FlinkSQL的一些场景优化
Flink SQL 的一些场景优化
开启MiniBatch
建议使用Flink1.12及更高版本MiniBatch是微批处理,原理是缓存一定的数据后再触发处理,以减少对State的访问,从而提升吞吐并减少数据的输出量。MiniBatch主要依靠在每个Task上注册的Timer线程来触发微批,需要消耗一定的线程调度性能。
适用场景
通常对于聚合的场景,微批处理可以显著的提升系统性能,建议开启。微批处理通过增加延迟换取高吞吐,如果有超低延迟的要求,不建议开启微批处理。
开启方式
在“任务开发“页面使用set 语法进行配置
set 'table.exec.mini-batch.enabled' = 'true';
需要注意的是开启minibatch 后,必须设置缓存大小和允许延迟的间隔时间且值必须大于0,minibatch 需要按照如下策略进行计算触发
set 'table.exec.mini-batch.allow-latency' = '5 s';
set 'table.exec.mini-batch.size' = '3000';如下图: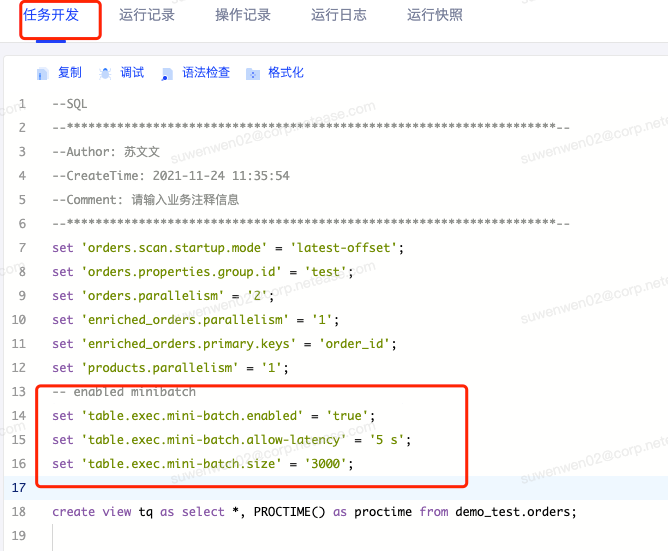
注意在“高级配置”选项卡内配置该参数不会生效。
常见的数据倾斜问题
如何判断作业是否存在数据倾斜问题
访问“任务页面” 在flink web UI 页面展示的JobGraph 可以看到Operator Chain,(如何临时关闭算子链,请参考Flink作业如何进行性能瓶颈分析一章中的“注意” 红色字体内容)单击task 对应的Subtasks可以看到当前subtask的详细信息 如下图所示,各个subtask 接收到的数据量差别比较大时,即作业存在数据倾斜情况。
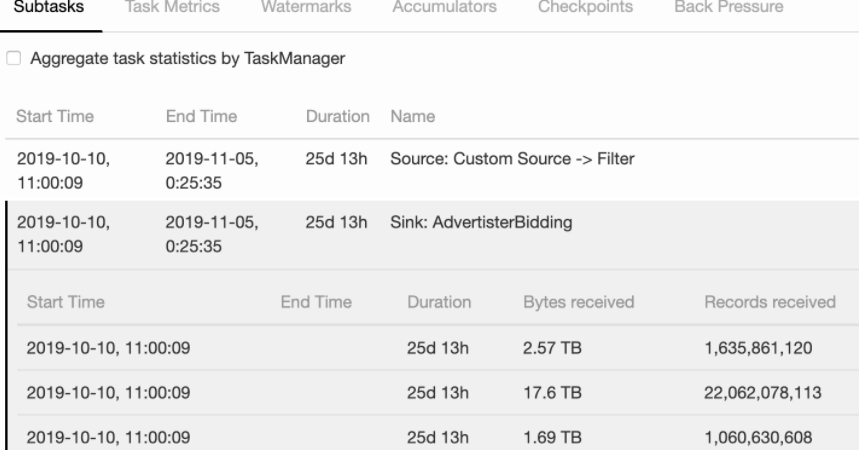
Kafka Topic分区数据存在倾斜
按照上述方式,查看到source kafka 的subtask 存在数据倾斜,即生产者写入kafka topic 的分区数据存在倾斜。此时需要业务源端配合调整写入策略,尽量让数据均匀的落到kafka topic的不同分区。
适用于提升如SUM、COUNT、MAX、MIN和AVG等普通聚合的性能,以及解决这些场景下的数据热点问题
开启LocalGlobal
