函数说明
概述
在定义计算指标时,可以使用函数对指标、维度等做各种运算,产品页面如下所示,本次详细介绍各个函数的使用说明。
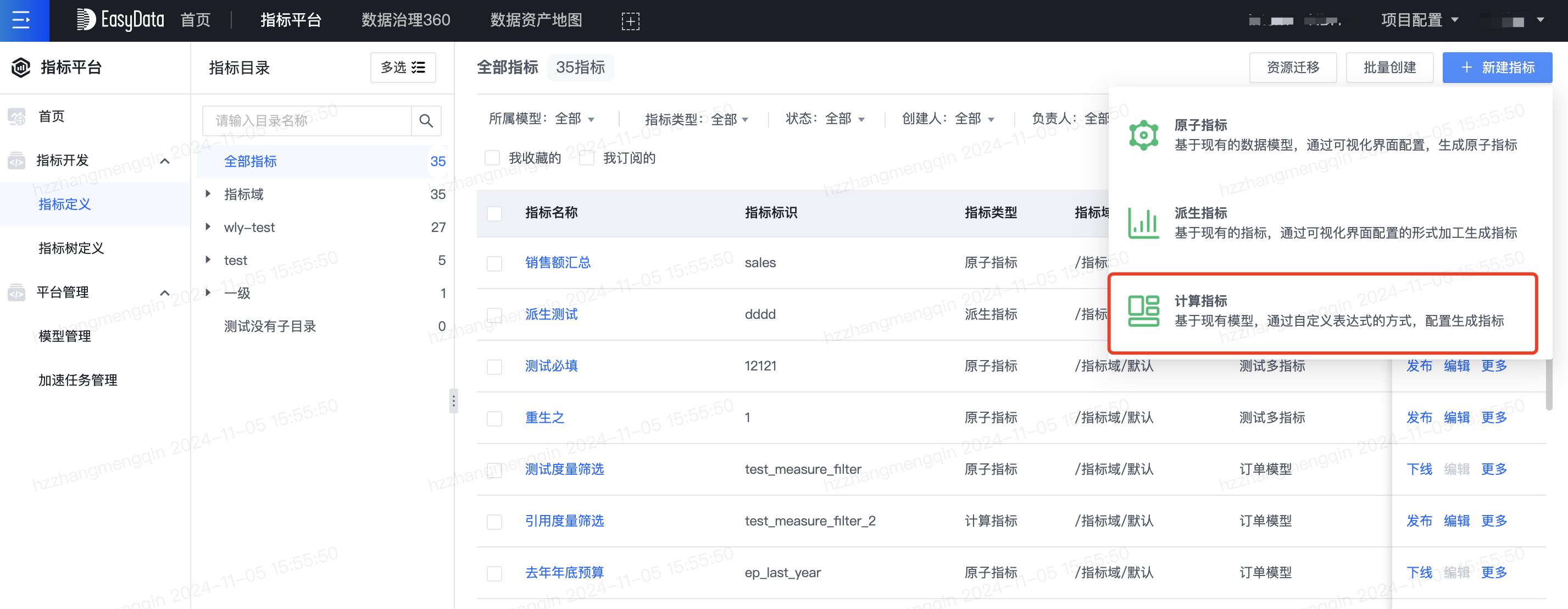
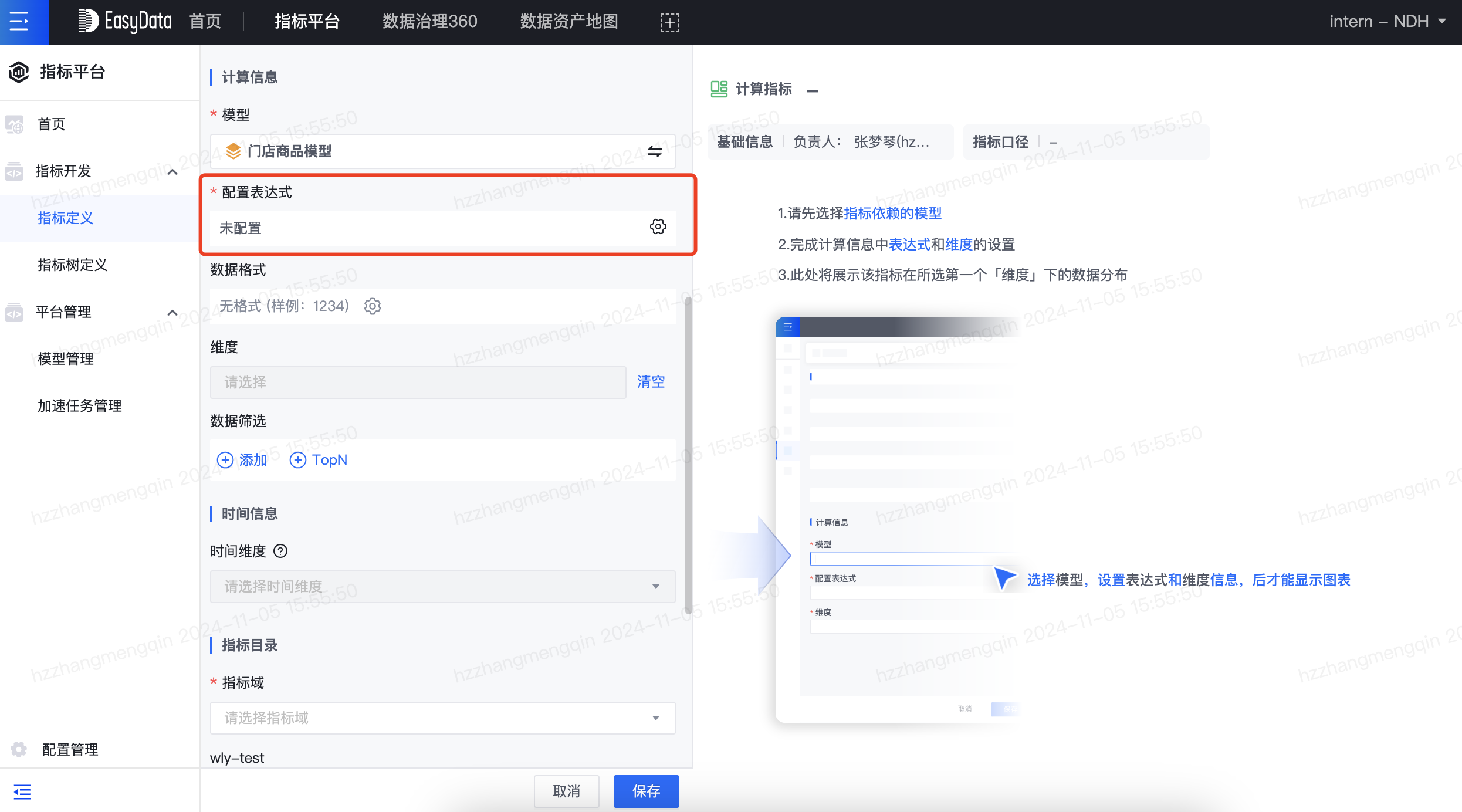
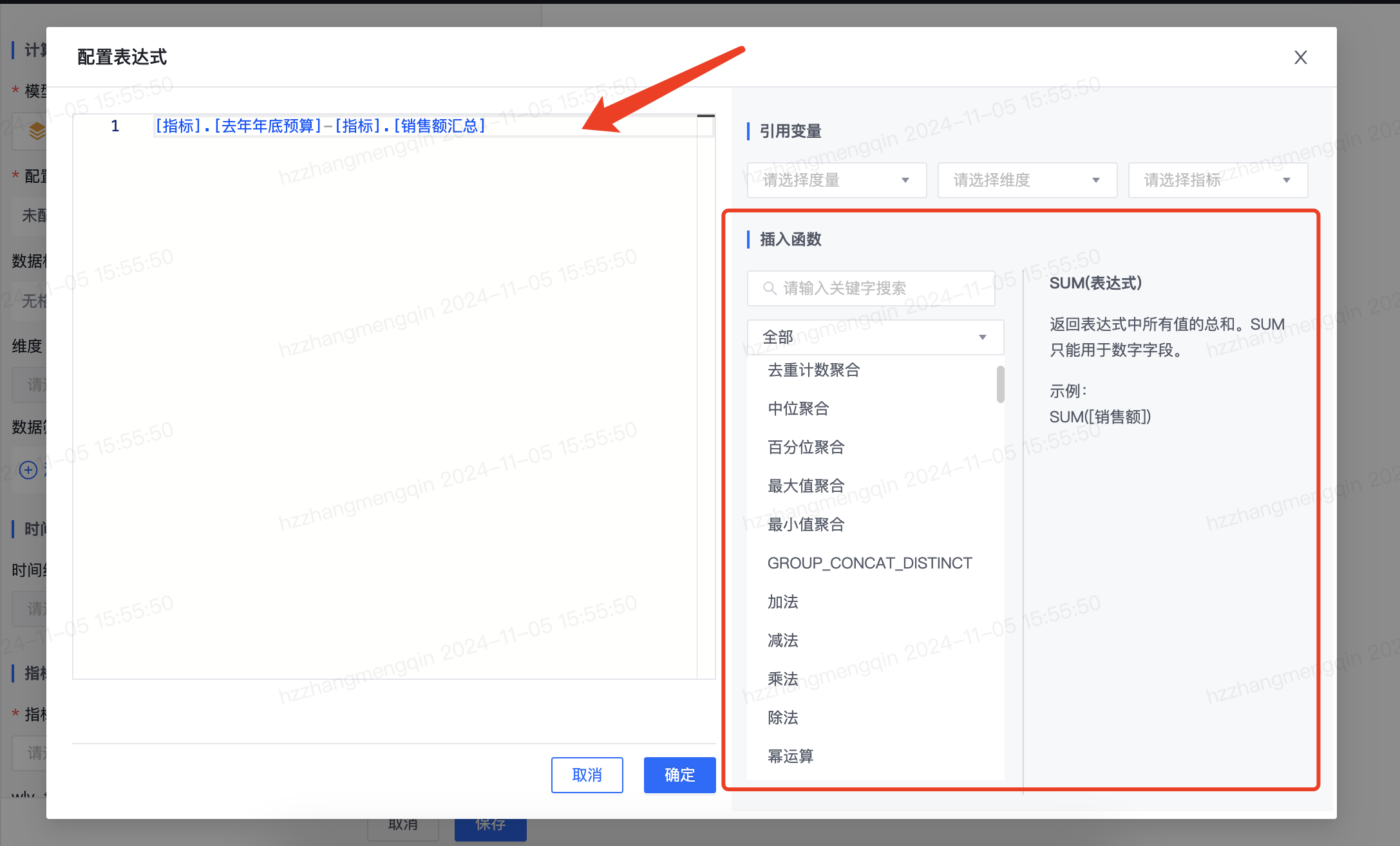
函数详细介绍
聚合函数
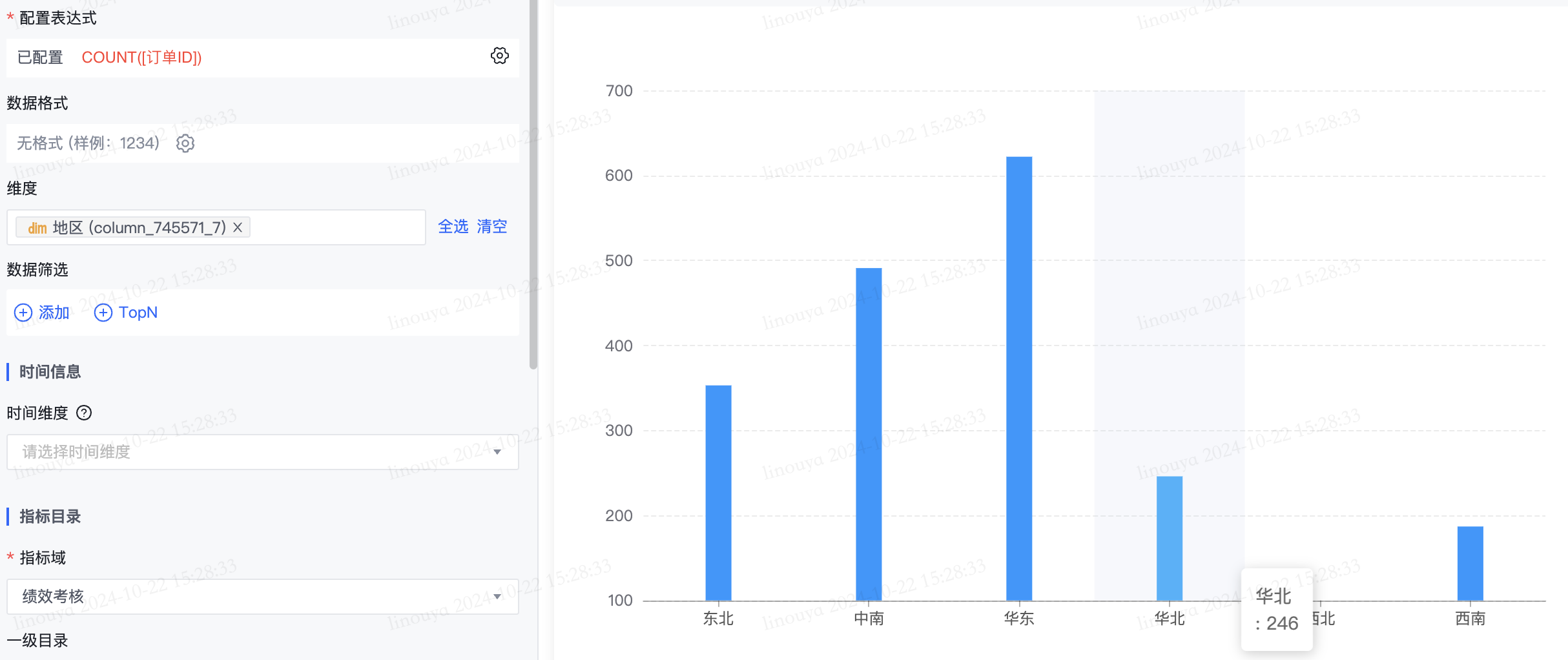
1.计数聚合: COUNT()
- 用途: 返回组中的记录数。不对 NULL 值计数
- 语法: COUNT(表达式)
- 示例: 计算各个地区分别有多少订单,可以通过COUNT([订单ID]) 对准确订单数进行汇总,然后按 地区维度 进行可视化分析
2.去重计数聚合: COUNTD()
- 用途: 返回组中不同记录的数量,不对 NULL 值计数
- 语法: COUNTD(表达式)
- 示例: COUNTD([销售额])
3.求和聚合: SUM()
- 用途: 返回表达式中所有值的总计。SUM 只能用于数字字段,会忽略 NULL 值
- 语法: SUM(表达式)
- 示例: 假设有订单表,我们想计算销售总额,通过 SUM(销售额)

