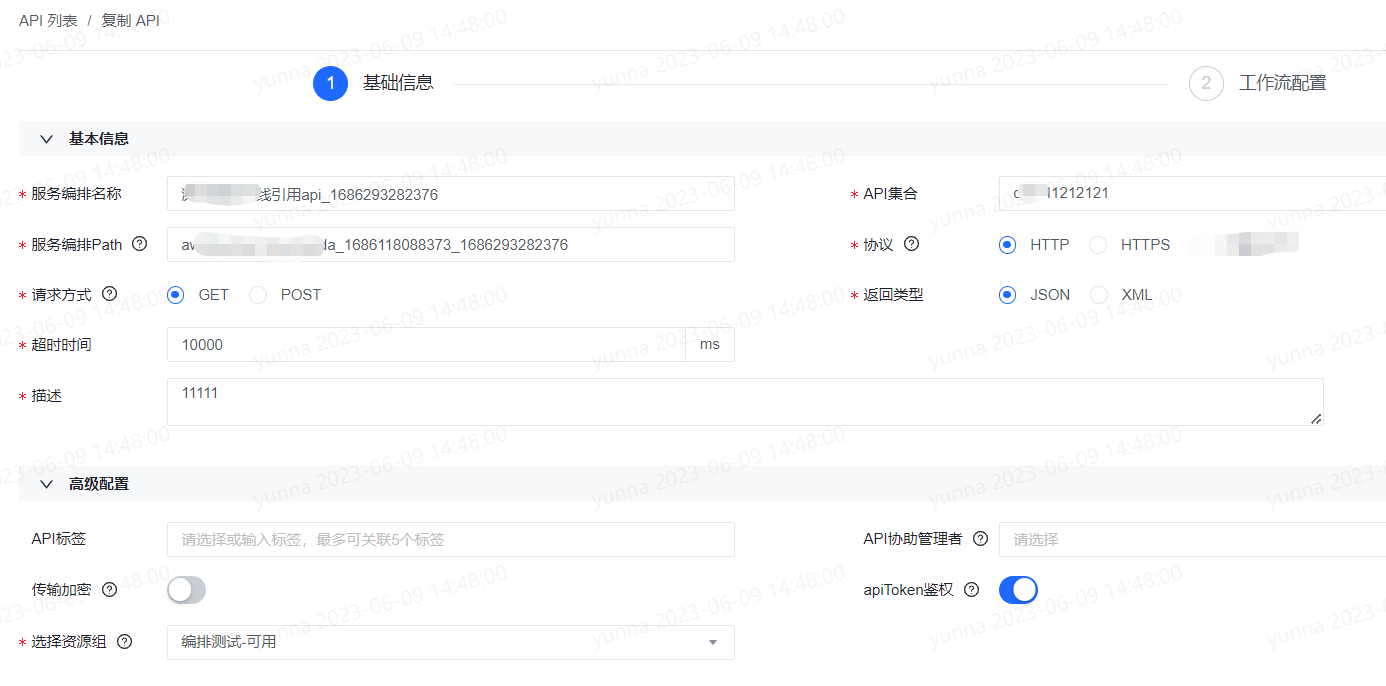
以复制功能为例,点击复制,则会进入复制服务编排页面,在名称和PATH增加时间戳后缀。
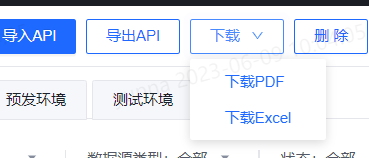
下载
此外,服务编排支持下载功能,支持下载PDF和下载Excel。
在线升级
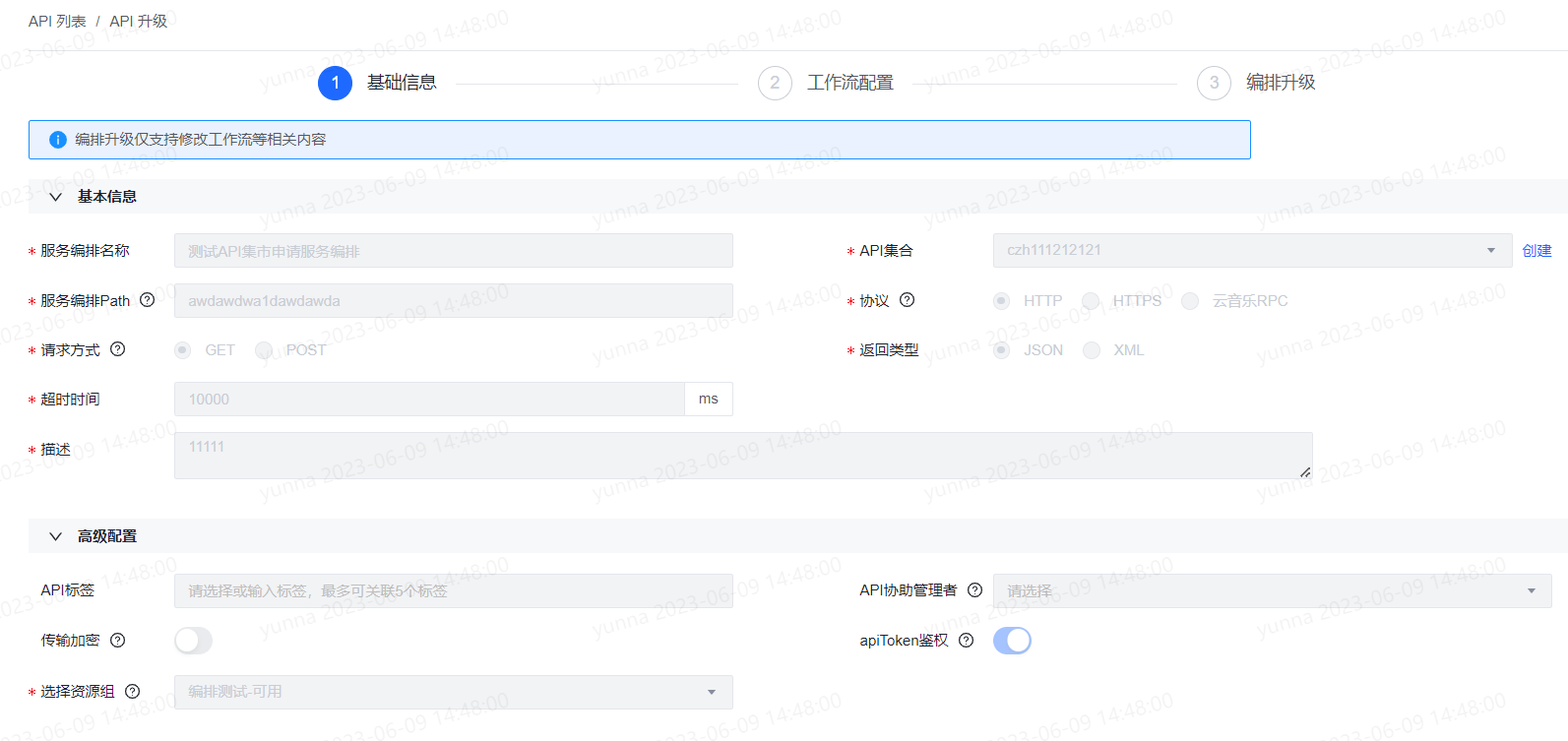
服务编排还支持在线升级操作,共包括三个步骤:
首先,服务编排在线升级的第一步不允许修改基本信息;
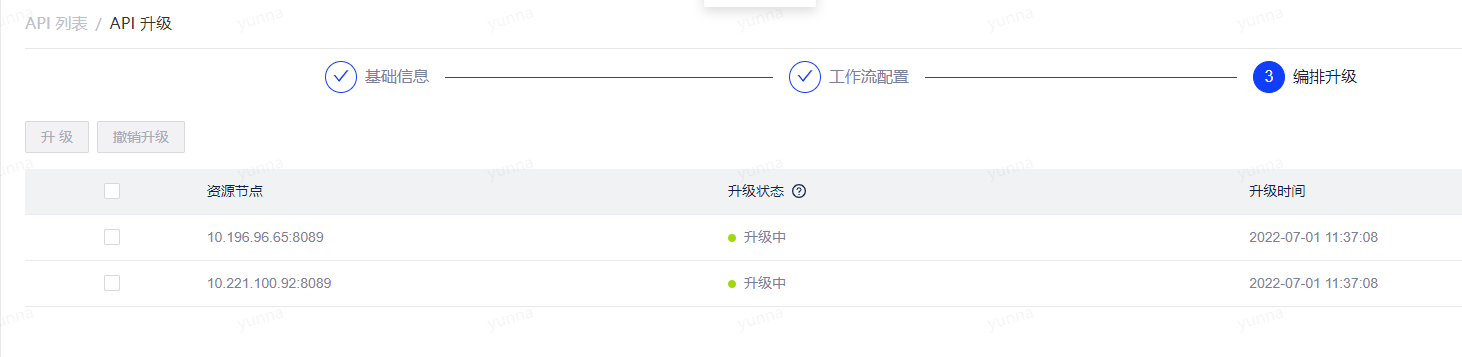
第二步在工作流配置页面,只有当整个工作流运行成功才可进入编排升级,第二步支持放弃并退出;
- 第三步可针对编排的实例节点进行升级,支持放弃并退出,只有所有节点均升级成功,表示编排升级完成并可以退出。
版本历史
服务编排支持版本历史的管理,对已发布的服务编排重新下线进行编辑,编辑完成后再发布会产生新的版本,或者编排升级成功之后也会产生新的版本。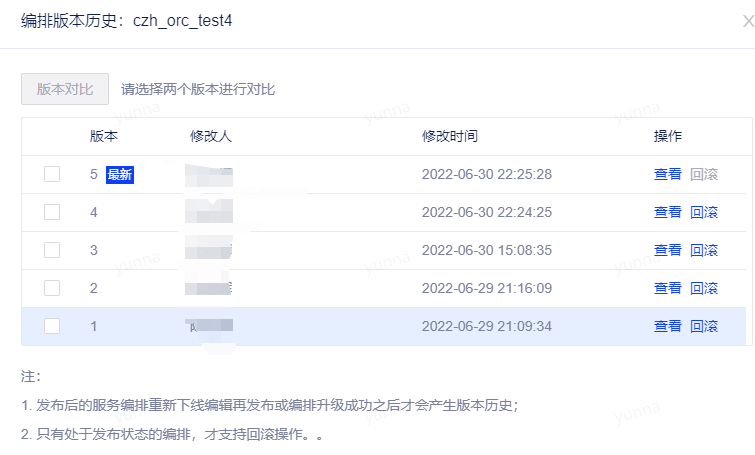
处于发布状态的编排支持回滚操作。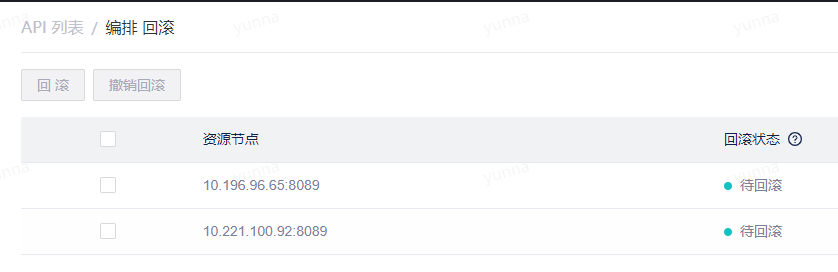