LocalGlobal优化将原先的Aggregate分成Local+Global两阶段聚合,即MapReduce模型中的Combine+Reduce处理模式。第一阶段在上游节点本地攒一批数据进行聚合(localAgg),并输出这次微批的增量值(Accumulator)。第二阶段再将收到的Accumulator合并(Merge),得到最终的结果(GlobalAgg)。
LocalGlobal本质上能够靠LocalAgg的聚合筛除部分倾斜数据,从而降低GlobalAgg的热点,提升性能。结合下图理解LocalGlobal如何解决数据倾斜的问题。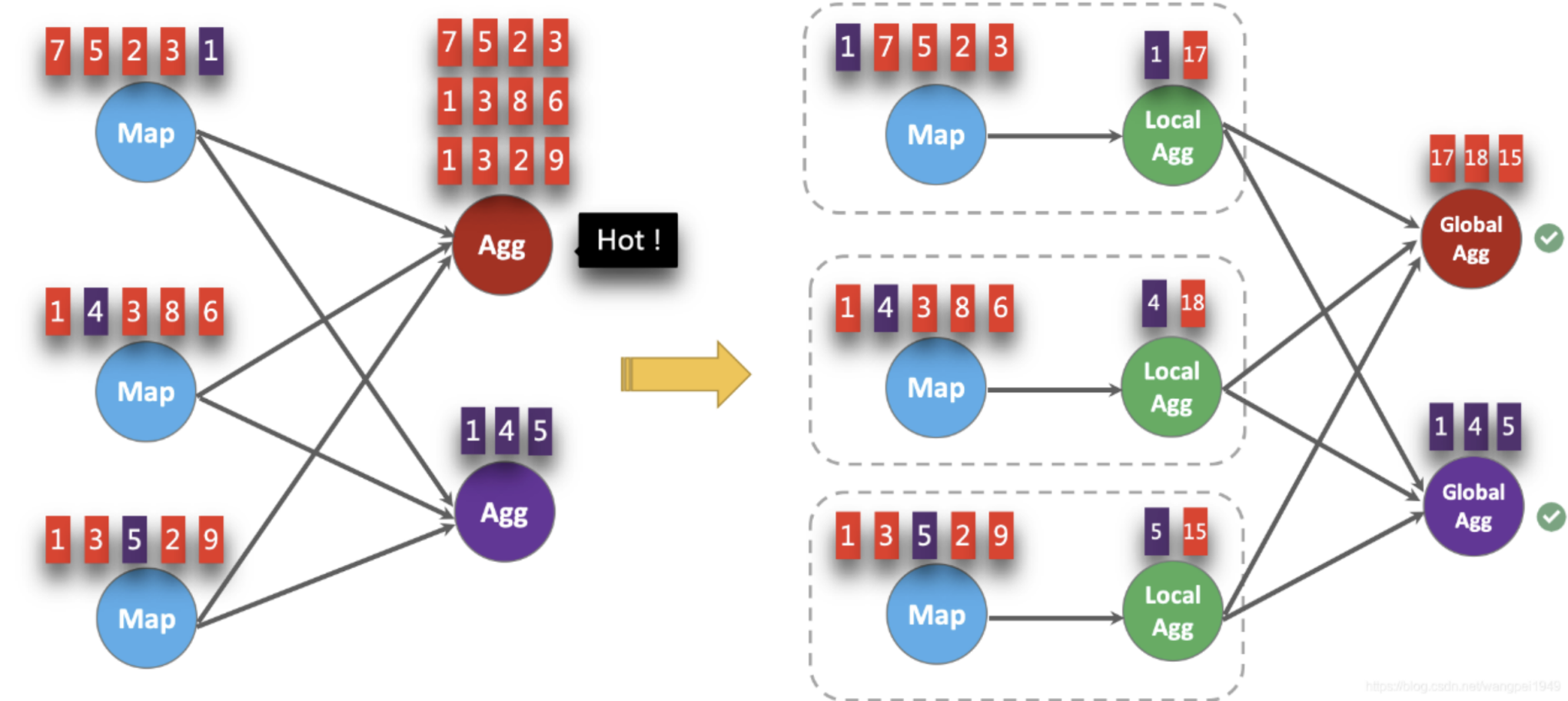
由上图可知:
未开启LocalGlobal优化,由于流中的数据倾斜,Key为红色的聚合算子实例需要处理更多的记录,这就导致了热点问题。
开启LocalGlobal优化后,先进行本地聚合,再进行全局聚合。可大大减少GlobalAgg的热点,提高性能。
开启方式
在”任务开发“使用set 语法进行设置
需要注意一下2点:
1)LocalGlobal优化需要先开启MiniBatch,依赖于MiniBatch的参数。
2)table.optimizer.agg-phase-strategy: 聚合策略。默认AUTO,支持参数AUTO、TWO_PHASE(使用LocalGlobal两阶段聚合)、ONE_PHASE(仅使用Global一阶段聚合)。
另外,如果聚合调用不支持优化为两个阶段,仍将使用一个阶段的聚合。ONE_PHASE:强制使用只有CompleteGlobalAggregate的阶段聚合。
// 开启miniBatch
set 'table.exec.mini-batch.enabled' = 'true';
set 'table.exec.mini-batch.allow-latency' = '5 s';
set 'table.exec.mini-batch.size' = '3000';
// 开启LocalGlobal
set 'table.optimizer.agg-phase-strategy' = 'TWO_PHASE';适用于作业使用了COUNT DISTINCT,但无法满足聚合节点性能要求
开启Split Distinct
LocalGlobal优化针对普通聚合(例如SUM、COUNT、MAX、MIN和AVG)有较好的效果,对于COUNT DISTINCT收效不明显,因为COUNT DISTINCT在Local聚合时,对于DISTINCT KEY的去重率不高,导致在Global节点仍然存在热点。
之前,为了解决COUNT DISTINCT的热点问题,通常需要手动改写为两层聚合(增加按Distinct Key取模的打散层)。