4.平均聚合: AVG()
- 用途: 返回表达式中所有值的平均值。只能用于数字字段,会忽略 NULL 值
- 语法: AVG(表达式)
- 示例: 假设有订单表,我们想计算平均销售额,通过 AVG(销售额)

5.最大值聚合: MAX()
- 用途: 返回表达式在所有记录中的最大值。只能用于数字、日期、日期时间字段
- 语法: MAX(表达式)
- 示例: 计算每月最高销售额,MAX([销售额])

6.最小值聚合: MIN()
- 用途: 返回表达式在所有记录中的最小值。只能用于数字、日期、日期时间字段
- 语法: MIN(表达式)
- 示例: 计算每月最小销售额,MAX([销售额])

7.中位聚合: MEDIAN()
- 用途: 返回表达式中所有值的中位数。MEDIAN 只能用于数字字段
- 语法: MEDIAN(表达式)
- 示例: MEDIAN([利润])
8.百分位聚合: PERCENTILE()
- 用途: 返回表达式中所有值的百分位数。PERCENTILE 只能用于数字字段
- 语法: PERCENTILE(表达式, 百分位)
- 示例: PERCENTILE([利润], 75)
9.属性值: ATTR()
- 用途: 如果给定表达式对于组中的所有行仅具有单个相同值,则返回该表达式的值,否则返回Null
- 语法: ATTR(表达式)
- 示例: ATTR("ab") = "ab"; ATTR([field])
10.GROUP_CONCAT_DISTINCT表达式
- 用途: 返回表达式中所有值的去重拼接结果
- 语法: GROUP_CONCAT_DISTINCT(表达式, 分隔符)
- 示例: GROUPCONCAT_DISTINCT([地区], "") = "东北_中南"
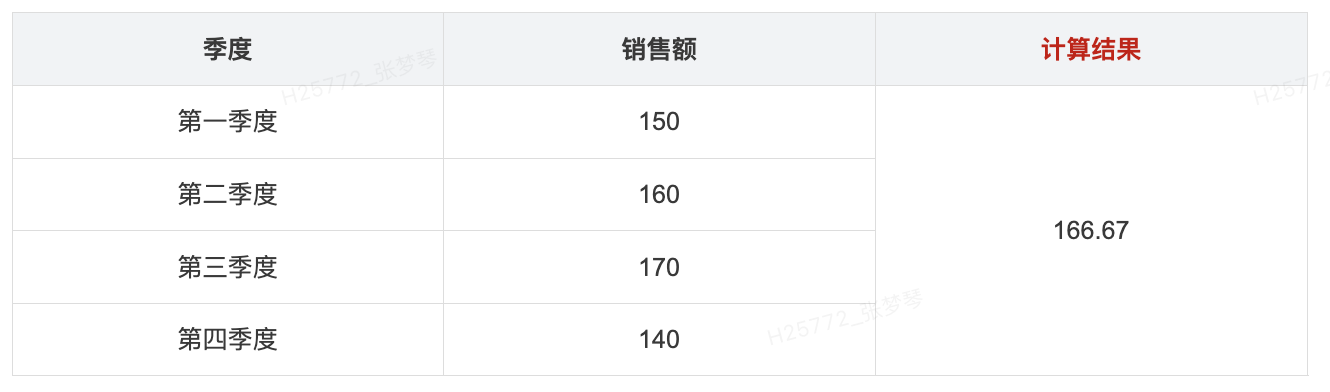
11.样本方差: VAR()
- 用途: 基于群体样本返回给定表达式中所有值的统计方差。方差是一种统计指标,用于度量数据集中每个值与平均值之间的差异程度。通过计算方差,可以了解数据的波动情况,方差数值越大,表示数据点离均值的偏离程度越大;方差数值越小,表示数据点离均值的偏离程度越小。
- 语法: VAR(表达式)
- 示例: 分析销售数据的波动,通过表达式 VAR([销售额])
- 计算过程: 均值=155; 样本方差= ((150-155)^2+(160-155)^2+(170-155)^2+(140-155)^2) / 3 = 166.67
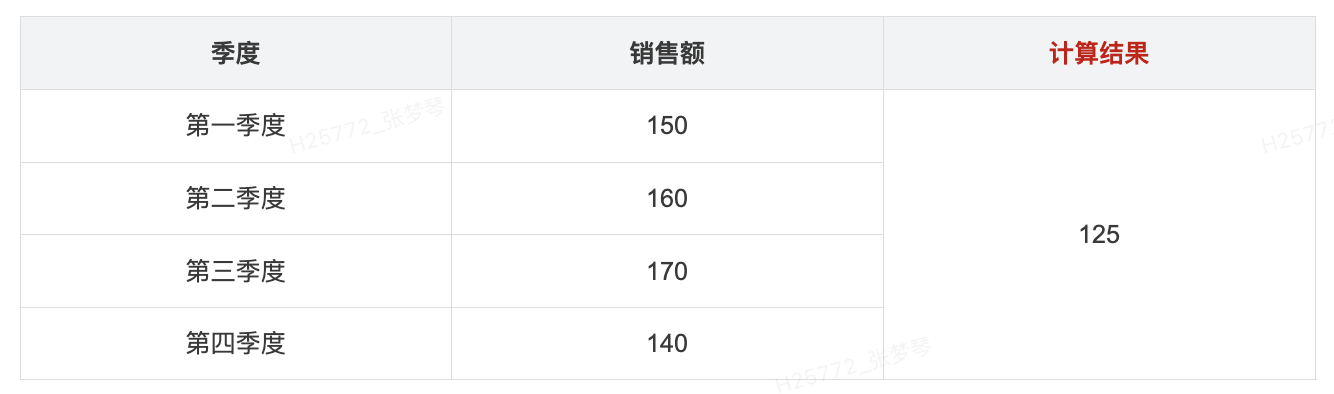
12.总体方差: VARP()
- 用途: 对整个群体返回给定表达式中所有值的统计方差
- 语法: VARP(表达式)
- 示例: 分析销售数据的波动,通过表达式 VARP([销售额])
- 计算过程: 均值=155; 总体方差= ((150-155)^2+(160-155)^2+(170-155)^2+(140-155)^2) / 4 = 125
- 季度销售额计算结果
13.样本标准差: STDEV(表达式)
- 用途: 基于群体样本返回给定表达式中所有值的统计标准差。标准差是一种统计指标,用于度量数据集中每个值与平均值之间的差异程度。标准差反映了数据的离散程度,数值越大,说明数据分布越分散;数值越小,说明数据分布越集中。
- 语法: STDEV(表达式)
- 示例: 在一个销售数据表中,我们希望了解某产品在不同季度的销售额波动情况,通过 STDEV([销售额]),同理上述销售数据可得样本标准差为12.91
14.总体标准差: STDEVP(表达式)
- 用途: 基于有偏差群体返回给定表达式中所有值的统计标准差
- 语法: STDEVP(表达式)
- 示例: 通过 STDEVP([销售额]),同理上述销售数据可得样本标准差为11.18
15.FIXED表达式
- 用途: 实现分组聚合
- 语法: { FIXED [维度1], [维度2]: 聚合表达式 }, 仅使用FIXED表达式中指定的维度和聚合方式来计算
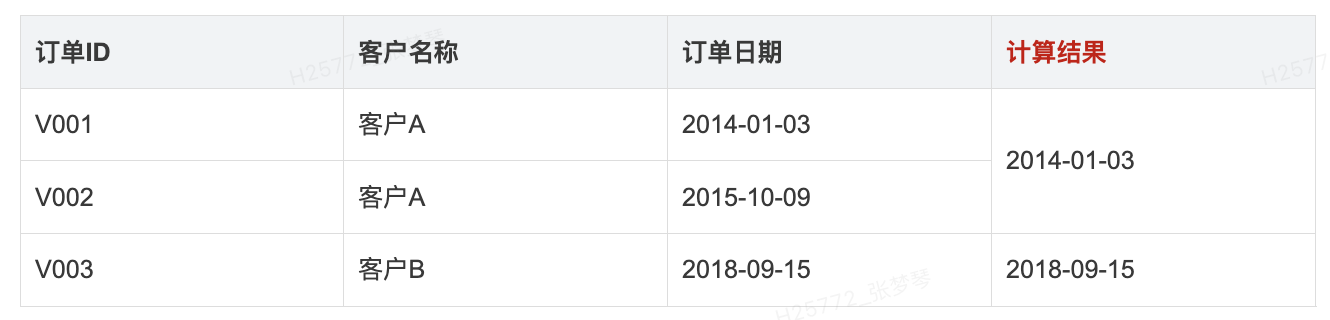
- 示例1:
