搜表
进入数据查询页面后,默认搜索类型为搜表,支持通过表名、表描述搜索当前项目组下的hive表,通过表名搜索当前项目组下登记的数据源下的HBase、Kudu、Kafka流表、RocketMQ流表、MySQL、Oracle、Vertica、DM、Doris、TiDB、StarRocks、ClickHouse以及Greenplum。在输入内容时,支持自动推荐表。
如下图,为搜索表的页面: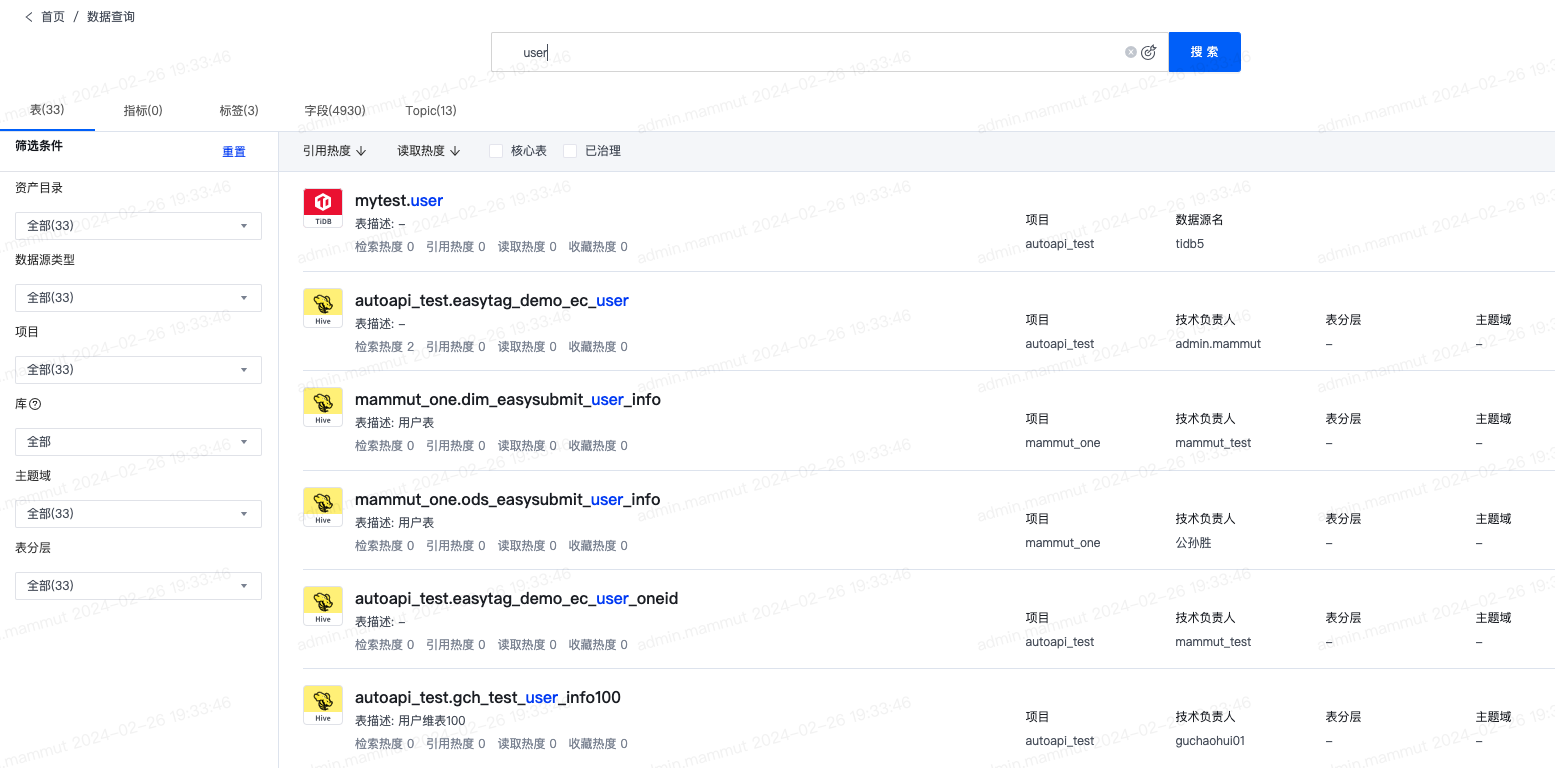
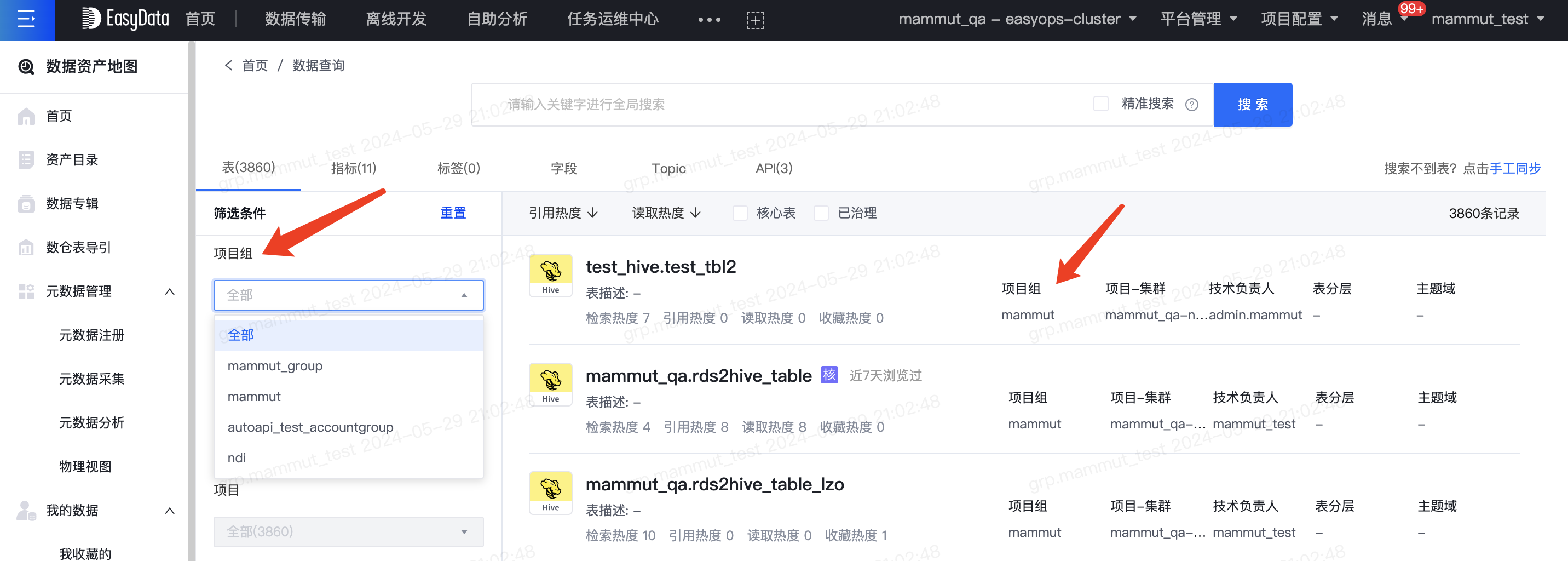