从Flink1.9.0版本开始,提供了COUNT DISTINCT自动打散功能,不需要手动重写。Split Distinct和LocalGlobal的原理对比参见下图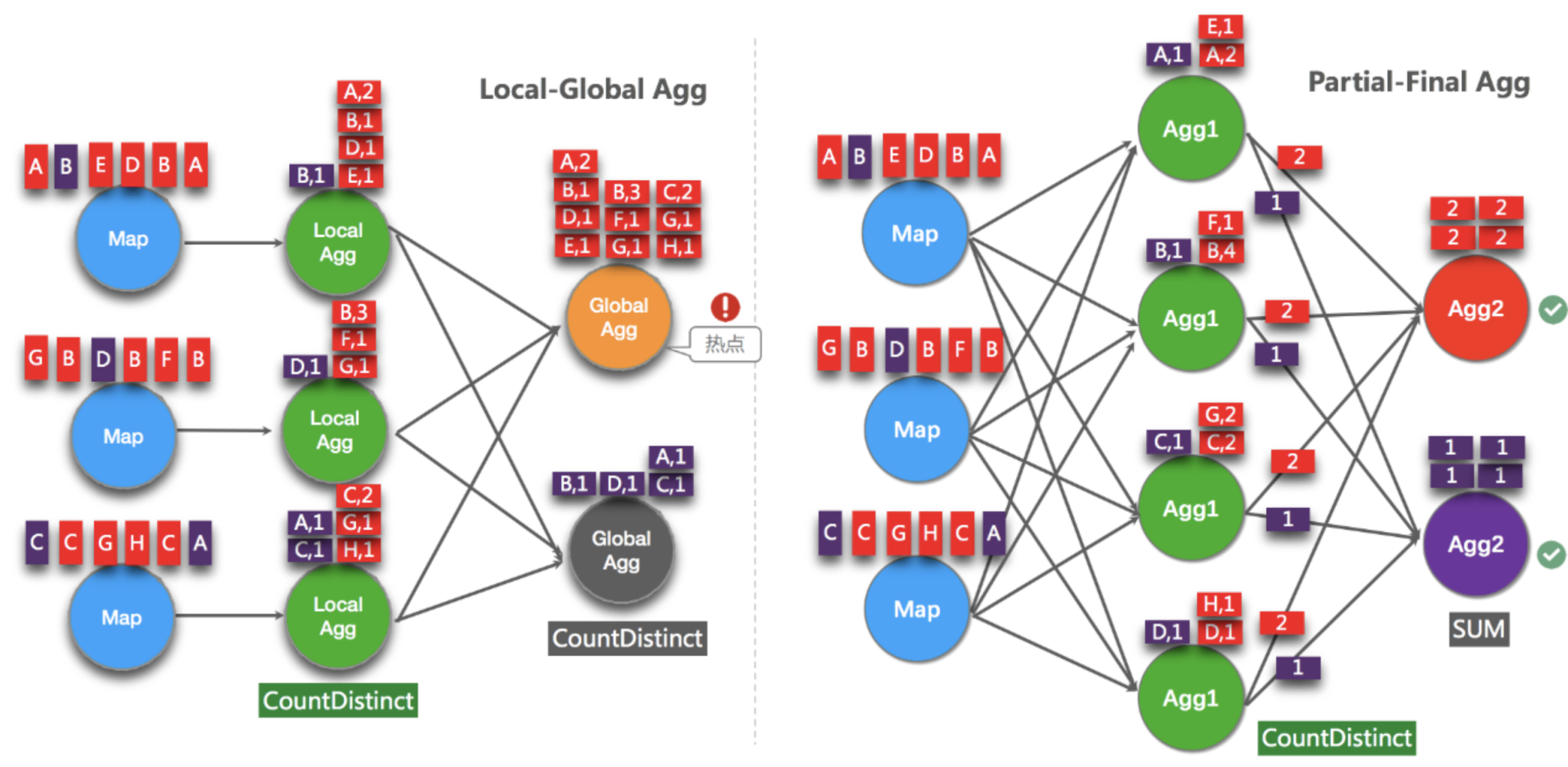
开启方式
在”任务开发“使用set 语法进行设置
默认不开启,使用参数显式开启:
table.optimizer.distinct-agg.split.enabled: true,默认false。
table.optimizer.distinct-agg.split.bucket-num: Split Distinct优化在第一层聚合中,被打散的bucket数目。默认1024。
// 设置参数:
// 开启Split Distinct
set 'table.optimizer.distinct-agg.split.enabled' = 'true';
// 第一层打散的bucket数目
set 'table.optimizer.distinct-agg.split.bucket-num' = '1024');
需要注意的是
1)目前不能在包含UDAF的Flink SQL中使用Split Distinct优化方法。
2)拆分出来的两个GROUP聚合还可参与LocalGlobal优化。
3)从Flink1.9.0版本开始,提供了COUNT DISTINCT自动打散功能,不需要手动重写
手动重写两阶段聚合案例
比如统计一天UV sql如下:
SELECT day, COUNT(DISTINCT user_id)
FROM T
GROUP BY day
两阶段聚合写法:
SELECT day, SUM(cnt)
FROM (
SELECT day, COUNT(DISTINCT user_id) as cnt
FROM T
GROUP BY day, MOD(HASH_CODE(user_id), 1024)
)
GROUP BY day判断是否生效,在webui的JobGraph 中查看是否包含Expand节点,或者原来一层的聚合变成了两层的聚合,这需要临时关闭算子链。
数据去重方案优化
由于SQL上没有直接支持去重的语法,还要灵活的保留第一条或保留最后一条。因此我们使用了SQL的ROW_NUMBER over Window功能来实现去重语法。去重本质上是一种特殊的TopN。
- 保留首行的去重策略