- 假设有订单表如下,获取每个客户第一次购买日期,通过 { FIXED [客户名称] : MIN([订单日期]) }
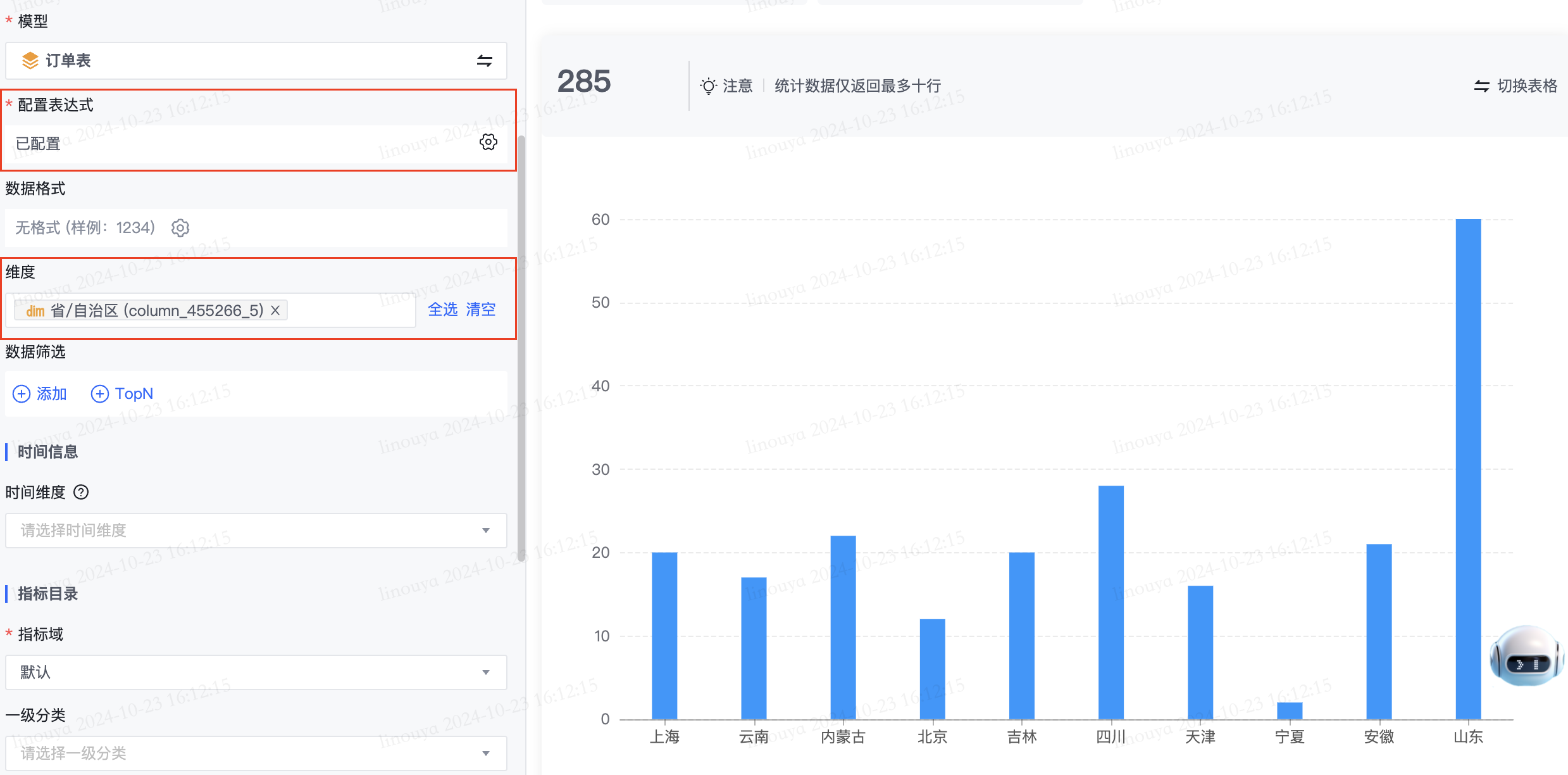
- 示例2:
- 通常使用 FIXED 进行二次聚合,例如计算每个地区重复购买客户数目,通过表达式 SUM(IF {FIXED [客户名称] : COUNTD([订单ID])} >=2 THEN 1 ELSE 0),配置查询维度 [地区]:
- 示例3:
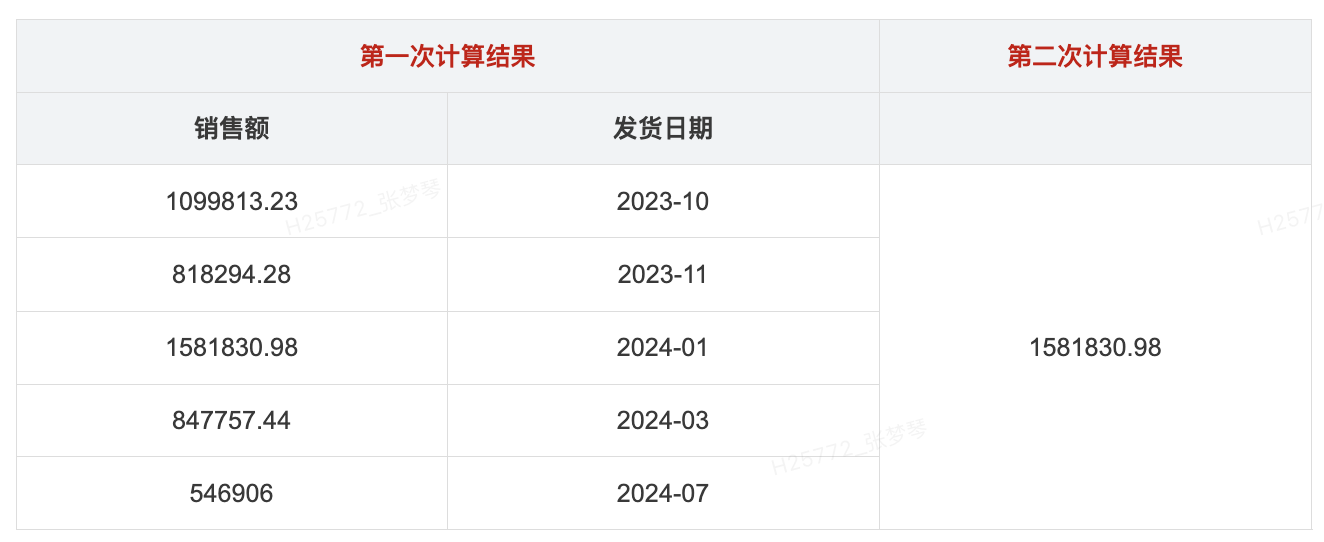
- 计算每个地区销售额最高的月份: MAX({ FIXED MONTH([发货日期]): SUM([销售额]) })
- 首先根据发货日期月份分组聚合: { FIXED MONTH([发货日期]): SUM([销售额]) }
- 然后通过MAX(), 对前面聚合后的结果进行二次计算
16.EXCLUDE表达式
- 用途: 如果指定的维度出现在视图中,则在计算聚合时会排除这些维度
- 语法: { EXCLUDE [维度1], [维度2]...] : 聚合表达式 }
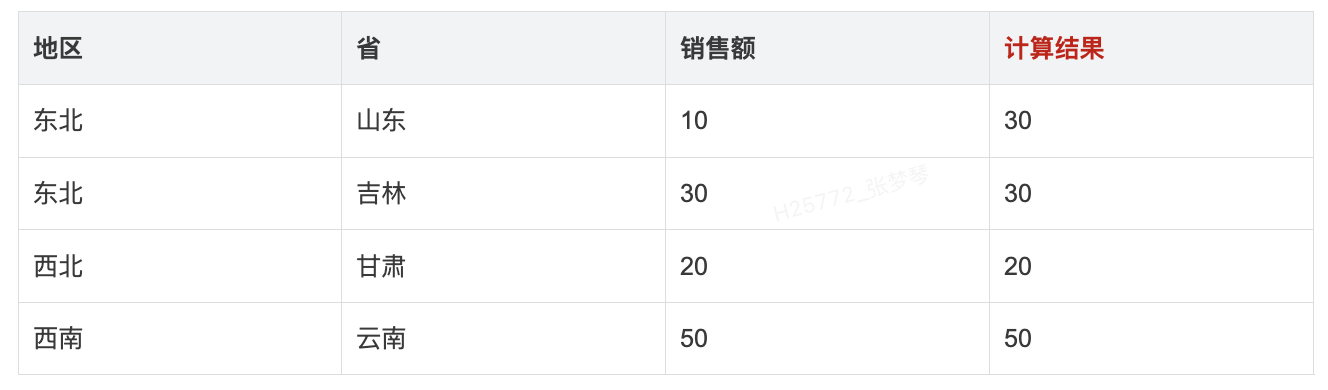
- 使用场景: 一般使用于存在多个分析维度的场景下,假设有订单表,希望在计算销售额求和的时候,例如地区、省份、SUM(销售额),但是如果希望能看到每个地区的最大销售额,可以通过该表达式EXCLUDE省份,只在地区维度下求,通过 { EXCLUDE [省] :SUM([销售额]) }
逻辑函数
通过逻辑函数您可以确定某个特定条件为真还是假(布尔逻辑),经常用于处理数据筛选等场景
1.IF 条件
- 用途: 测试一系列表达式,同时为第一个为 true 的返回值
- 语法: IF 条件 THEN 返回值1 ELSE 返回值2
- 示例:
- 简单用法:IF [销售额] > 100 THEN "优" ELSE "差"
- 嵌套用法:IF [销售额] > 100 THEN "优" ELSE IF [销售额] > 50 THEN "良" ELSE "差"
结合指标具体场景分析,您可能想要知道每个地区的亏损销售额,可以通过 IF THEN 表达式,过滤出部分数据,再结合SUM聚合函数计算。通过 SUM(IF [利润] < 0 THEN [销售额] ELSE 0)
2.IIF 条件
- 用途: 检查某个条件是否得到满足,如果为 TRUE 则返回值1,如果为 FALSE 则返回值2,如果值2不填写,则会返回NULL
- 语法: IIF(条件, 返回值1, 返回值2)
- 示例:
- IIF([利润] > 0, 盈利, 亏损)
- IIF([利润] > 0, 盈利)
结合指标具体场景分析,您可能希望知道每个地区多少产品销售额低于阈值,可以通过 COUNT(IIF([销售额] < 10000, 1, 0))
3.CASE条件
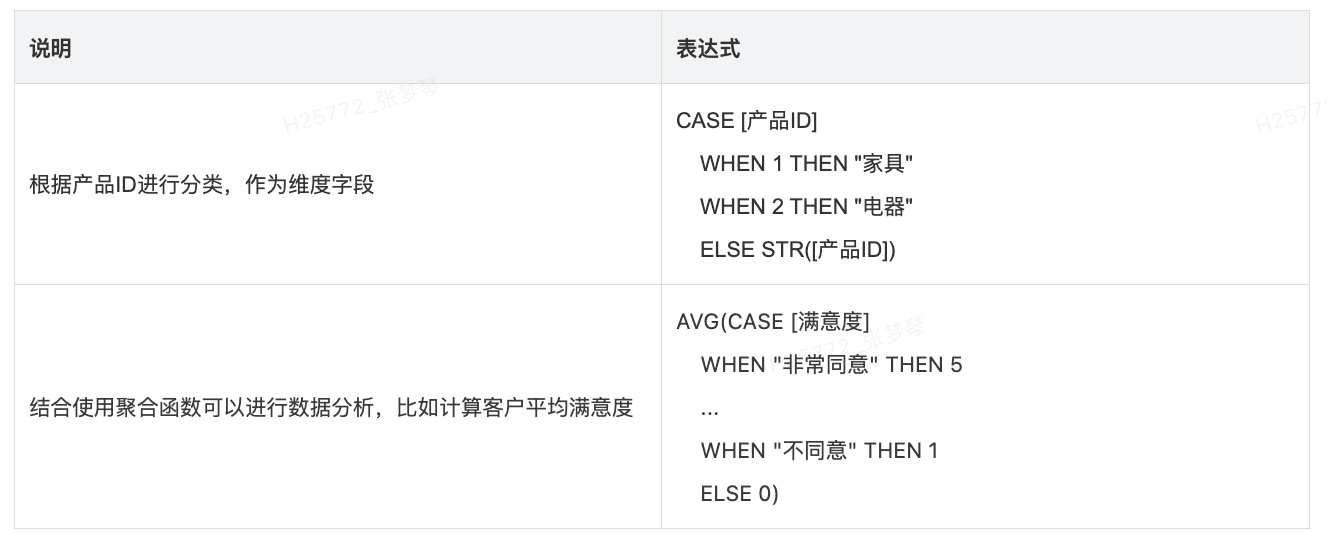
- 用途: 执行逻辑测试并返回相应的值。CASE 函数可评估表达式,并将其与一系列值(值1、值2等)比较,然后返回结果。遇到一个与表达式匹配的值时,CASE返回相应的返回值。如果未找到匹配值,则使用默认返回表达式。如果不存在默认返回表达式并且没有任何值匹配,则会返回 Null。
- 语法: CASE 表达式 WHEN 值1 THEN 返回值1 ... [ELSE 默认返回值]
- 示例:
4.比较运算
- 用途: 比较两个表达式,返回布尔值,可用的比较符有等于(=)、不等于(!=)、大于(>)、小于(<)、大于等于(>=)、小于等于(<=)
- 语法: 表达式1 比较符 表达式2
- 示例: [销售额] >= 8000
5.逻辑运算
- 用途: 逻辑与(AND), 或(OR), 非(NOT) 运算
- 语法: 布尔值1 AND 布尔值2; 布尔值1 OR 布尔值2; NOT 布尔值
- 示例: 假设在一个销售数据表中,我们想筛选出所有非 "东部" 地区的销售记录。如果地区信息存储在名为 [地区] 的字段中,可以使用表达式 NOT [地区] = "东部"