对检索结果支持二次筛选,可按照源类型(Hive、MySQL、DM、Vertica、ClickHouse、Oracle、GaussDB、Greenplum、OceanBase、Doris、StarRocks、HBase、Kudu、Kafka流表、RocketMQ流表)、项目、库、主题域、表分层、核心表标签的过滤,支持按照引用热度和读取热度排序。
如下图,为搜索结果页: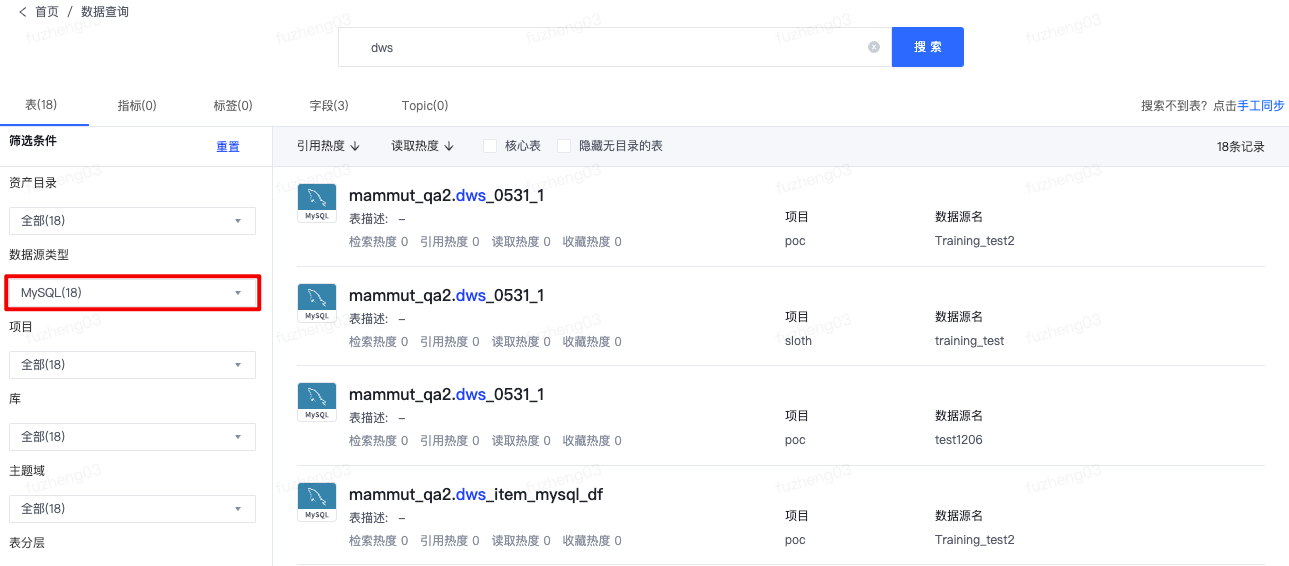
点击搜索结果页的表名,即可跳转至对应的表详情页。