保留key下第一条出现的数据,之后出现该key下的数据会被丢弃掉。因为STATE中只存储了key数据,所以性能较优,示例如下:
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY b ORDER BY proctime) as rowNum
FROM T
)
WHERE rowNum = 1;以上示例是将T表按照b字段进行去重,并按照系统时间保留第一条数据。Proctime在这里是源表T中的一个具有Processing Time属性的字段。如果按照系统时间去重,也可以将Proctime字段简化PROCTIME()函数调用,可以省略Proctime字段的声明。
- 保留末行的去重策略
保留key下最后一条出现的数据。保留末行的去重策略性能略优于LAST_VALUE函数,示例如下:
以上示例是将T表按照b和d字段进行去重,并按照业务时间保留最后一条数据。Rowtime在这里是源表T中的一个具有Event Time属性的字段。SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY b, d ORDER BY rowtime DESC) as rowNum FROM T ) WHERE rowNum = 1;
TopN 数据输出膨胀问题
TopN 语法如下:
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER ([PARTITION BY col1[, col2..]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]数据膨胀问题
根据TopN的语法,rownum字段会作为结果表的主键字段之一写入结果表。但是这可能导致数据膨胀的问题。例如,收到一条原排名为9的更新数据,更新后排名上升到1,从1到9的排名数据都发生变化,需要将这些数据作为更新数据都写入结果表。这样就产生了数据膨胀,导致结果表因为收到太多的数据而降低了更新速率。
使用方式
TopN的输出结果无需要显示rownum值,仅需在最终前端显式时进行1次排序,极大地减少输入结果表的数据量。只需要在外层查询中将rownum字段裁剪掉即可
// 最外层的字段,不写 rownum
SELECT col1, col2, col3
FROM (
SELECT col1, col2, col3