6.最大值比较: MAXIMUM()
- 用途: 对同一类型的表达式进行比较,返回两个或多个表达式对于每个记录的最大值。支持数值型、日期型、字符串
- 语法: MAXIMUM(表达式1, 表达式2, ...)
- 示例: MAXIMUM([销售额], [数量]) = 1000556
7.最小值比较: MINIMUM()
- 用途: 对同一类型的表达式进行比较,返回两个或多个表达式对于每个记录的最小值。支持数值型、日期型、字符串
- 语法: MINIMUM(表达式1, 表达式2, ...)
- 示例: MINIMUM(1, 2) = 1
8.是否空: IFNULL()
- 用途: 判断表达式1是否为空, 否则返回表达式2
- 语法: IFNULL(表达式1, 表达式2)
- 示例: IFNULL([field], 0)
9.若空为零: ZN()
- 用途: 判断表达式是否为空,如果为空则返回0
- 语法: ZN(表达式)
- 示例: ZN(1) = 1
10.空值判断: ISNULL()
- 用途: 判断表达式是否为空
- 语法: ISNULL(表达式)
- 示例: IF ISNULL([用户名]) THEN "匿名用户" ELSE [用户名]
日期函数
我们在对日期型数据进行操作时,经常会遇到要获取当前日期、获取当前时间、获取日期的年月日等操作。
1.日期部分:DATEPART()
- 用途: 用于计算日期/时间的单独部分,比如年、月、日、小时、分钟等等。
- 语法: DATEPART(日期部分,日期型表达式)。其中[日期部分]参数可以是下列的值: "year", "quarter", "month", "week", "day" , "dayofweek", "hour", "minute", "second"
- 示例: 假设有订单表,我们想计算发货日期是在几月份时,可在计算字段的表达式输入框中输入: DATEPART("month", [发货日期])