在搜索框输入关键字后,系统会提供推荐列表,推荐列表中会展示库表名、表描述、所属项目信息,如下图所示:
开启/关闭精准匹配
当同一关键字可能搜出较多结果时,对用户选择形成干扰。故系统支持是否精准匹配的设置项,可灵活开启,方便精确定位自己想要的数据。默认未开启,即为模糊匹配。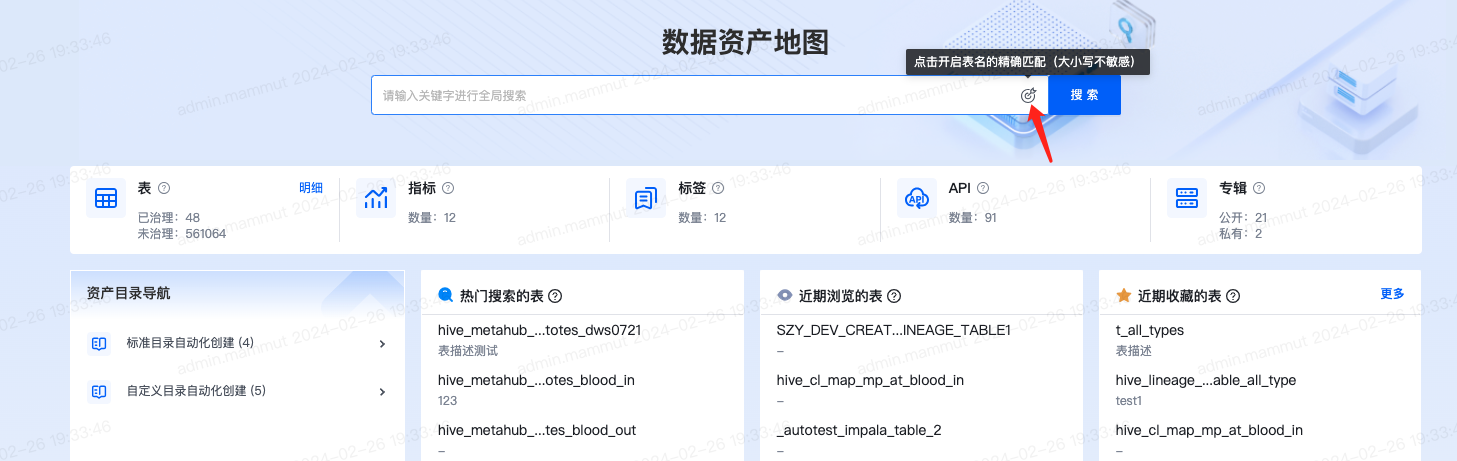
手工同步
当表新建后可能由于网络延迟或者底层偶发问题导致表没有及时同步到ES索引中,以致用户可能在地图搜索不到表,可通过“手工同步”进行手动同步。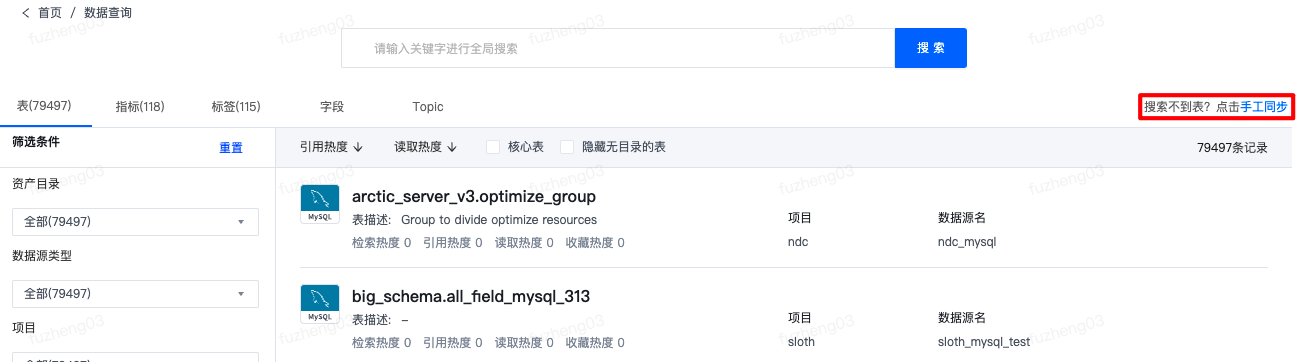