ROW_NUMBER() OVER ([PARTITION BY col1[, col2..]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]在无rownum的场景中,对于结果表主键的定义需要特别小心。如果定义有误,会直接导致TopN结果的不正确。 无rownum场景中,主键应为TopN上游group by节点的key列表。
TopN 性能优化(实验项)
TopN为了提升性能有一个State Cache层,Cache层能提升对State的访问效率。TopN的Cache命中率的计算公式为。
cache_hit = cache_size*parallelism/top_n/partition_key_num例如,TopN配置缓存10000条,并发50,当PatitionBy的key维度较大时,例如10万级别时,Cache命中率只有10000*50/100/100000=5%,命中率会很低,导致大量的请求都会击中State(磁盘),性能会大幅下降。因此当PartitionKey维度特别大时,可以适当加大TopN的CacheSize,相对应的也建议适当加大TopN节点的Heap Memory。
配置方式,在任务"高级配置"中引入 table.exec.topn.cache-size 200000
需要注意的是目前源码中标为实验项,官网中未列出该参数。
使用内置函数替换自定义函数
Flink 的内置函数在持续的优化当中,请尽量使用内部函数替换自定义函数。使用内置函数的好处:
1)优化数据序列化和反序列化的耗时。
2)新增直接对字节单位进行操作的功能。
支持的系统内置函数:请参考官方手册
使用LIKE 操作的注意事项
如果需要进行匹配开始字符操作,使用LIKE 'xxx%'。
如果需要进行匹配结束字符操作,使用LIKE '%xxx'。
如果需要进行匹配子串操作,使用LIKE '%xxx%'。
如果需要进行等价判断操作,使用LIKE 'xxx',等价于str = 'xxx'。
如果需要匹配 字符,请注意要完成转义 LIKE '%seller/id%' ESCAPE '/' 在SQL中属于单字符通配符,能匹配任何字符。如果声明为 LIKE '%seller_id%',则不单会匹配seller_id还会匹配seller#id、sellerxid或seller1id 等,导致结果错误。
慎重使用正则函数
正则表达式是非常耗时的操作,对比加减乘除通常有百倍的性能开销,而且正则表达式在某些极端情况下可能会进入无限循环,导致作业阻塞。建议使用LIKE。正则函数包括:
REGEXP
REGEXP_EXTRACT
REGEXP_REPLACE