然后可以结合指标具体场景分析,例如计算今年的销售额: SUM(IF DATEPART("year", [发货日期]) = 2024 THEN [销售额])
2.日期截断:DATETRUNC()
- 用途: 按 [日期部分] 指定的准确度截断指定日期,生成新日期。
- 语法: DATETRUNC(日期部分,日期型表达式)。其中[日期部分]参数是可选的,包括: "year", "quarter", "month", "day" , "hour", "minute", "second"
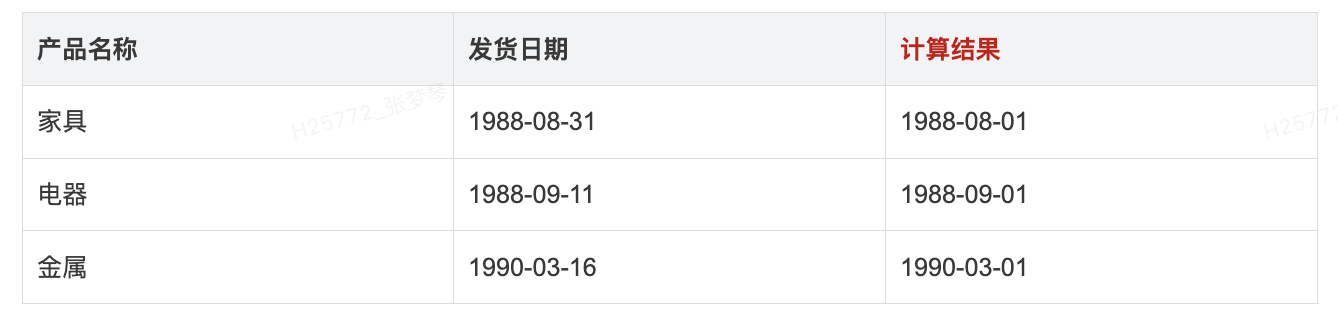
- 示例: 假设有订单表,我们想“发货日期”以月份的形式截断时,此函数 DATETRUNC("month",[发货日期])将返回到当月的第一天。
3.日期加法:DATEADD()
- 用途: 在日期中添加或减去指定的时间间隔
- 语法: DATEADD(日期部分,整数,日期型表达式)
- 日期型表达式: 是合法的日期字段
- 整数: 是希望添加的间隔数,对于未来的时间,此数是正数,对于过去的时间,此数是负数
- 日期部分: "year", "quarter", "month", "day" , "hour", "minute", "second"
- 示例:假设有订单表,如果想查看 [订单日期] 前一个月的相关信息,可以通过表达式 DATEADD("month",1, [订单日期])

4.日期减法:DATEDIFF()
- 用途: 计算两个日期之间的时间差值
- 语法:DATEDIFF(日期部分,开始日期,结束日期)
- 开始时间和结束时间: 合法的日期表达式
- 日期部分: "year", "quarter", "month", "week", "day" , "hour", "minute", "second"
- 示例:假设有订单表,如果想计算[发货日期]及[订单日期]之间的间隔天数或间隔月份,通过DATEDIFF("DAY",[订单日期],[发货日期])

然后可以结合指标具体场景分析,例如计算下单超过3天才发货的订单总数: SUM(IIF(DATEDIFF("DAY",[订单日期],[发货日期]) > 3, 1, 0))
5.日期天数/月/年
- 用途: 以整数形式返回给定日期的天,月份,年份
- 语法: DAY(日期), MONTH(日期), YEAR(日期)
- 示例: 假设有订单表,我们想查看 "订单日期" 中的天数时,通过 DAY([订单日期])

计算函数
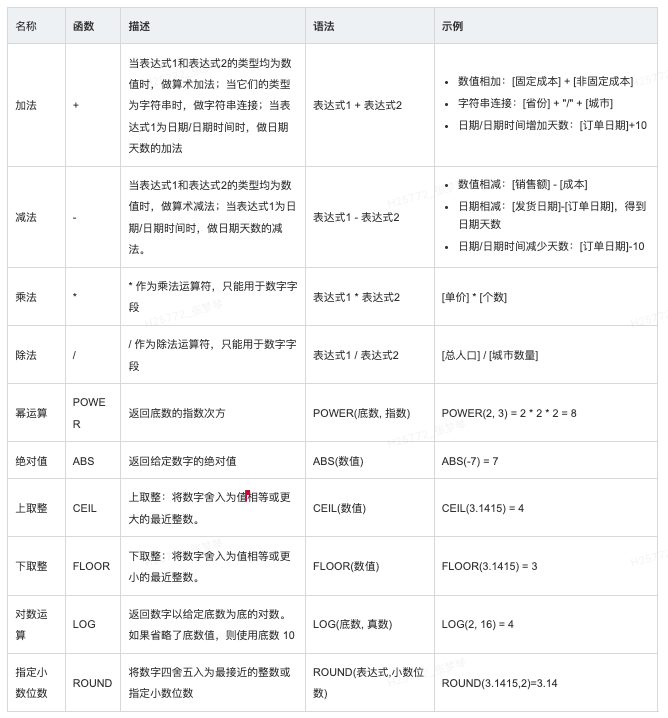
数值函数
数值函数允许您对字段中的数据值执行运算。字段函数只能用于包含数字值的字段
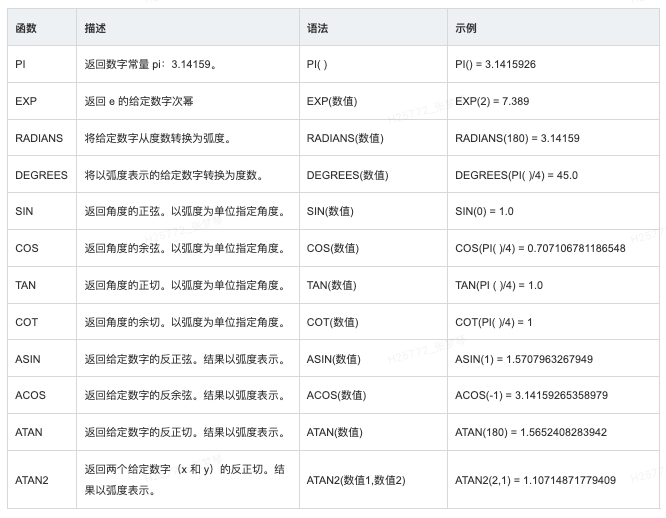
字符串函数
通过字符串函数您可以操作字符串数据,即由文本组成的数据
1.SPLIT函数
- 用途: 从字符串中取到指定位置的子字符串
- 语法: SPLIT(字符串,分隔符,位数)
- 位数: 仅能为整数,不可以为零。正数为从左向右计算,负数为从右向左计算,第一个字符串为1(-1)
- 示例: 从目录中获取某个层级目录地址