点击“手工同步”后可在弹框中输入数据源类型、数据源、库/Schema、表物理名称。
| 说明: 对于历史存量用户,地图支持搜索所有已登记的数据源下的库表;对于未来新部署地图的用户来说,地图默认仅支持搜索hive表,若需要支持搜索其他登记的MySQL、Oracle等数据源表,需要先创建采集任务将需要检索的库表采集到平台元数据中心后,才能在地图检索这些已采集的库表。地图检索的元数据需要先采集,才能检索,避免无效的、敏感的数据被检索出来。该功能可以通过后台开关控制,详情可咨询技术支持。 |
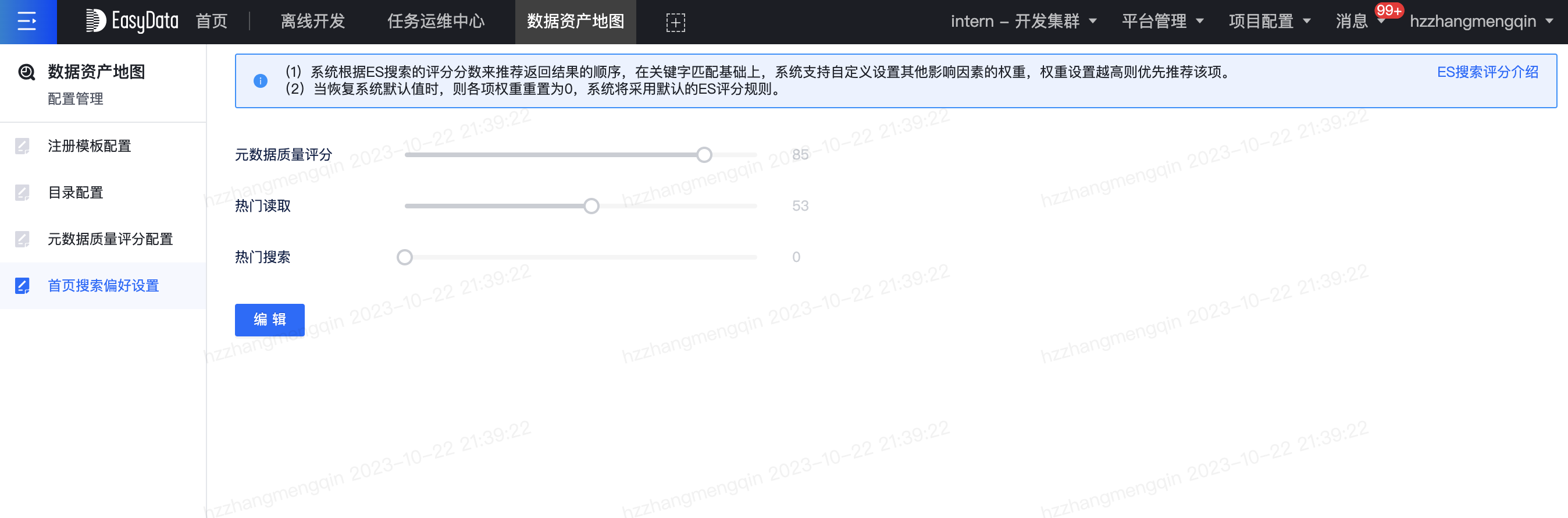