此外还可以通过选择两个不同的版本进行版本对比操作,在对比过程中,分组下有一项信息不一致,则分组名称会被标红。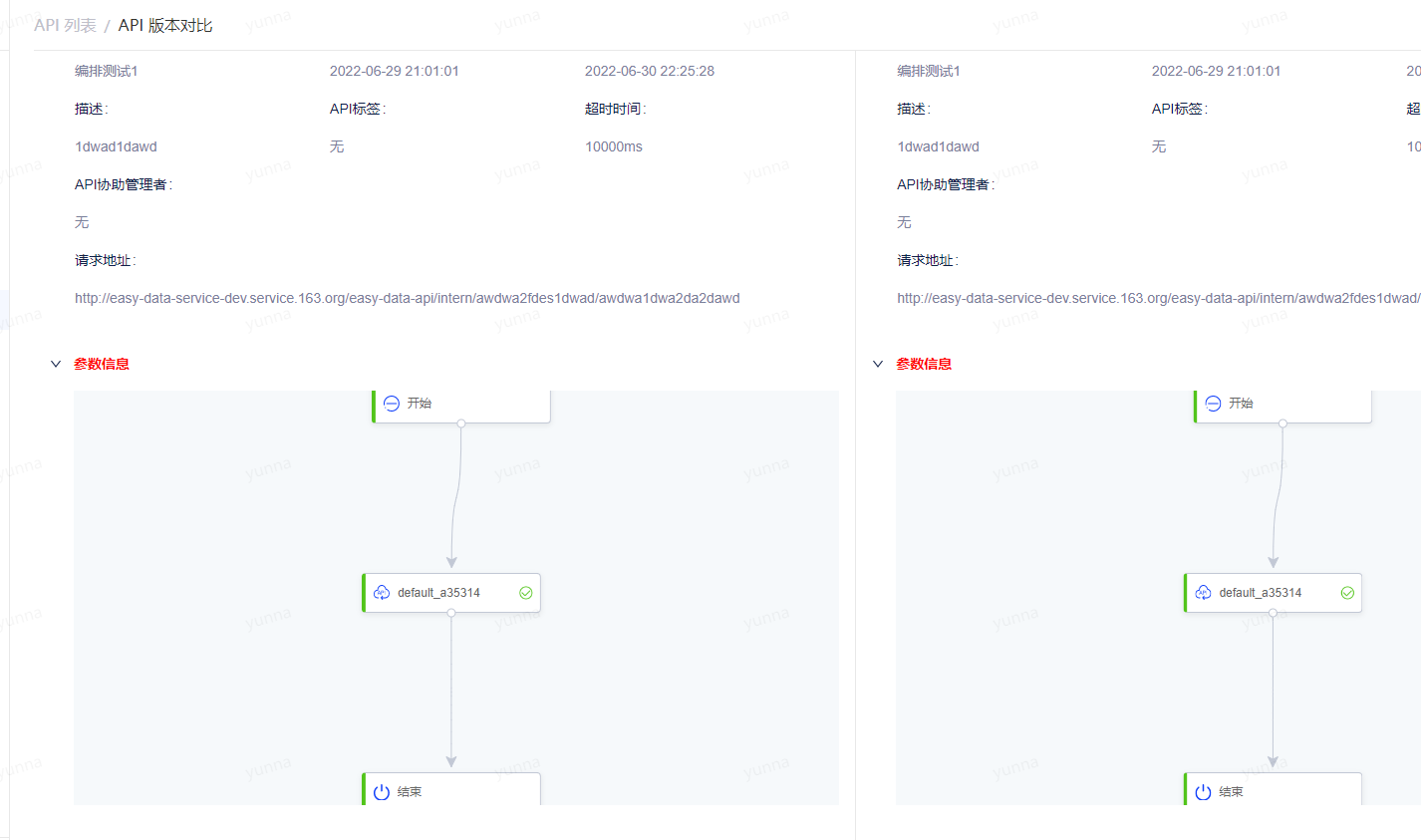
服务编排工作流基本规则
- 开始节点可有多条输出;
- API上游不可再为API节点;
- API上游若为条件节点,则条件节点上游不可再为API节点;
- 条件节点上游不可再为条件节点,且上游仅能有一个节点;
- 结束节点上游不可为开始和条件节点;
- 不允许发生自环;
- 画布中不允许存在游离节点。
节点说明
开始节点
开始节点为编排工作流的唯一输入节点,在该节点可配置整个工作流的入参定义。
结束节点
结束节点为编排工作流的唯一输出节点,在该节点可配置整个工作流的返回参数定义。
需要注意的是,服务编排的输出结构体中,必须有查询结果集列表,统一放在名为data的字段下。而结束节点配置的返回参数定义,实际上是定义了返回结果集列表中每个元素的字段,如下:
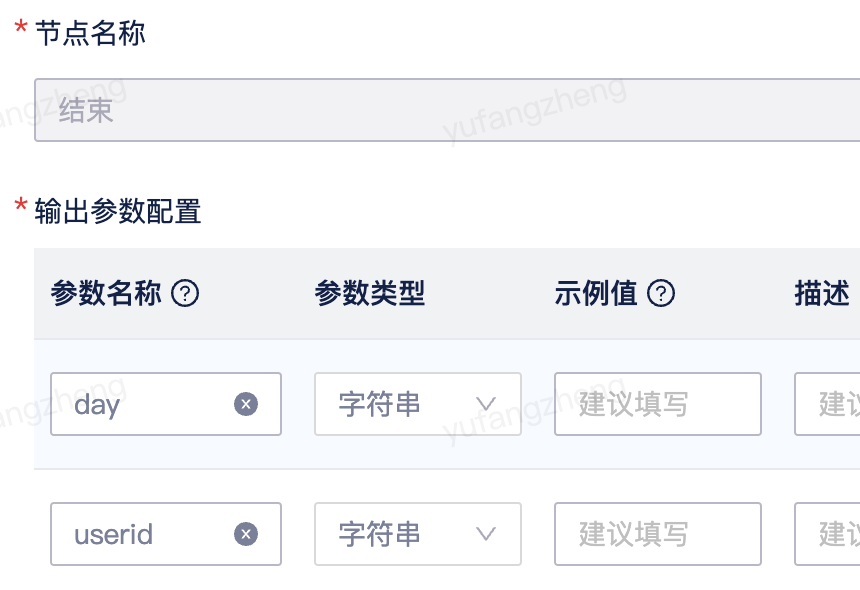
结束节点定义了day和userid两个返回字段,结果集列表输出为:
"data":[{"day":"2022-01-14 00:00:00","userid":"25"},{"day":"2022-01-14 00:00:00","userid":"26"}]那么在服务编排返回时,会输出如下返回结构:
{
"reqId":"09d81294cdfb44f6996e4583916d162b" //请求id,返回结构默认字段
"code":0 //返回状态码,正常为0,返回结构默认字段
"cost":57 //接口响应时间,返回结构默认字段
"message":"success" //接口返回描述信息,返回结构默认字段
//外层这个data是接口返回结构默认字段,包含了查询结果的所有信息
"data":{
"result_num":2, //查询结果数量,非必须返回字段
//内层这个data代表结果集列表字段,该字段对应是查询结果集返回列表,为必须返回的字段
"data":[
{"day":"2022-01-14 00:00:00","userid":"25"},
{"day":"2022-01-14 00:00:00","userid":"26"}
]
},
}API节点
api节点提供对数据服务原子api的调用,每个api节点关联一个已发布的数据服务原子api。
脚本节点
脚本节点提供python脚本的执行,提供用户完成一些定制化的取数逻辑,需在配置时自行编写python脚本。
脚本节点提供python编辑区域以及初始化的代码块,用户需在自定义代码区实现自定义的逻辑。
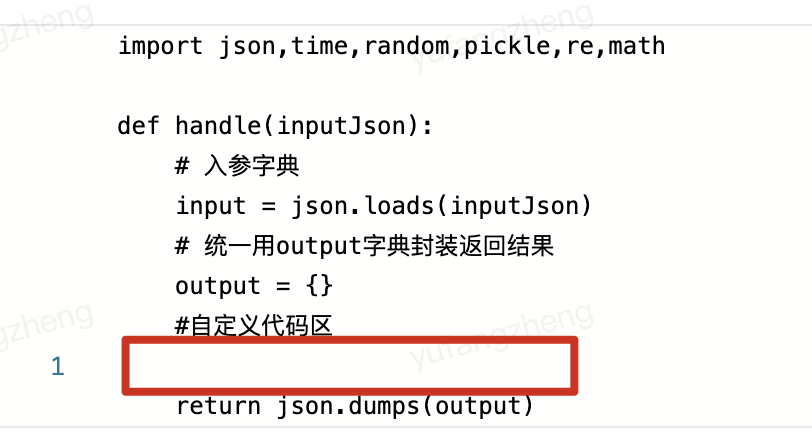
| 注意事项:脚本节点的脚本输入为json,若脚本节点上游只有一个输入节点,则该json即为上游节点的输出;若脚本节点上游有多个输入节点,则json会按照上游节点的id、对应输出结果按key-value形式组成,类似于:{"node1":{...}, "node2":{...},"node3":{...}}。 |
条件节点
条件节点的功能是对上游的输出结果进行条件表达式匹配,根据匹配结果决定走下游具体某些分支。
使用方式:可编写python脚本对上游输入进行解析;对于下游每一个相邻节点,都需要配置条件表达式;python脚本的输出与每个相邻节点的条件表达式进行匹配,根据匹配结果决定是否走下游某些分支。
UDF节点
对于不熟悉python的用户,udf节点提供了java语法的支持,用户需按照udf模板规范,继承相关interface,自行编写取数逻辑并打包上传至udf节点即可执行。
demo样例
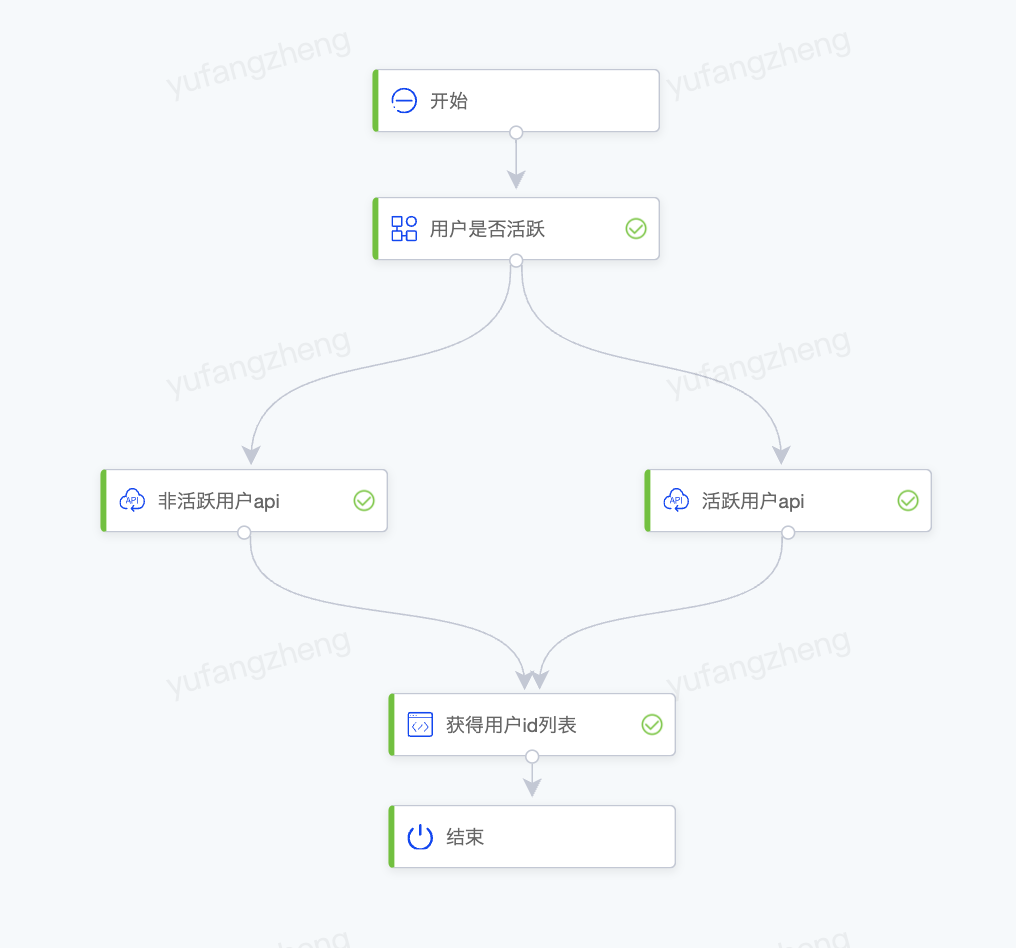