2.截取字符串: SUBSTR()
- 用途: 从开始位置(字符串从1开始计数)截取指定长度的字符串返回,长度为可选参数,不给则默认截取到字符串尾部
- 语法: SUBSTR(字符串, 开始位置, [长度])
- 示例: 假设在订单表中,提取每个订单前3位标识符,通过 SUBSTR("abc123", 1, 3) = "abc"
3.字符串长度: LENGTH()
- 用途: 返回给定字符串中的字符数
- 语法: LENGTH(字符串)
- 示例: LENGTH("abc123") = 6
4.替换字符串: REPLACE()
- 用途: 返回一个字符串,在该字符串中,子字符串的每次出现都会替换为替换字符串。字串和替换串必须为常量字符串,如果未找到子字符串,则字符串保持不变
- 语法: REPLACE(字符串, 子串, 替换串)
- 示例: REPLACE("Calculation", "ion", "ed") = "Calculated" 或者 REPLACE([日期], "-", "")
5.字符串转大写: UPPER()
- 用途: 将文本字符串转换为全大写字母
- 语法: UPPER(字符串)
- 示例: UPPER("product") = "PRODUCT"
6.字符串转小写: LOWER()
- 用途: 将文本字符串转换为全小写字母
- 语法: LOWER(字符串)
- 示例: LOWER("PRODUCT") = "product"
7.字符串转小写: LTRIM()
- 用途: 返回移除了所有前导空格的字符串
- 语法: LTRIM(字符串)
- 示例: LTRIM(" Sales") = "Sales"
8.包含: CONTAINS()
- 用途: 如果给定字符串包含指定子字符串,则返回 true。 如果给定字符串不包含指定子字符串,则返回 false
- 语法: CONTAINS(字符串, 子串)
- 示例: 检查产品描述是否包含特定关键词
假设在一个产品数据表中,产品描述存储在名为 [产品名称] 字段中。我们希望检查产品描述是否包含关键词 "Pro",可以使用如下表达式: CONTAINS(产品名称, "Pro")

9.结尾包含: ENDSWITH()
- 用途: 如果给定字符串以指定子字符串结尾,则返回 true
- 语法: ENDSWITH(字符串, 子串)
- 示例: 筛选以特定后缀结尾的产品名称
假设在一个产品数据表中,产品描述存储在名为 [产品名称] 字段中。我们希望筛选出以 "Pro" 结尾的产品名称,可以使用如下表达式: ENDSWITH(产品名称, "Pro")

10.开头包含: STARTSWITH()
- 用途: 如果给定字符串以指定子字符串开头,则返回 true
- 语法: STARTSWITH(字符串, 子串)
- 示例: 筛选以特定前缀开头的产品名称
假设在一个产品数据表中,产品描述存储在名为 [产品名称] 字段中。我们希望筛选出以 "Galaxy" 开头的产品名称,可以使用如下表达式: STARTSWITH(产品名称, "Pro")

11.开头截取: LEFT()
- 用途: 返回给定字符串开头的指定字符数
- 语法: LEFT(字符串, 整数)
- 示例: LEFT("Calculation", 4) = "Calc"
12.结尾截取: RIGHT()
- 用途: 从给定字符串结尾起返回指定数量的字符
- 语法: RIGHT(字符串, 整数)
- 示例: RIGHT("Calculation", 4) = "tion"
13.移除前导空格: LTRIM()
- 用途: 返回移除了所有前导空格的字符串
- 语法: LTRIM(字符串)
- 示例: LTRIM(" Sales") = "Sales"
14.移除尾随空格: RTRIM()
- 用途: 返回移除了所有尾随空格的字符串
- 语法: RTRIM(字符串)
- 示例: RTRIM("Market ") = "Market"
15.移除前后空格: TRIM()
- 用途: 返回移除了所有前导空格和尾随空格的字符串
- 语法: TRIM(字符串)
- 示例: TRIM(" ab cd ") = "ab cd"
16.查找字串位置: FIND()
- 用途: 返回子字符串在字符串中的位置,如果未找到子字符串,则返回0。起始位置为可选参数,如果给定此参数则从此位置开始查找,字符串中的第一个字符串为位置1
- 语法: FIND(字符串, 子串, [起始位置])
- 示例: FIND("Calculation", "alcu") = 2
17.字符串拼接: CONCAT()
- 用途: 返回将字符串1和字符串2拼接后的字符串
- 语法: CONCAT(字符串1, 字符串2)
- 示例: CONCAT("ab", "cde") = "abcde"
18.正则捕获提取: REGEXP_EXTRACT_NTH()
- 用途: 使用正则表达式模式返回给定字符串的子字符串。子字符串与第n个捕获组匹配,其中模式的每一个括号匹配一个捕获组,其中n为给定索引。
- 语法: REGEXP_EXTRACT_NTH(表达式, 模式, 索引)
- 示例: REGEXP_EXTRACT_NTH("abc 123", "([a-z])+\s+(\d+)", 2) = "123"
19.正则替换
- 用途: 返回给定字符串的副本,其中匹配模式替换为替换字符串
- 语法: REGEXP_REPLACE(字符串, 模式, 被替换串)
- 示例: REGEXP_REPLACE("abc 123", "\s", "-") = "abc--123"
类型转换
通过类型转换函数您可以将字段从一种数据类型转换为另一种数据类型
1.转为日期:DATE()
- 用途: 返回日期或日期/时间表达式的日期部分
- 语法: DATE(表达式)
- 时间戳形式:DATE(1230480000), 返回日期 2008-12-29
- 日期类型: DATE(2017-02-14 10:10:10), 返回日期 2017-02-14
- 日期表达式: DATE([发货日期]), 返回日期 2008-12-29
- 示例: 假设有订单表,我们想了解 [发货日期] 的年月日信息,通过 DATE([发货日期])

2.转为日期时间:DATETIME()
- 用途: 返回日期或日期/时间表达式的日期时间部分
- 语法: DATETIME(表达式)
- 时间戳形式: DATETIME(1487035400), 返回日期时间 2017-02-14 01:23:20
- 日期类型: DATETIME("2017-02-14"), 返回日期时间 2017-02-14 00:00:00
- 日期表达式: DATETIME([订单日期]), 返回日期时间 2017-02-14 17:07:55
- 示例: 假设有订单表,我们想了解 [订单日期] 的年月日,并精确到秒信息,通过DATETIME([订单日期])

