SQL
更新时间: 2025-05-20 15:45:50
SQL节点用来进行数仓表的逻辑开发,如果数据底座为NDH,则支持Hive、Spark、Impala执行引擎。如果底座为TDH,则支持Inceptor、ArgoDB等(具体取决于TDH底座下客户环境的配置)。
鼠标双击SQL节点,可进入节点详情页。在详情页中左侧是库表信息和函数列表。支持查询当前项目-集群下的库表;右侧是编辑区,包括SQL编辑器和其他设置。
SQL编辑器
鼠标双击SQL节点,在页面右侧为SQL编辑器,支持SQL编写、运行等。左侧为库表信息、函数列表。
库表信息中,目前展示逻辑为:
1)针对NDH底座,以及对接了安全中心Ranger进行权限管理的CDH底座,则:
- 支持显示项目外自己有权限的库表
- 针对项目内库表,结合现在项目组粒度的“项目内hive类型库表展示控制”开关,开显示项目内所有库表,关显示自己有权限的库,以及有权限的表所属库下所有的表
2)针对TDH底座,以及未对接安全中心Ranger进行权限管理的CDH底座,则:
- 支持显示当前项目下库表,以及其它项目公开给当前项目的库表
在编写SQL语句时,支持库、表、字段、UDF等提醒,也支持相关快捷键操作,具体可点击页面右上角的“编辑器快捷键说明”查看。
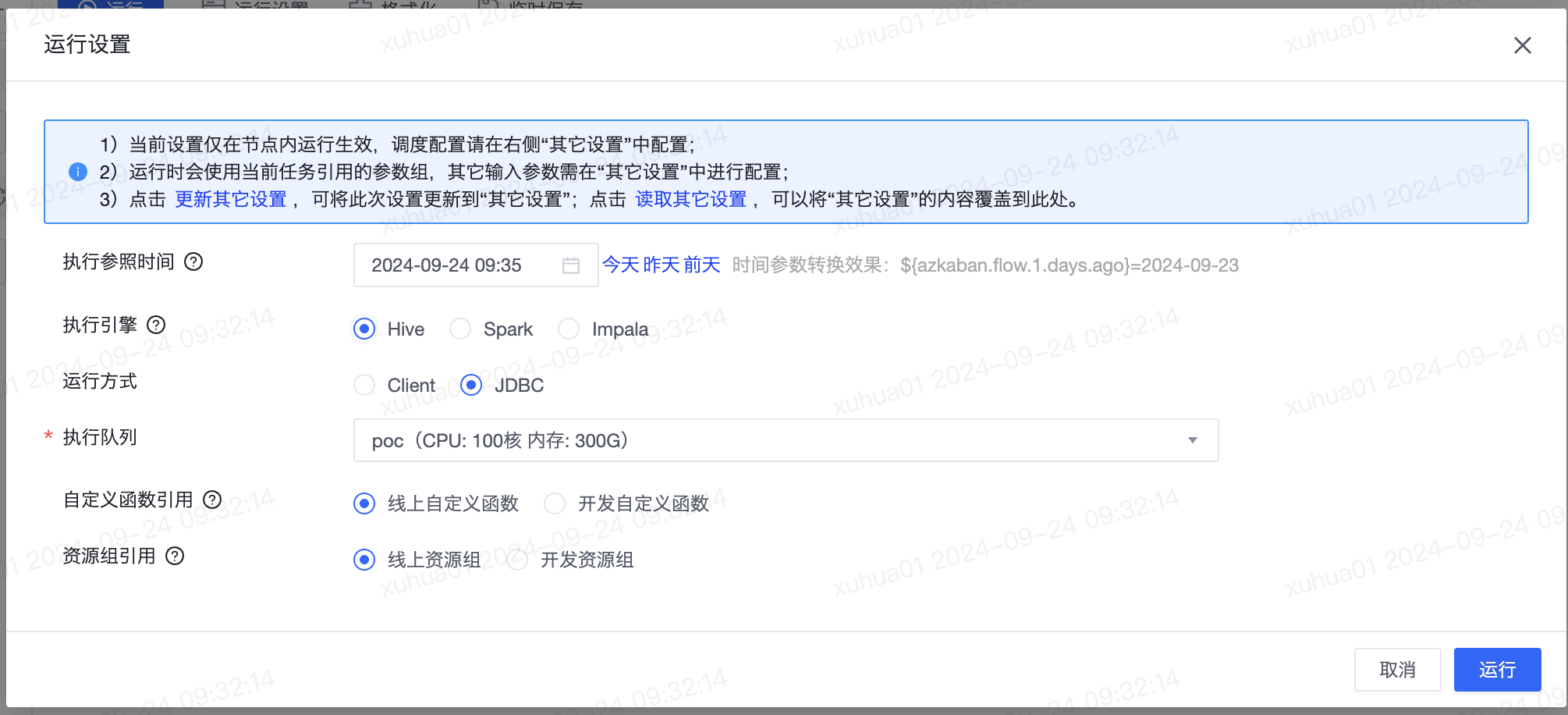
在运行SQL时,支持点击“运行设置”,配置立即执行的配置。