搜索偏好设置
地图首页搜索时,用户希望能够基于关键字匹配,并且优先推荐热门读取、热门搜索或者元数据质量评分高的数据。故本次平台在ES分词检索的基础上,提供了搜索偏好设置的功能,管理员可调整各项权重因子,优化搜索推荐的功能和体验。
默认仅项目组负责人和项目组管理员可以设置搜索偏好,其他人员需要在安全中心授权后才能操作。进入配置管理页,点击搜索偏好设置菜单,设置并保存后立即生效,可在首页搜索查看返回结果的推荐顺序。搜索偏好设置页如下所示:
超级项目组
背景介绍:
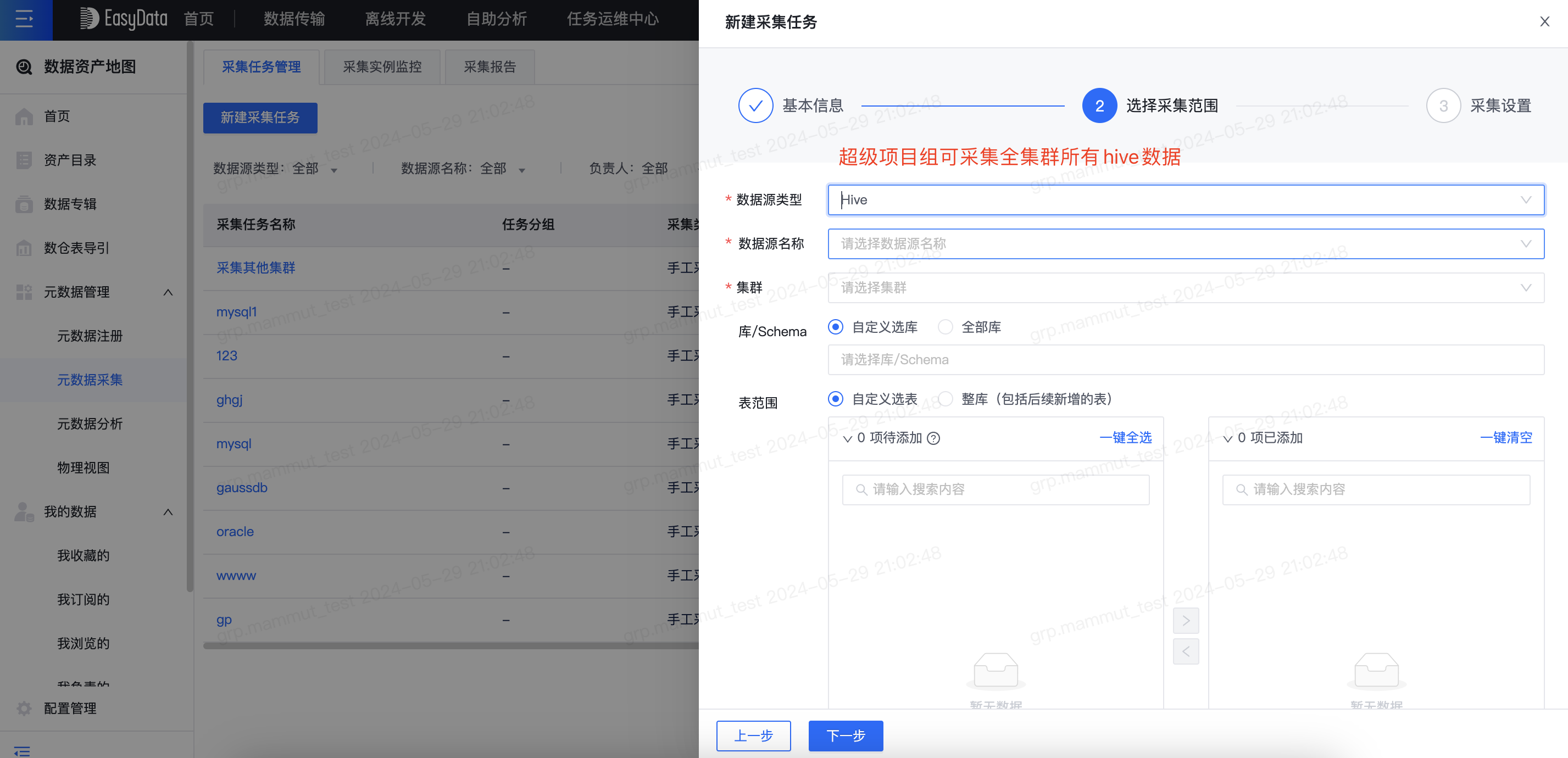