3.转换成字符串: STR()
- 用途: 将表达式转换为字符串类型
- 语法: STR(表达式)
- 示例: STR(200) = "200"
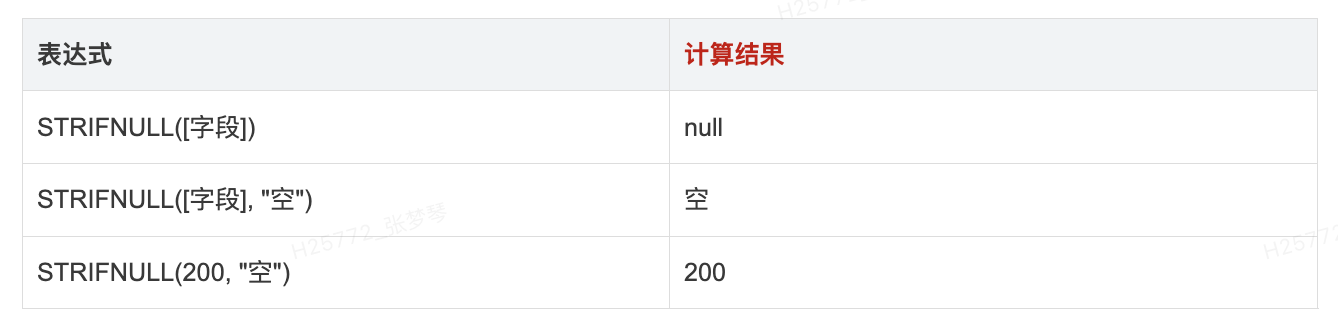
4.转为字符串(若空处理): STRIFNULL()
- 用途: 将表达式1转换为字符串类型。若表达式1为null,则将表达式2转换为字符串类型;若未填写表达式2,则表达式2默认为字符串"null"
- 语法: STRIFNULL(表达式1,表达式2)
- 示例:
5.日期串解析:DATEPARSE()
- 用途: 将字符串转换为指定格式的日期
- 语法: DATEPARSE(格式串, 字符串)
- 格式串: 数据库中日期的类型,例如订单表中[订单日期]格式为[2017-02-14],则格式串类型为[yyyy-mm-dd] (y为年,m为月,d为日),若[发货日期]格式为[03/12 2019],则格式串类型为[mm/dd yyyy]
- 字符串: 想要转换的日期或日期型表达式 (必须为字符串形式)
6.转为浮点数: FLOAT()
- 用途: 在给定任何类型的表达式的情况下返回浮点数
- 语法: FLOAT(表达式)
- 示例: FLOAT("3") = 3.0,FLOAT(2.1) = 2.1
7.转整数: INT()
- 用途: 在给定表达式的情况下返回整数,此函数将结果截断为最接近0的整数
- 语法: INT(表达式)
- 示例: INT(200.6) = 200,INT(-0.6) = 0
8.时长转整数: DURATION_PARSE()
- 用途: 将字符串按指定的时长格式转换为数值
- 语法: DURATION_PARSE(时间单位, 格式串, 字符串)
- 需指定结果单位,格式串中支持的时间单位:dd(天), hh(小时), mi(分钟), ss(秒)
- 示例:
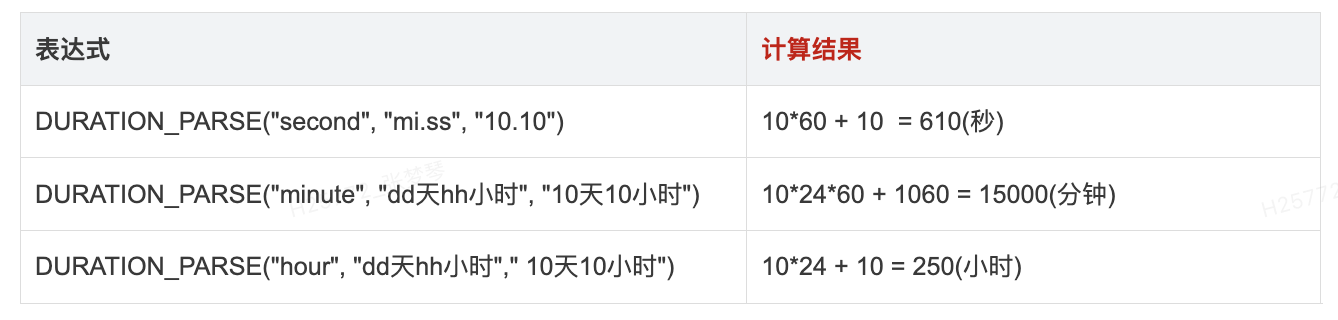
通过该表达式,可以帮助处理数据。例如 AVG(DURATION_PARSE("hour", "dd天hh小时", [发货时长])) 计算平均发货时长
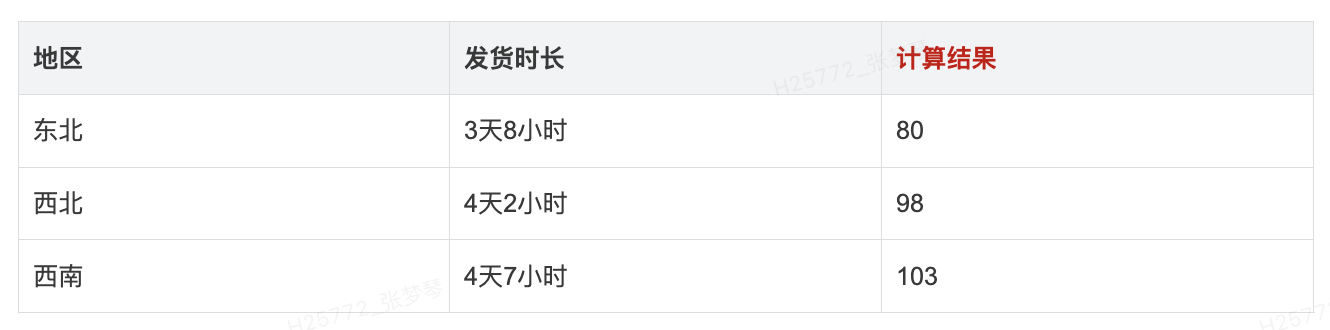
9.日期格式化: DATEFORMAT()
- 用途: 返回将日期或日期时间表达式转换成格式串指定格式的字符串
- 语法: DATEFORMAT(格式串, 日期或日期时间)
- 示例:
- DATEFORMAT("yyyy/mm/dd", [日期]) 表示将[日期]字段转换成格式为"yyyy/mm/dd"的字符串
- DATEFORMAT("yyyy/mm/dd hh:mi:ss", [日期时间]) 表示将[日期时间]字段转换成格式为"yyyy/mm/dd hh:mi:ss"的字符串
窗口函数
1.排名: ROW_NUMBER
- 用途: 返回分区中当前行的排名。为相同的值分配相同的排名,允许并列。使用可选的ASC或者DESC参数指定升序或降序顺序。默认为升序
- 语法: ROW_NUMBER() OVER(PARTITION BY 维度表达式 ORDER BY 度量表达式 [ASC|DESC])
- 使用场景: 获取根据地区分组,销售额求和的排名,通过 ROW_NUMBER() OVER(ORDER BY SUM([销售额]) DESC)

排名函数跟聚合函数结合使用,以实现将排名结果作为维度字段并进行后续分析,例如实现高级筛选,例如销售额前5的地区: ROW_NUMBER() OVER(ORDER BY SUM([销售额]) DESC) <= 5
辅助函数
1.LET IN表达式
- 用途: 允许用户给自定义名字绑定表达式片段,并在LET IN表达式范围内将可以使用该名字来代替绑定的表达式片段
- 语法: LET ... IN ...
- 示例:

直通函数
RAWSQL 直通函数可用于将 SQL 表达式直接发送到数据库,而不由系统进行解析。如果您系统不能识别的自定义数据库函数,则可以使用直通函数调用这些自定义函数。 数据库通常不会理解在本产品中的字段名称。因为本产品不会解释包含在直通函数中的 SQL 表达式,所以在表达式中使用本产品中的字段名称可能会导致错误。可使用替换语法将用于本产品中计算的正确字段名称或表达式插入直通 SQL。
1.直通布尔: RAWSQL_BOOL()
- 用途: 从给定SQL表达式返回布尔结果
- 语法: RAWSQL_BOOL("SQL表达式", [表达式1], [表达式2], ...)
- 示例: RAWSQL_BOOL("IIF(%1 > %2, True, False)" , [销售额] , [利润])%1等于[销售额],%2等于[利润],表示若销售额大于利润时返回布尔结果True,否则为False
2.直通日期: RAWSQL_DATE
- 用途: 从给定SQL表达式返回日期结果
- 语法: RAWSQL_DATE("SQL表达式",[表达式1],[表达式2], ...)
- 示例: RAWSQL_DATE("%1",[Order Date])
3.直通日期时间: RAWSQL_DATETIME()
- 用途: 从给定SQL表达式返回日期和时间结果
- 语法: RAWSQL_DATETIME("SQL表达式", [表达式1], [表达式2],...)
- 示例: RAWSQL_DATETIME("MIN(%1)", [Delivery Date])
4.直通整数: RAWSQL_INT()
- 用途: 从给定SQL表达式返回整数结果
- 语法: RAWSQL_INT(“SQL表达式",[表达式1], [表达式2],...)
- 示例: RAWSQL_INT("500+%1",[销售额])
5.直通小数: RAWSQL_FLOAT()
- 用途: 从给定SQL表达式返回小数结果
- 语法: RAWSQL_FLOAT("SQL表达式", [表达式1], [表达式2], ...)
- 示例: RAWSQL_FLOAT("-123.98*%1", [销售额])