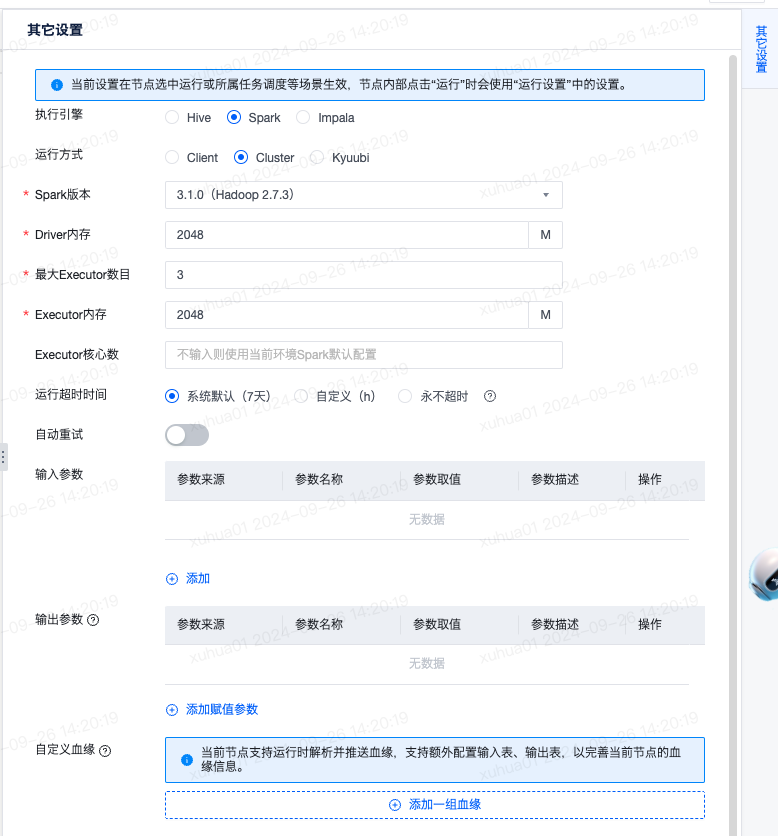
在页面右侧的“其它设置”中,可设置任务线上调度的执行配置。注意,立即执行是在“运行设置”中设计,调度是在“其它设置”中设置。下面,对SQL节点的设置项进行说明:
| 设置项 | 说明 |
|---|---|
| 执行引擎 | 可选择当前平台支持的引擎,包括Hive、Spark、Impala、Inceptor、ArgoDB、Presto等。 |
| 运行方式 | 当执行引擎为Hive和Spark时,支持配置该项。其中Hive的支持Client和JDBC 2种方式,Spark的支持Client、Cluster、Kyuubi等3种。 |
其它配置项,如运行超时时间、自动重试、输入参数、输出参数、自定义血缘可在“节点概述”中查看。
UDF引用
在离线开发的SQL节点支持查看和使用UDF Studio模块中的UDF。如果当前使用人员无UDF的权限则可点击需要使用的UDF,选择“申请使用”跳转至UDF Studio页面进行申请;如果当前所使用的UDF有权限则可以直接使用。
UDF使用示例如下,此示例中的UDF主要功能是将“Hello udf:”作为前缀拼接。
SELECT udf_helloUdfStudio(id) FROM mammut_qa.xuhua_testfile_ods1 LIMIT 1;运行后,结果如下图所示,通过UDF函数将“Hello udf studio test:”和id进行拼接。