平台之前的架构是以项目组为最大隔离粒度来管理数据资产,例如网易云音乐、网易传媒等事业部各自作为一个独立的项目组,业务上完全隔离互不干扰。但对于一些集团性企业例如通威股份、兴合集团等,其企业架构是一个集团母公司和多个子公司,虽然各自可作为一个独立项目组来运转,但是集团母公司需要能查看所有子公司数据,此时项目组隔离导致无法满足。基于这种场景,需要有一个超级项目组来代表集团母公司角色,子公司都是普通项目组,母公司超级项目组能够打破项目组隔离限制,可搜索、治理、浏览全部hive集群数据。
功能说明:
超级项目组可在「平台管理-项目组管理」模块中指定,下面具体介绍超级项目组所具备的能力:
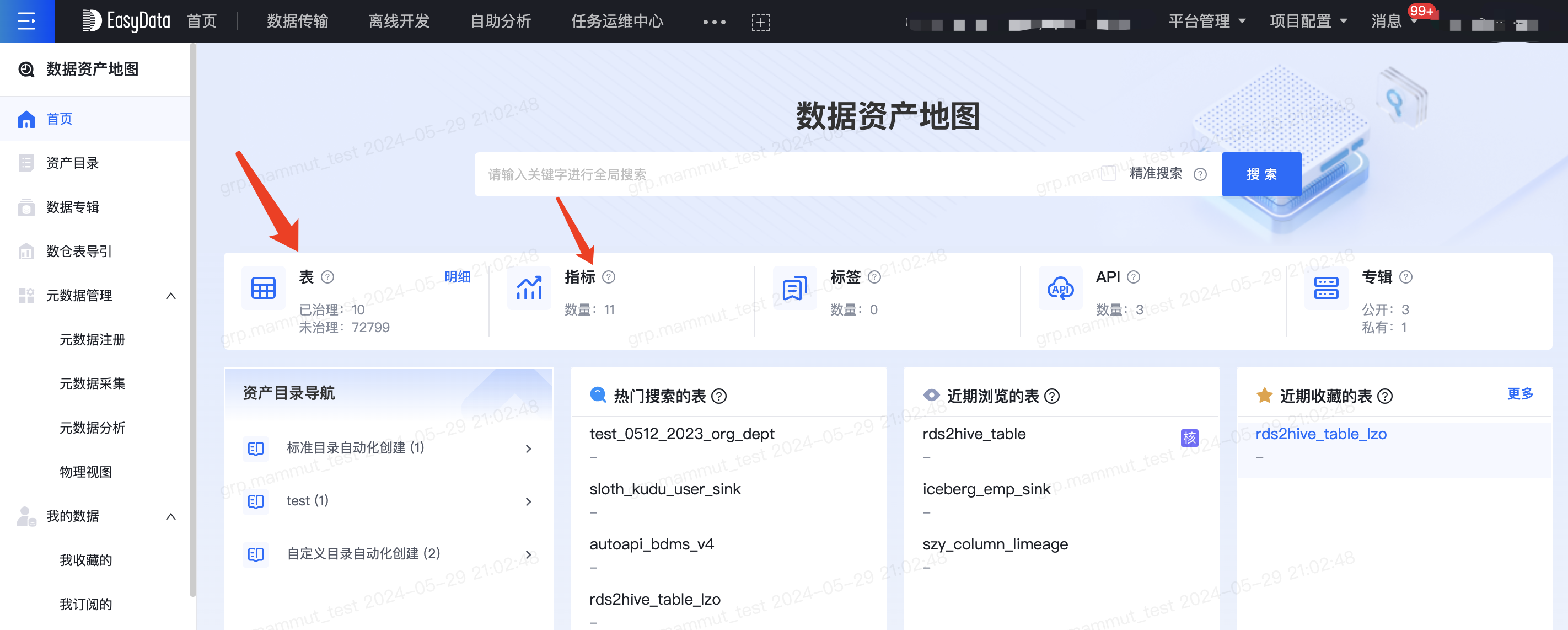
- 首页支持统计所有集群已治理、未治理的表数量
- 首页支持统计所有项目组已发布的指标总数
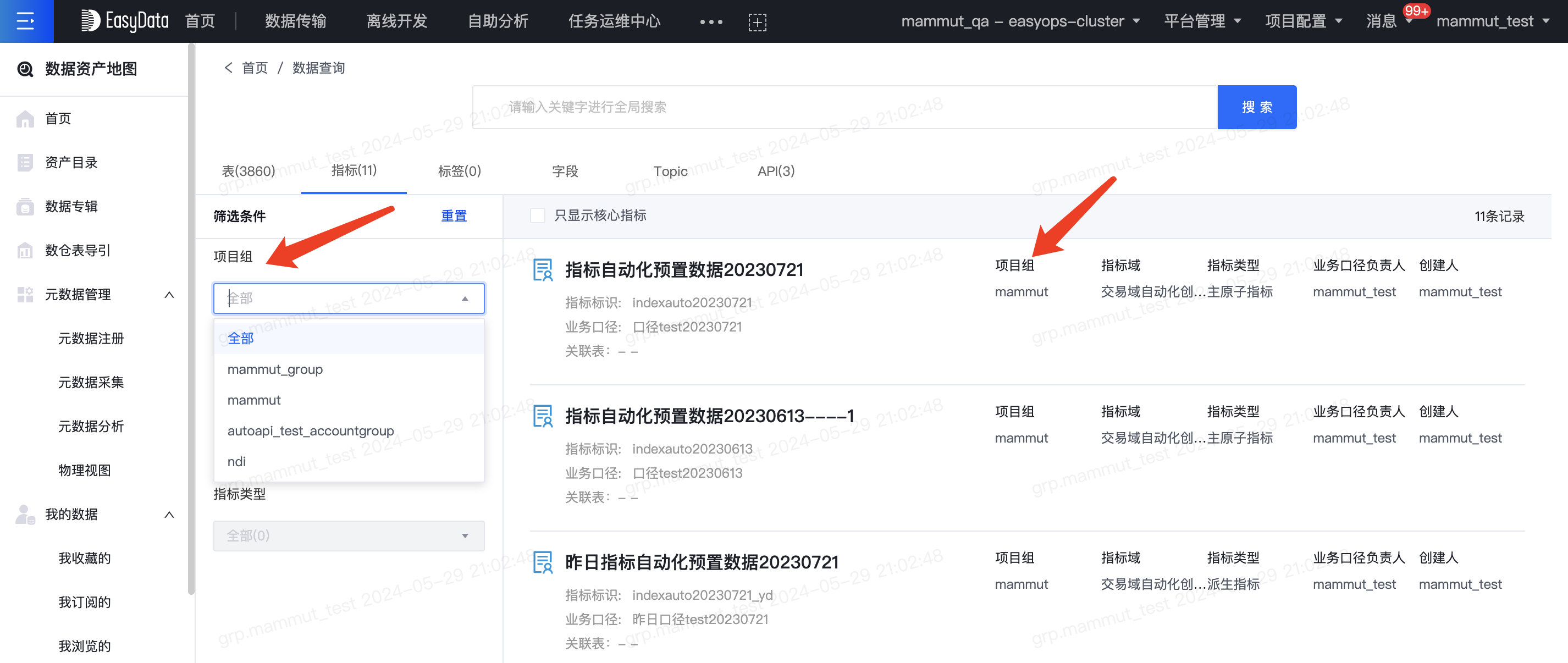
- 支持搜索和浏览所有项目组所有集群的hive表,支持按项目组筛选
- 支持搜索和浏览所有项目组已发布的指标,支持按项目组筛选
- 超级项目组支持对所有hive集群元数据进行采集和治理,普通项目组仅支持采集和治理有权限的集群的数据