如下是获取用户id信息场景(非活跃用户存储在HBase数据源,活跃用户存储在Redis数据源),根据传入用户的类型,去不同原子api获取用户信息,并得到用户id列表,从上到下的节点类型为:开始节点 -> 用户是否活跃(条件节点)-> 非活跃用户信息api、活跃用户信息api (api节点)-> 获得用户id列表(python脚本节点)。
开始节点配置
条件节点配置

脚本节点python代码
import json,time,random,pickle,re,math
def handle(inputJson):
# 入参字典
input = json.loads(inputJson)
# 统一用output字典封装返回结果
output = {}
#自定义代码区
#获取上游节点1(id为'50840054640528')的返回参数dict
dict1 = input['50840054640528']
#获取上游节点2(id为'8895801755048528')的返回参数dict
dict2 = input['8895801755048528']
dataList = []
dataListOfDict1 = []
dataListOfDict2 = []
#获得每个上游节点的结果集列表,key为'data'
if 'data' in dict1:
dataListOfDict1 = dict1['data']
if 'data' in dict2:
dataListOfDict2 = dict2['data']
#获得每个用户的id
for d in dataListOfDict1:
data = {}
data['userid'] = d['userid']
dataList.append(data)
for d in dataListOfDict2:
data = {}
data['userid'] = d['userid']
dataList.append(data)
#返回结构必须要有'data'字段,作为结果集列表放入输出的dict
output['data'] = dataList
return json.dumps(output)工作流测试结果
{
"code":0,
"cost":149,
"data":{
"data":[
{"userid":"25"},
{"userid":"26"}
]
},
"message":"success",
"reqId":"f5339134df104afaac665ba8564d498a"
}